







环境准备
| Linux系统 | CentOS-7 |
| Hadoop | 2.7.6 |
| jdk | 1.8. |
| spark | 2.3.3 |
spark部署方式
Standalone模式
集群单机模式。在该模式下,spark集群架构为主从模式,此时集群会出现单点故障问题。
Yarn模式
Spark on Yarn模式,即把spark作为一个客户端,将作业提交给yarn服务。Yarn与Hadoop有密切关系。同时运行Hadoop和spark时优先选用。
yarn Cluster:用于生产环境,所有资源调度和计算都在集群上运行
Yarn Client:用于交互、调试环境
Mesos模式
Spark on Mesos模式,Mesos和Yarn同样是资源调度管理系统。Mesos与spark有密切关系。
Standalone模式 搭建
解压
tar -zxvf spark-2.3.3-bin-hado.tgz -C /opt/programs

报错:权限不够。可以在命令前加sudo或者进入root用户
压缩文件报错 tar: Exiting with failure status due to previous errors_细雨青峦的博客-CSDN博客
给文件夹改名,方便后续操作
mv spark-2.3.3-bin-hadoop2.7/ spark
修改配置文件
进入/spark/conf目录
将配置模板文件spark-env.sh.template复制一份并命名为spark-env.sh
cp spark-env.sh.templatespark-env.sh
配置文件spark-env.sh
#配置java环境变量
export JAVA_HOME=/opt/programs/jdk1.8.0_211
#指定Master的IP
export SPARK_MASTER_HOST=host01
#指定Master端口
export SPARK_MASTER_PORT=7077
复制文件slaves.template并重命名为slaves
cp slaves.template slaves
配置slaves
#删掉locelhost并添加
#× hadoop02
#× hadoop03
host02
host03
分发文件
修改完配置文件后,将spark目录分发到host02和host03
scp -r /opt/programs/spark/ host02:/opt/programs/
scp -r /opt/programs/spark/ host03:/opt/programs/
启动spark集群
在/spark文件夹下
启动所有结点sbin/start-all.sh
关闭所有结点sbin/stop-all.sh
单独启动主节点sbin/start-master.sh


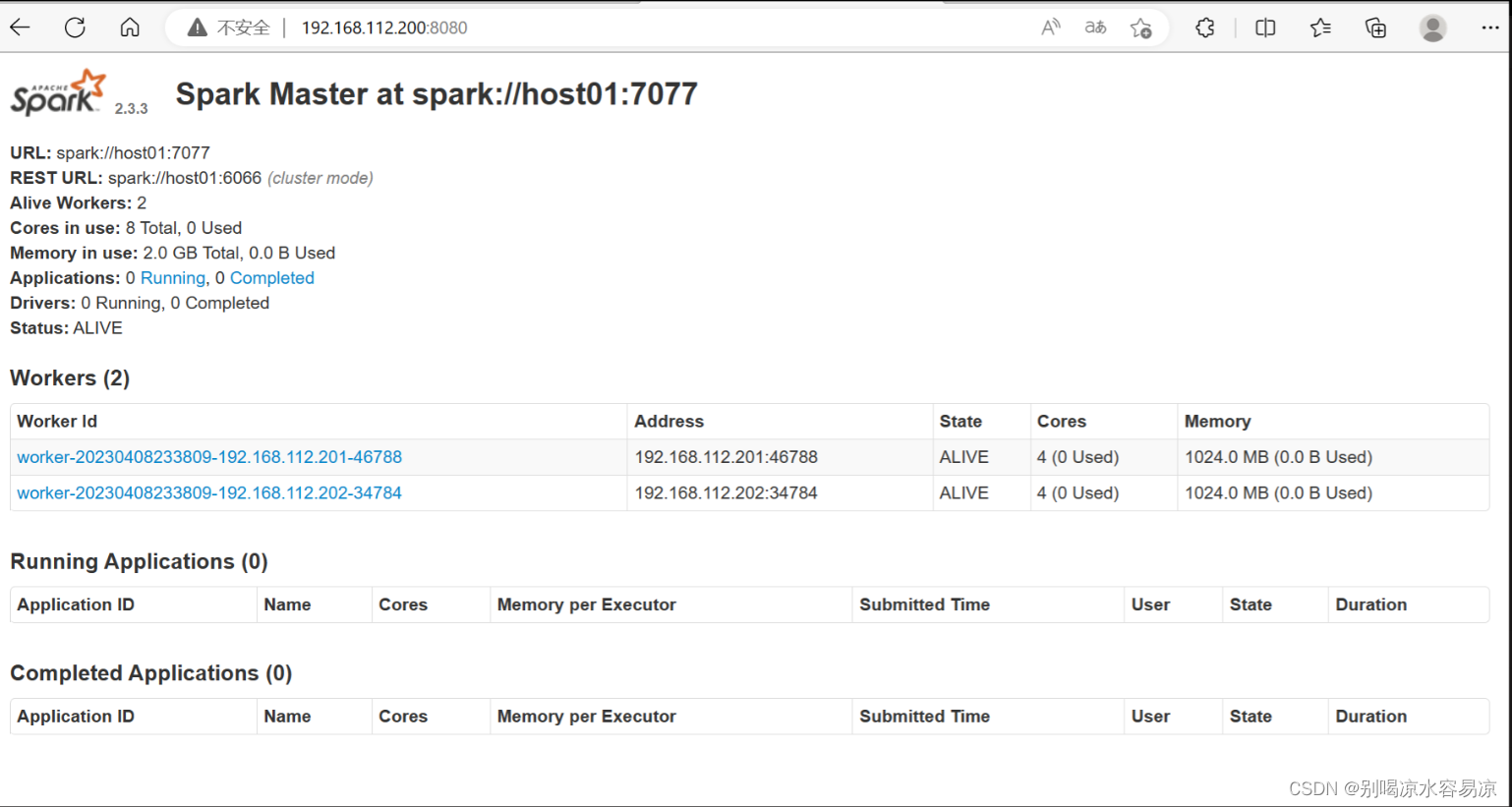
spark集群管理页面














 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









