






1.首先把widerperson解压并把解压后的文件夹放在我的目标检测项目文件夹中
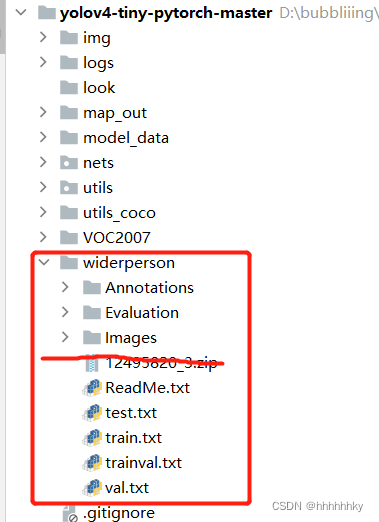
2.原始的Widerperson是没有trainval.txt的,这里是我把train.txt和val.txt合在了一起,方面运行代码一次生成xml文件,注意000040.jpg.txt和相对应的图片都要删掉,因为是乱码,影响生成xml文件。
3.运行转换voc代码
这里我把classes1-5都改为了person,因为我做行人检测,只需要person,修改完之后输出的xml文件中五种类别都是person。
import os
import numpy as np
import scipy.io as sio
import shutil
from lxml.etree import Element, SubElement, tostring
from xml.dom.minidom import parseString
import cv2
def make_voc_dir():
# labels 目录若不存在,创建labels目录。若存在,则清空目录
if not os.path.exists('./VOC2007/Annotations'):
os.makedirs('./VOC2007/Annotations')
if not os.path.exists('./VOC2007/ImageSets'):
os.makedirs('./VOC2007/ImageSets')
os.makedirs('./VOC2007/ImageSets/Main')
if not os.path.exists('./VOC2007/JPEGImages'):
os.makedirs('./VOC2007/JPEGImages')
if __name__ == '__main__':
# < class_label =1: pedestrians > 行人
# < class_label =2: riders > 骑车的
# < class_label =3: partially-visible persons > 遮挡的部分行人
# < class_label =4: ignore regions > 一些假人,比如图画上的人
# < class_label =5: crowd > 拥挤人群,直接大框覆盖了
classes = {'1': 'person',
'2': 'person',
'3': 'person',
'4': 'person', #不需要哪个类的话直接删去
'5': 'person'} #这里如果自己只要人,可以把1-5全标记为people,也可以根据自己场景需要筛选
VOCRoot = './VOC2007' #生成的voc2007的位置
widerDir = './WiderPerson' # widerperson文件夹所在的路径
wider_path = './WiderPerson/trainval.txt' #widerperson文件夹所中训练集+验证集txt标签所在位置
make_voc_dir()
with open(wider_path, 'r') as f:
imgIds = [x for x in f.read().splitlines()]
for imgId in imgIds:
objCount = 0 # 一个标志位,用来判断该img是否包含我们需要的标注
filename = imgId + '.jpg'
img_path = './WiderPerson/images/' + filename
print('Img :%s' % img_path)
img = cv2.imread(img_path)
width = img.shape[1] # 获取图片尺寸
height = img.shape[0] # 获取图片尺寸 360
node_root = Element('annotation')
node_folder = SubElement(node_root, 'folder')
node_folder.text = 'JPEGImages'
node_filename = SubElement(node_root, 'filename')
node_filename.text = 'VOC2007/JPEGImages/%s' % filename
node_size = SubElement(node_root, 'size')
node_width = SubElement(node_size, 'width')
node_width.text = '%s' % width
node_height = SubElement(node_size, 'height')
node_height.text = '%s' % height
node_depth = SubElement(node_size, 'depth')
node_depth.text = '3'
label_path = img_path.replace('images', 'Annotations') + '.txt'
with open(label_path) as file:
line = file.readline()
count = int(line.split('\n')[0]) # 里面行人个数
line = file.readline()
while line:
cls_id = line.split(' ')[0]
xmin = int(line.split(' ')[1]) + 1
ymin = int(line.split(' ')[2]) + 1
xmax = int(line.split(' ')[3]) + 1
ymax = int(line.split(' ')[4].split('\n')[0]) + 1
line = file.readline()
cls_name = classes[cls_id]
obj_width = xmax - xmin
obj_height = ymax - ymin
difficult = 0
if obj_height <= 6 or obj_width <= 6:
difficult = 1
node_object = SubElement(node_root, 'object')
node_name = SubElement(node_object, 'name')
node_name.text = cls_name
node_difficult = SubElement(node_object, 'difficult')
node_difficult.text = '%s' % difficult
node_bndbox = SubElement(node_object, 'bndbox')
node_xmin = SubElement(node_bndbox, 'xmin')
node_xmin.text = '%s' % xmin
node_ymin = SubElement(node_bndbox, 'ymin')
node_ymin.text = '%s' % ymin
node_xmax = SubElement(node_bndbox, 'xmax')
node_xmax.text = '%s' % xmax
node_ymax = SubElement(node_bndbox, 'ymax')
node_ymax.text = '%s' % ymax
node_name = SubElement(node_object, 'pose')
node_name.text = 'Unspecified'
node_name = SubElement(node_object, 'truncated')
node_name.text = '0'
image_path = VOCRoot + '/JPEGImages/' + filename
xml = tostring(node_root, pretty_print=True) # 'annotation'
dom = parseString(xml)
xml_name = filename.replace('.jpg', '.xml')
xml_path = VOCRoot + '/Annotations/' + xml_name
with open(xml_path, 'wb') as f:
f.write(xml)
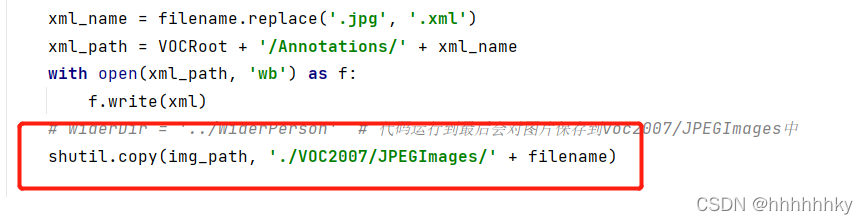
# widerDir = '../WiderPerson' # 代码运行到最后会对图片保存到voc2007/JPEGImages中
shutil.copy(img_path, './VOC2007/JPEGImages/' + filename)
注意所填的路径一定要对,我这里widerperson文件夹在我所打开的项目文件夹下面,因此路径前面一个(.)就可以。
例如: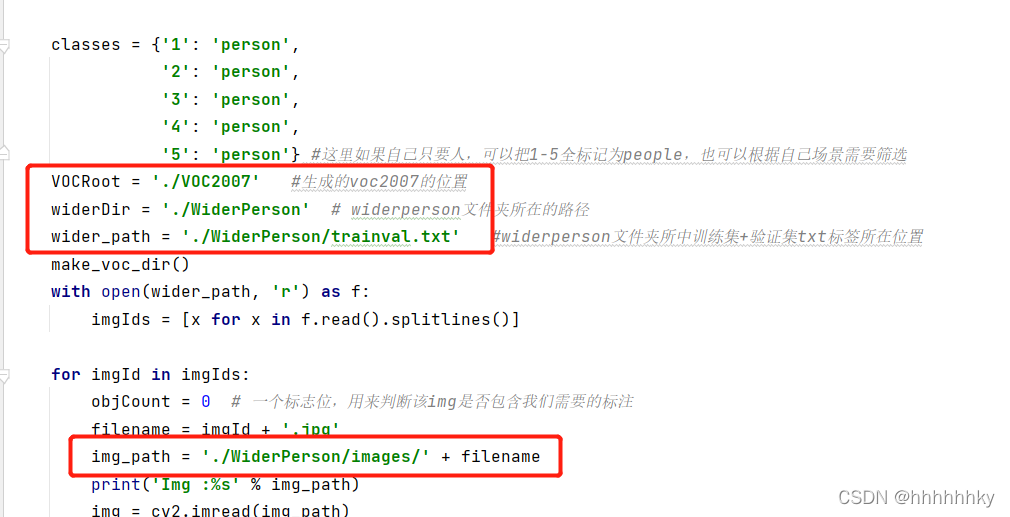
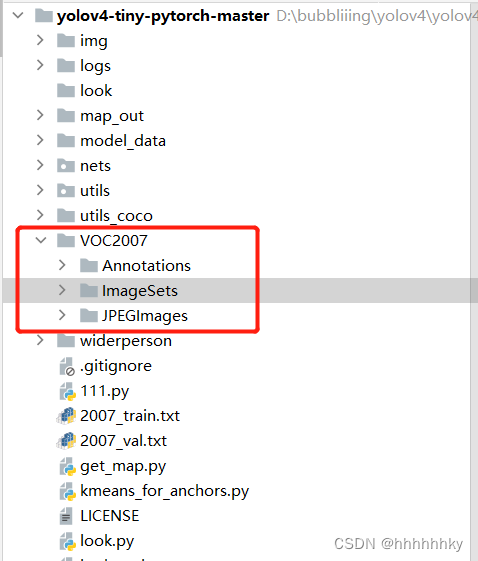
经过以上步骤就可以生成voc2007了,其实在运行这个脚本时候的绝大部分错误都是因为路径设置的格式不对。
4.最后还可以对widerperson文件夹中原始的txt标签进行可视化,同样还是在我的项目文件夹下进行,当然也可以用别的代码对xml文件进行可视化,这里是对原始的txt标注文件可视化
import os
import cv2
if __name__ == '__main__':
path = './WiderPerson/trainval.txt'
with open(path, 'r') as f:
img_ids = [x for x in f.read().splitlines()]
for img_id in img_ids: # '000040'
img_path = './WiderPerson/images/' + img_id + '.jpg'
img = cv2.imread(img_path)
im_h = img.shape[0]
im_w = img.shape[1]
label_path = img_path.replace('images', 'Annotations') + '.txt'
with open(label_path) as file:
line = file.readline()
count = int(line.split('\n')[0]) # 里面行人个数
line = file.readline()
while line:
cls = int(line.split(' ')[0])
# < class_label =1: pedestrians > 行人
# < class_label =2: riders > 骑车的
# < class_label =3: partially-visible persons > 遮挡的部分行人
# < class_label =4: ignore regions > 一些假人,比如图画上的人
# < class_label =5: crowd > 拥挤人群,直接大框覆盖了
if cls == 1 or cls == 2 or cls == 3:
xmin = float(line.split(' ')[1])
ymin = float(line.split(' ')[2])
xmax = float(line.split(' ')[3])
ymax = float(line.split(' ')[4].split('\n')[0])
img = cv2.rectangle(img, (int(xmin), int(ymin)), (int(xmax), int(ymax)), (0, 255, 0), 2)
line = file.readline()
cv2.imshow('result', img)
cv2.waitKey(0)5.数据清洗
我想给ignore和crowd两个类删去,运行下列代码
# 批量移除xml标注中的某一个类别标签
import xml.etree.cElementTree as ET
import os
path_root = ['VOC2007/Annotations']
CLASSES = ["crowd"] # 填入想要删去的类别,每次删去一个类
for anno_path in path_root:
xml_list = os.listdir(anno_path)
for axml in xml_list:
path_xml = os.path.join(anno_path, axml)
tree = ET.parse(path_xml)
root = tree.getroot()
print("root",root)
for child in root.findall('object'):
name = child.find('name').text
print("name",name)
if name in CLASSES: # 这里可以反向写,不在Class的删掉
root.remove(child)
# 重写
tree.write(os.path.join('VOC2007/Annotations_new', axml)) # 记得新建annotations_new文件夹
参考一下两位老哥:
WiderPerson行人检测数据集_松菇的博客-CSDN博客_widerperson数据集
关于WiderPerson数据说明(使用后笔记)_wait a minute~的博客-CSDN博客
评估:

















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









