






Elasticsearch(简称es)是一个搜索引擎,其实也可以理解为一个数据库,因为也是需要把数据放入进es里面,进行倒排索引之后,再进行正向索引。
正向索引:
也就是我们日常再mysql里面建立索引的时候,经常使用到的操作。
倒排索引:
通过分词器来对文字进行分词拆分,然后形成一个索引表。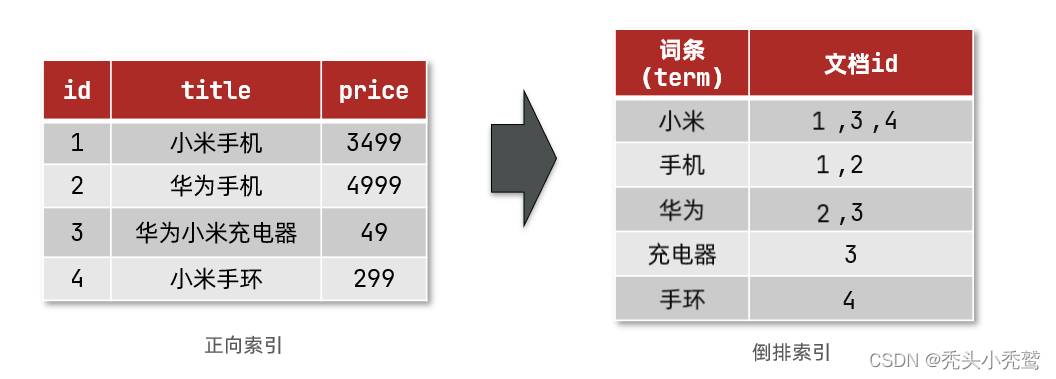
然后在通过查询的词汇与词条进行查询,得到id值之后,因为id值是主键。所以就使用正向索引,来获取对应得数据。
分词器:
对于搜索文本进行分词规范的标准文档。引入分词器也就是给es添加规定条件,方便进行倒排索引。
安装:
1.在线安装ik插件:
(1)、进入es容器内部。进入目录/bin/bash
(2)、进入容器内部之后,执行安装语句:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
(3)、退出容器。然后重启es。
注意:用在线下载ik分词器的时候,此时ik的config文件就不在/usr/share/elasticsearch/data里面了

而是在config里面
![]()
查看(验证):
通过在kibana页面上面。执行请求:

当然get与post都可以。只是对应的操作不同而已。
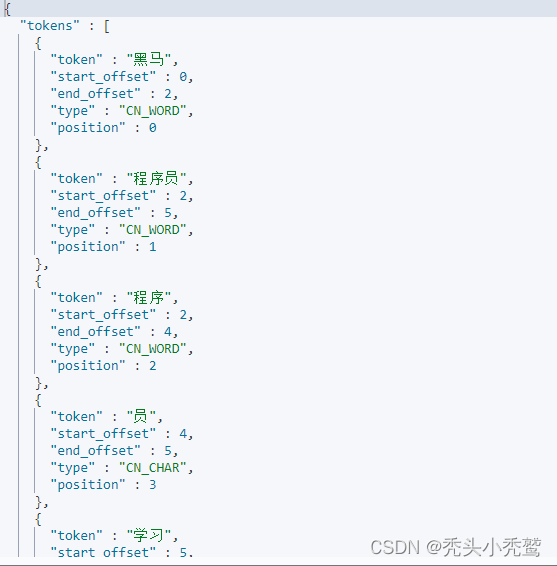
得出的分词效果如下:
拓展:
因为现在我们对应的分词器只是很少一部分进行了分词。当我们想对我们自己定义的词汇进行分词的时候,就分词不了,譬如“奥利给”,因为分词器此时无法判断这是一个词汇,就会逐个单词进行分词。

所以,我们需要添加这个词汇进去,这里就涉及到扩展的状态了。
因为我们容器挂载了数据卷。所以我们需要只需要修改本地的文件,然后重启启动容器即可。
(1)、查看当前es的挂载卷:docker inspect 容器名
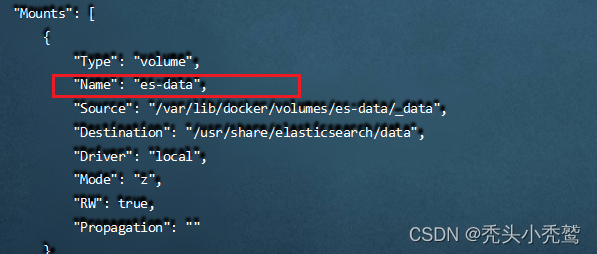
第一个挂载卷:es-data(这个是es的数据存放位置)
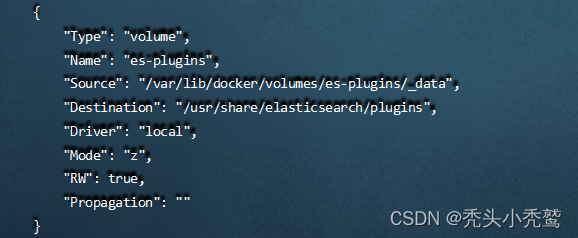
第二个挂载卷:es-plugins(设置配置文件)
(2)、查看该数据卷挂载在宿主机那个位置:docker volume inspect 数据卷名
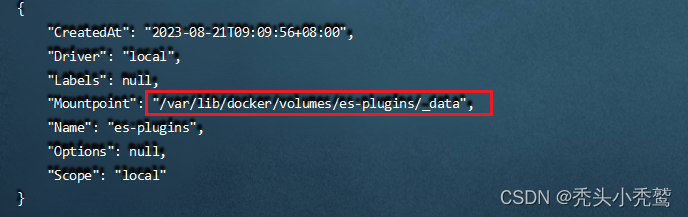
查看到在当前文件:/var/lib/docker/volumes/es-plugins/_data
(3)、打开ik文件夹里面的config目录,也就是分词配置设置目录
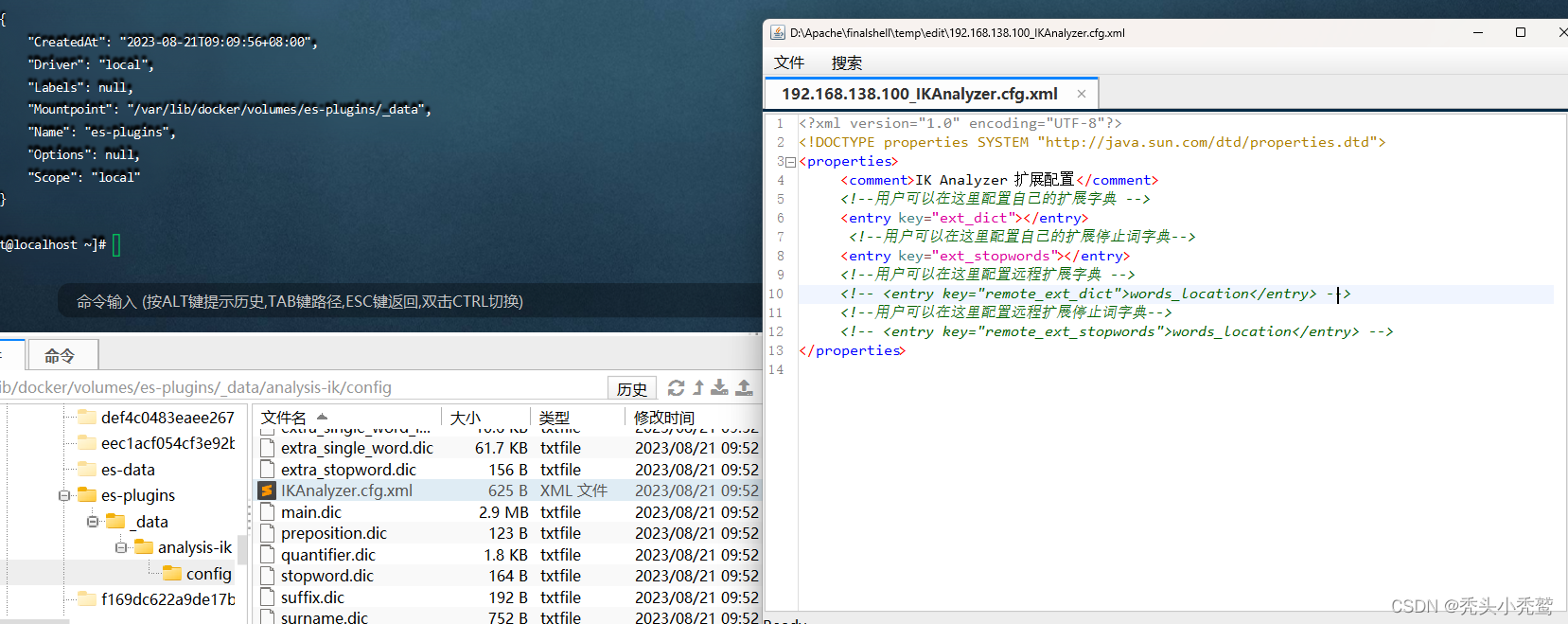
这是是设置配置文件,还没有设置那些词汇需要添加。
(4)、创建ext.dic文件,然后进行数据填写。

然后在config文件里面进行添加。

(5)、重启容器,然后再次执行查看效果。

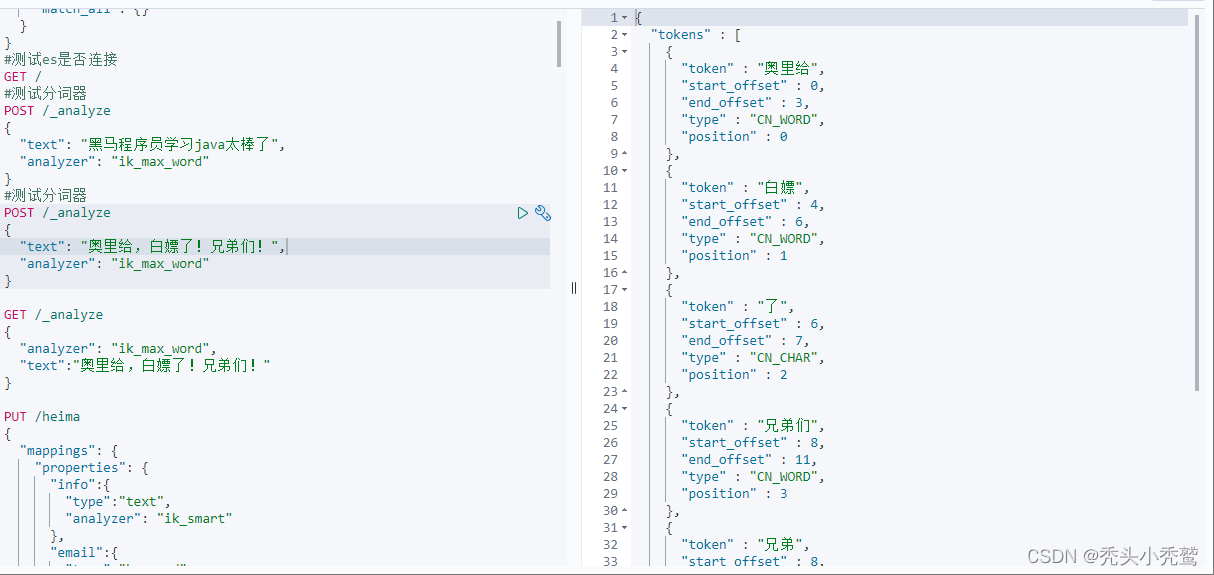
索引库:
Mappings是索引库架构的意思:他有对应的映射属性,也就是规定当前字段的一些规则。

这里还缺了两个字段:
type里面还有两种类型:

copy_to:拷贝当前的字段到指定的字段
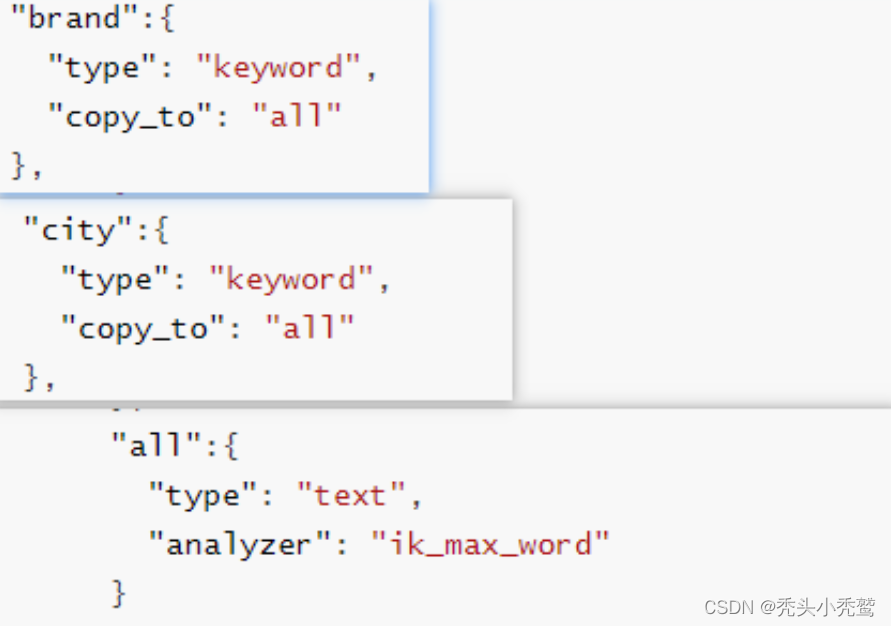
也就是索引字段all就是又city与brand来形成的。
(1)、创建索引库(Put请求)

(2)、查询索引库(Get请求:查看索引库架构)
![]()
(3)、添加索引库(Put请求:)

注意:只能添加字段,不能修改字段。
(4)、删除索引库(Delete请求:)

数据(普通操作):
(1)、添加数据:(Post请求:通过id值)

(2)、普通的查询数据(Get请求:通过id值)
![]()
(3)、删除数据(Delete请求:通过id值)
![]()
(4)、修改数据(Put/Post请求:通过id值)
4-1、全量修改:就是把数据给删除之后,再重新添加(Put请求!)

4-2 、增量修改:就是再原本的基础上面进行修改(Post请求!)

注意:
索引库里面的索引条件建立与数据放入索引库的字段没有特别规定,不能把其看成放入的数据字段要与索引库字段一致。
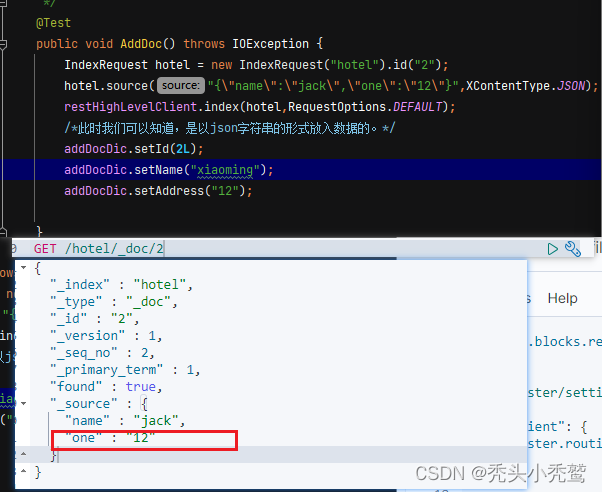
索引库里面是没有one这个字段的,但是依旧能放入进去,我们只需要认为就是我们定义的索引库里面的索引条件只是对文档里面相同的字段起到一定的作用。而不是规范文档的字段内容!
Java代码实现(普通操作):
导入依赖:

这里需要注意的点就是,要查看当前我们在虚拟机里面安装的es是那个版本的,因为springboot默认版本是7.6.2
所以我们需要修改版本:
创建连接:
因为所有技术的引用都是基于连接的,我们创建连接类:
 并且把其注入到ioc容器里面去。
并且把其注入到ioc容器里面去。
索引库操作(RestHighLevelClient.indices()):
最常用的三个api。
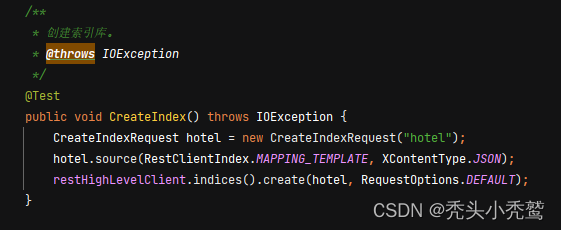
创建索引库(CreateIndexRequest):
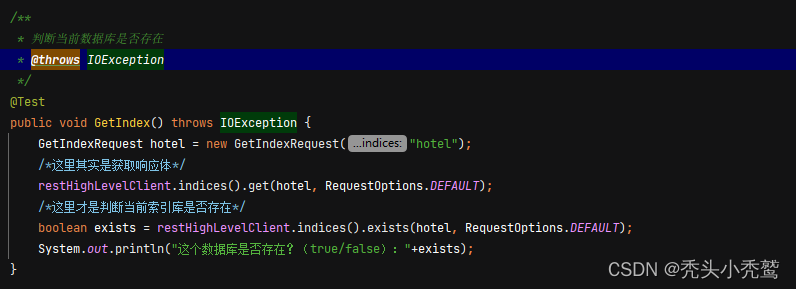
获取索引库(GetIndexRequest):
删除索引库(DeleteIndexRequest):

注意:为什么我们需要使用RestHighLevelClient.indices()。
因为RestHighLevelClient.indices()的返回值是一个IndicesClient类,他是一个进行索引库操作的封装类,里面都是执行索引库的方法。
数据操作(RestHighLevelClient.index/GET/Delete/Update/Bulk()):
添加数据(IndexRequest):
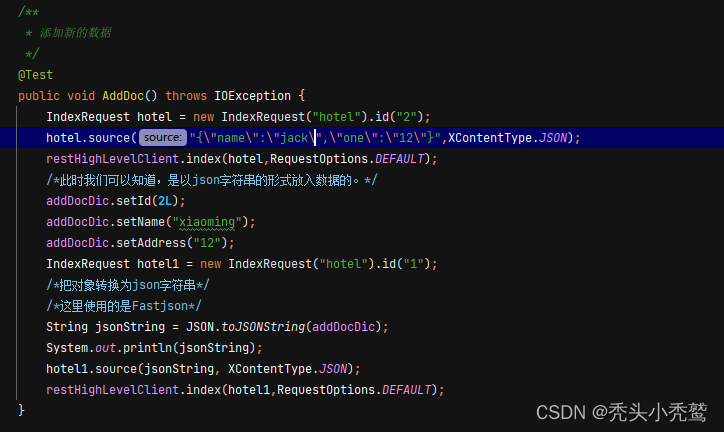
获取数据(GetRequest):
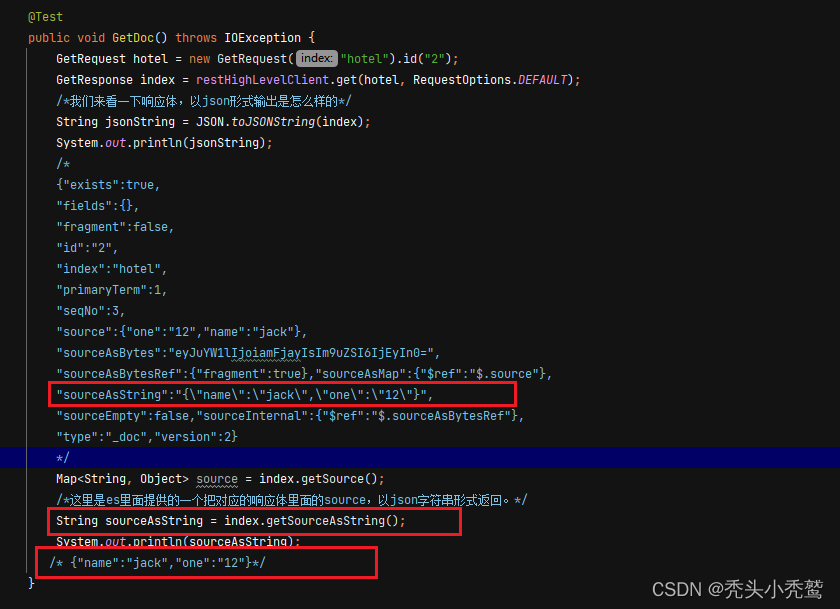
我们可以知道一个点就是,我们获取的响应体,也就是response,我们可以通过改对象的获取方法来进行获取!
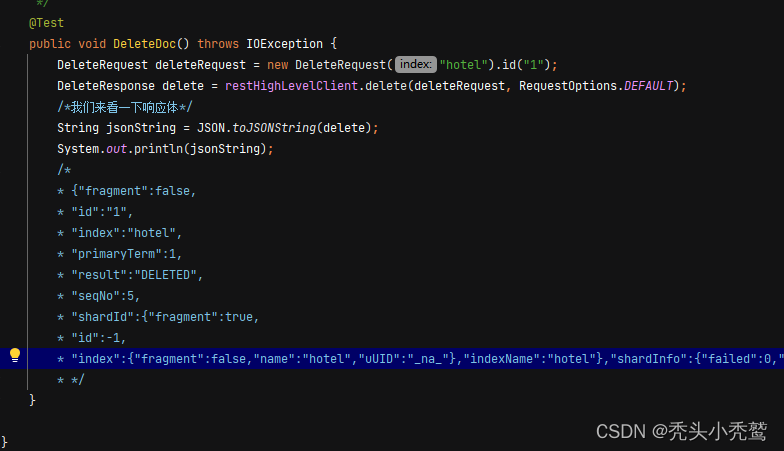
删除数据(DeleteRequest):
修改数据(updateRequest):
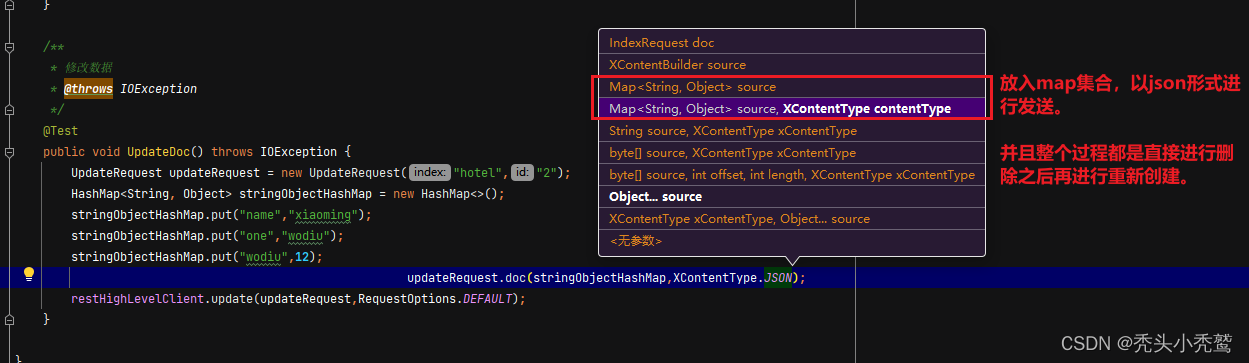
是删除原本的数据之后再进行添加。全量与增量都是一样的!
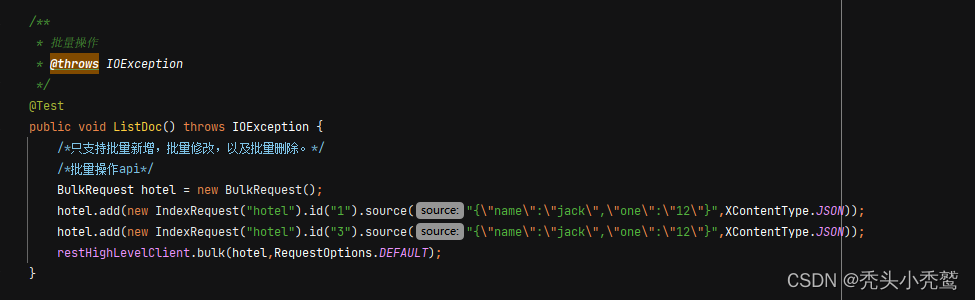
批量操作(BulkRequest)















 2136
2136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









