







注意力机制:源自于人对于外部信息的处理能力。人在处理信息的时候,
会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤。
注意力机制的引起方式:非自主提示 源自于物体本身,而自主提示 源自于一种主观倾向。
- 考虑非自主提示的话,只需要对所有物体的特征信息进行简单的全连接层,甚至是无参数的平均汇聚层或者是最大汇聚层,就可以提取处需要感兴趣的物体。
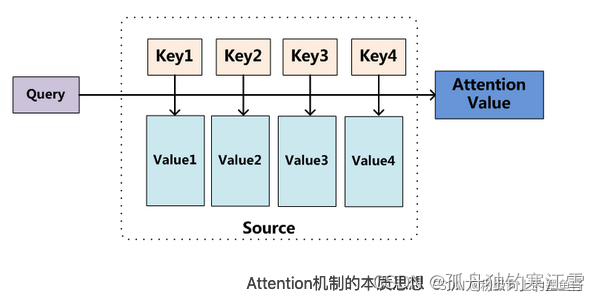
- 如果考虑自主提示的话,我们就需要设计一种通过查询(Query),键(Key)和值(Value) 来实现注意力机制的方法。
Query:指的是
自主提示,即主观意识的特征向量;
Key:指的是非自主提示,即物体的突出特征信息向量;
Value:则是代表物体本身的特征向量。
注意力机制:是通过Query与Key的注意力汇聚(指的是对Query和Key的相关性进行建模,实现池化筛选或者分配权重),实现对Value的注意力权重分配,生成最终的输出结果。
加性注意力:一般用来处理Query和Key的向量位数不一致的情况,公式如下: a ( q , k ) = W v T t a n h ( W q q + W k k ) a(q, k)=W_{v}^{T}tanh(W_{q}q+W_{k}k) a(q,k)=WvTtanh(Wqq+Wkk)。假设 q ∈ R q , k ∈ R k q\in R^{q},k\in R^{k} q∈Rq,k∈Rk,则 W q ∈ R h × q , W k ∈ R h × k , W v ∈ R h × v W_{q}\in R^{h\times q}, W_{k}\in R^{h\times k}, W_{v}\in R^{h\times v} Wq∈Rh×q,Wk∈Rh×k,Wv∈Rh×v 。通过两个全连接层 W q W_{q} Wq和 W k W_{k} Wk,可以将查询和键统一到一个向量维度,然后经过相加和激活函数tanh,即可得到查询和键的关系,在经过全连接层 W v T W_{v}^{T} WvT将向量位数统一到和Value的向量维度一致。
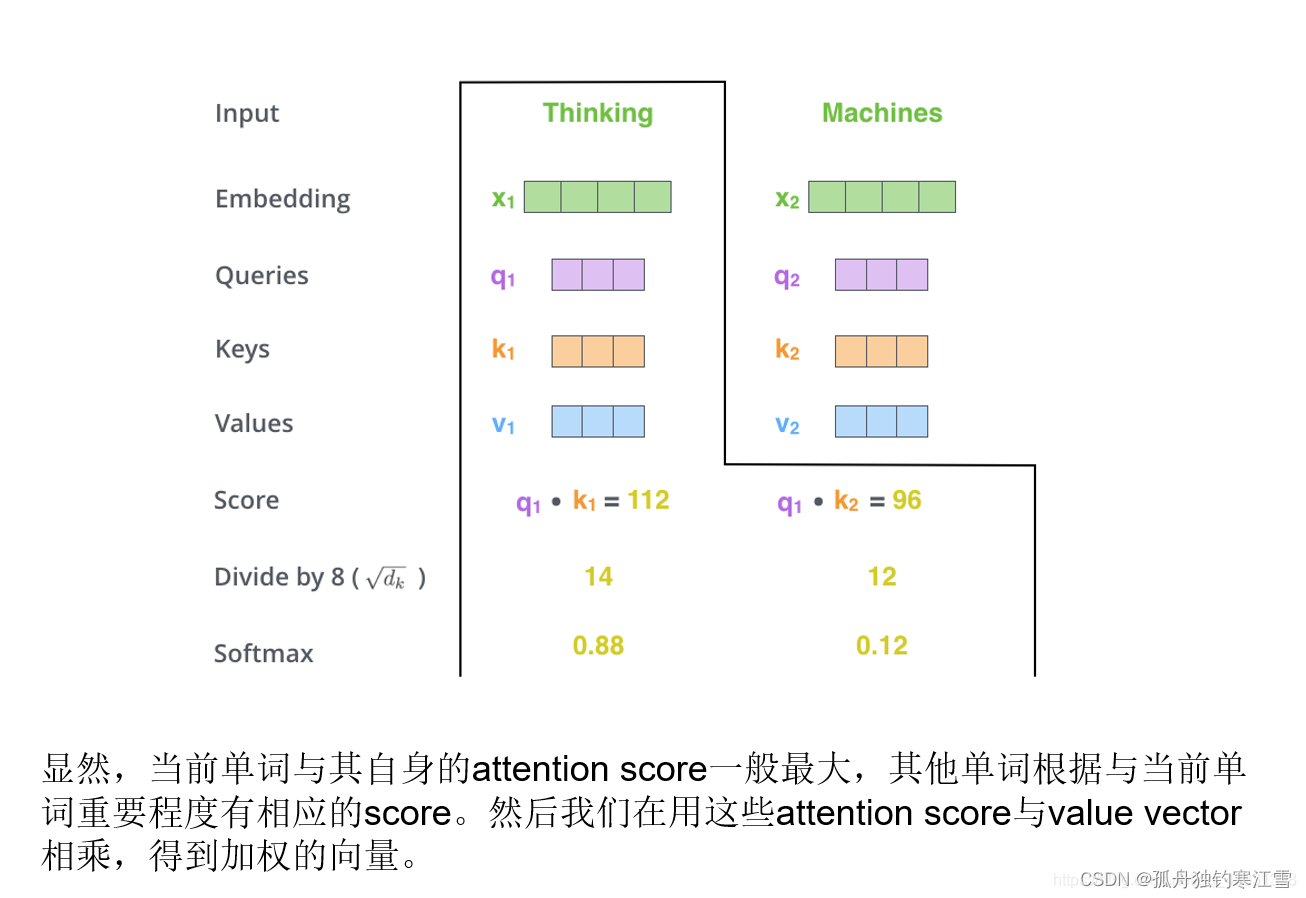
点积注意力:Query和Key的向量维数必须一致,其公式如下: a ( q , k ) = q T . k d k a(q, k) = \frac{q^{T}.k}{\sqrt{d_{k}}} a(q,k)=dkqT.k。其中, q ∈ R n × d , k ∈ R m × d q\in R^{n\times d}, k\in R^{m\times d} q∈Rn×d,k∈Rm×d,然后经过softmax函数得到Value权重的概率分布,公式如下: A t t e n t i o n ( x ) = s o f t m a x ( Q T ⋅ K d ) Attention(x) = softmax(\frac{Q^{T}\cdot K}{\sqrt{d}}) Attention(x)=softmax(dQT⋅K)。
多头注意力:单一注意力汇聚,只能建立一种Query和Key的依赖关系。将QKV经过多组全连接层来获取对应的特征向量,然后分别对这些特征向量进行注意力汇聚,最后将所有注意力汇聚运算结果进行拼接,再经过一个全连接层,映射处最后的输出。
自注意力:注意力机制的Query和Key是不同来源的,在Encoder-Decoder模型中,Key是Encoder中的元素,Query是Decoder中的元素(如在中译英模型中,Query是中文单词的特征,而Key是英文单词的特征)。自注意力机制的Query和Key都是来自同一组的元素,如都是来自于Encoder中的元素,即Query和Key都是中文特征,相互之间做注意力汇聚。
向量的点积:可以表示两个向量的相似度similarity。
- 自注意力机制:就是通过权重矩阵来自发地找到词与词之间的关系。Q、K、V(Q=K)

X[2, 4] # [seq_len, d_embedding]
Q[2, 3] # [seq_len, d_q]
K[2, 3] # [seq_len, d_q]
V[2, 3] # [seq_len, d_v]
Q*K^T [2, 2] # [seq_len, seq_len]
softmax(Q*K^T)*V # [seq_len, d_v]
其中,查询矩阵Q
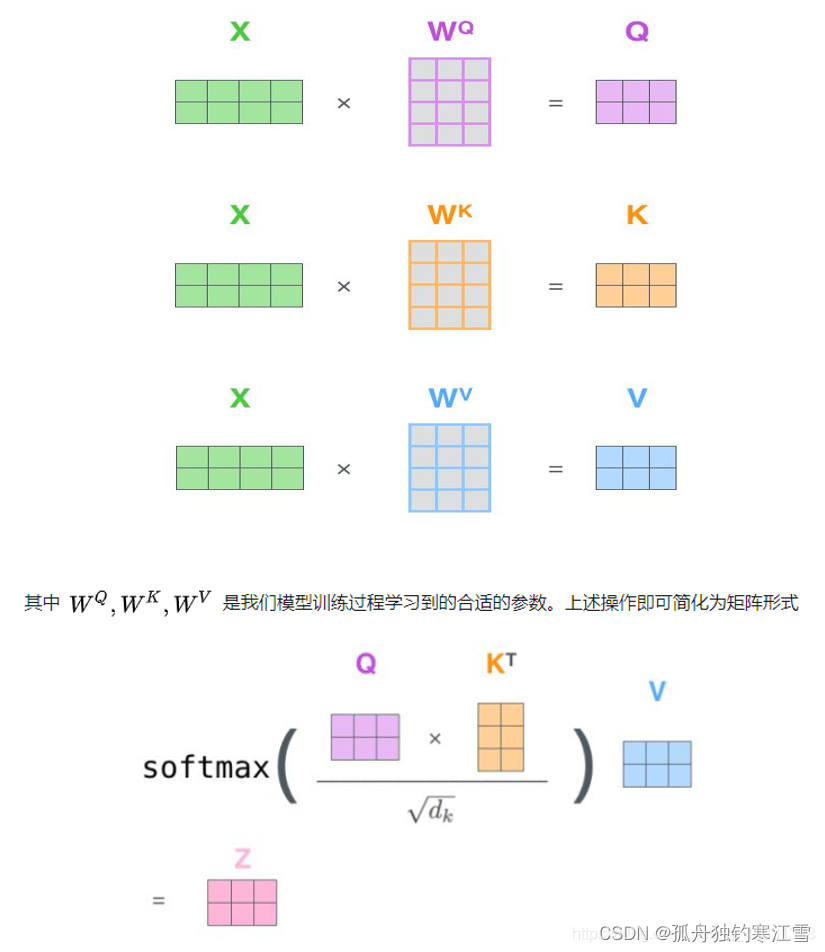
Q, K , V为三个权重矩阵,随机初始化以后,在训练数据的梯度下降过程中优化。将Transformer机制的训练目标记为M。 键矩阵K和值矩阵V可以理解成训练样本中可能存在的多种不同pattern构成的template K,接近训练目标M的程度 V。也就是已知的一组template与目标M之间的对应关系(K, V)。查询矩阵Q 代表从训练样本提取出的pattern,考察Q与K的相似程度,与K 越相似的Q,与目标M 的接近程度也越与K对应的接近。
计算每个单词与其他单词之间的关联,如下:
三个矩阵Q、K、V如下:
多头
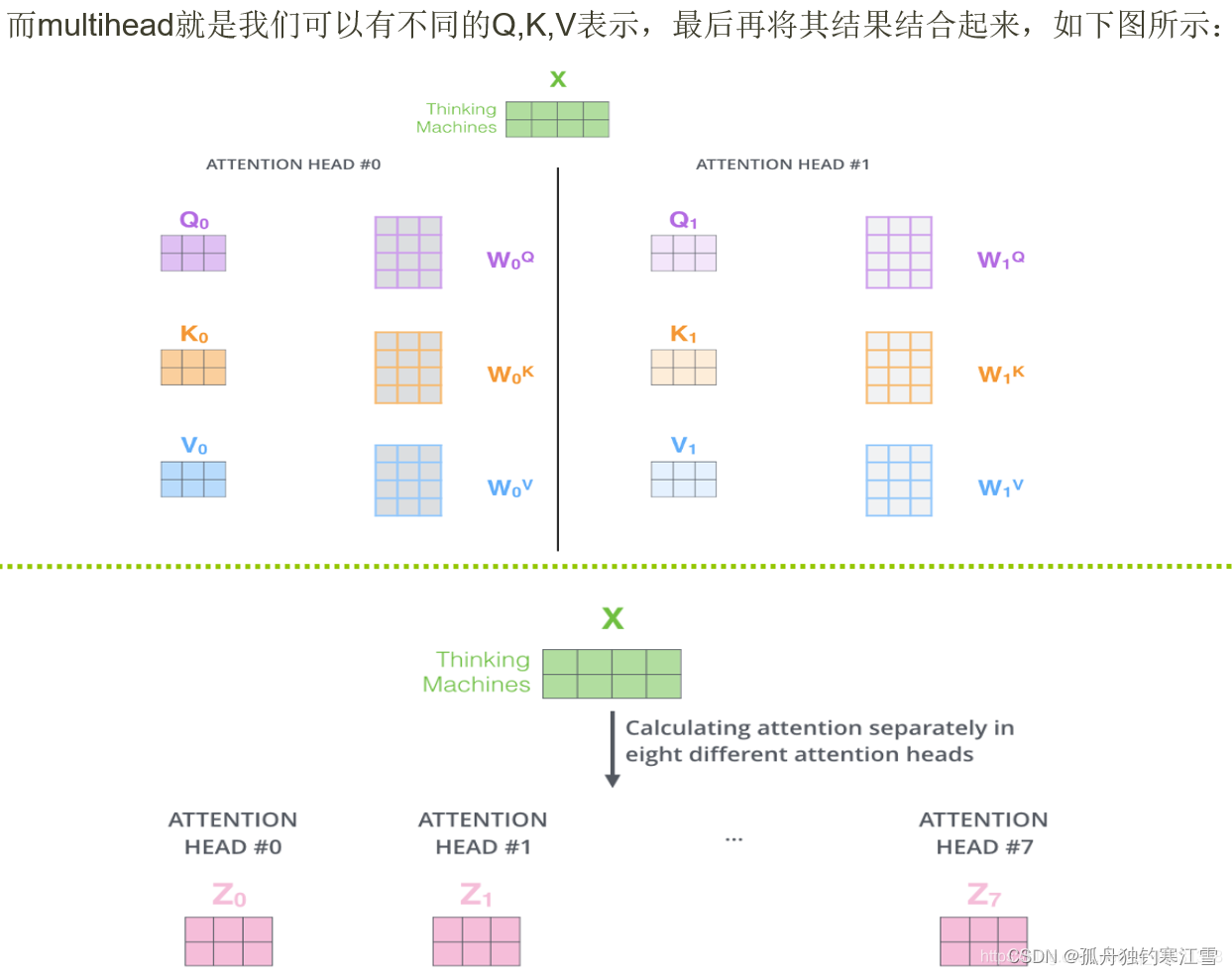
多个向量z映射

- 编解码注意力机制 Encoder-Decoder Attention
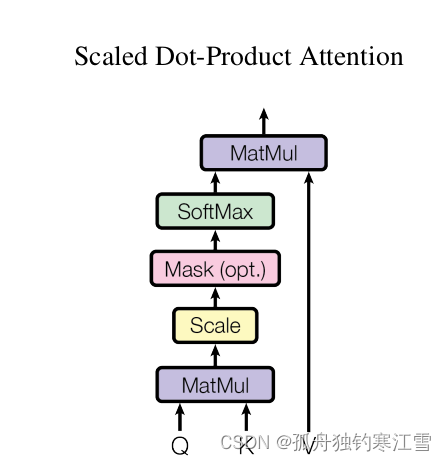
1. Scaled Dot-Product Attention (缩放点积注意力)
Dot-Product:指Q和K之间通过计算点积值作为相似度。
Scaled:指的是将计算得到的相似度进行量化。即除以 d k \sqrt{dk} dk
Mask:将padding部分填充负无穷,使得在softmax时该处attention为0,从而避免padding带来的影响。
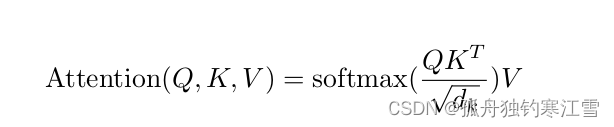
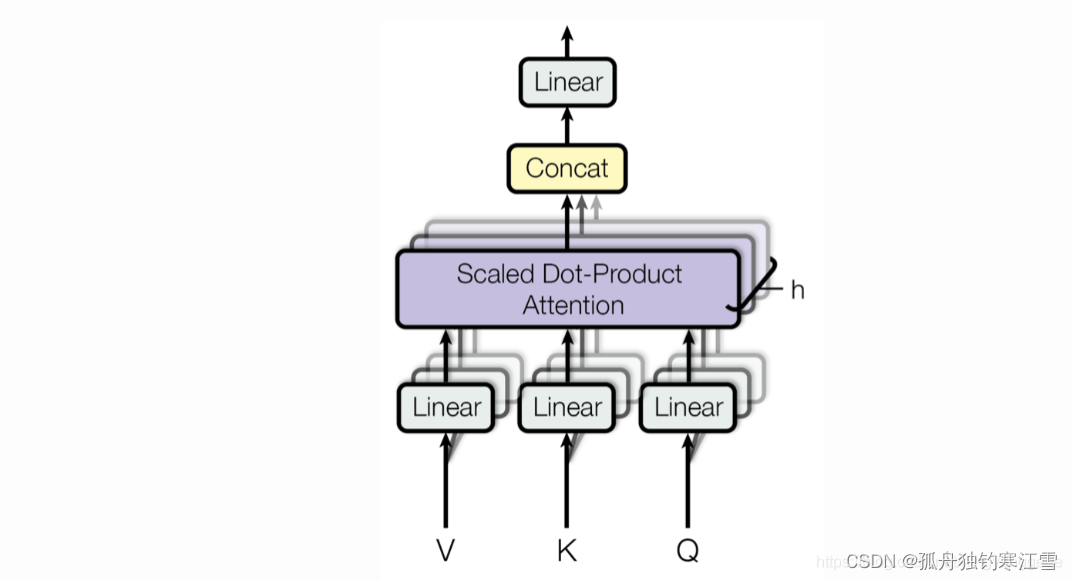
2. Multi-Head Attention
在 Scaled Dot-Product Attention 的基础上,分为多头,也就是多个 Q、K、V并行计算attention,可能侧重于不同方面的相似度和权重。
3. Self-Attention
在 Scaled Dot-Product Attention 以及 Multi-Head Attention 的基础上,一种应用场景,指Q、K、V的来源是相同的,自己与自己进行attention计算。
一种注意力机制,将一个序列的不同位置联系起来,以计算序列的表示。

来自博文「超详细图解Self-Attention的那些事儿」
similarity—>向量内积,Softmax—>归一化,Attention机制的核心—>加权求和,
Q、K、V—>来自X, d k \sqrt{d_{k}} dk意义















 7332
7332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









