









目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的工地安全帽佩戴检测算法系统

设计思路
一、课题背景与意义
在建筑施工行业,由于作业人员长期在高危区域中工作,为了确保工作人员的生命安全,所有人都必须佩戴好安全帽。正确佩戴好安全帽极为重要,安全帽是最为有效的保护手段,能够有效降低外界潜在风险对人的身体损害,确保施工行业的稳定发展。但是现有安全帽检测模型在复杂环境下对重叠和密集小目标存在误检和漏检等问题。
二、算法理论原理
2.1 MHSA 和 CoAtNet
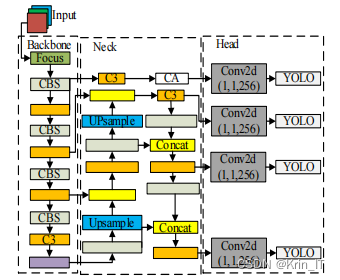
借鉴BoTNet替换ResNet的Bottleneck为MHSA的设计思想,我在原始的YOLOv5模型基础上将Bot-transformer引入到主干网络中,提高了YOLOv5模型对长距离依赖关系的建模能力,能够更好地捕捉图像中的重要特征,这种方法提高了对小目标的检测性能,同时减少了参数量,实现了最小化的延迟。为了降低计算的复杂度,决定把自注意力机制置于网络模型之后,借鉴CoAtNet设计的C-C-T-T的排列混合方式,将主干网络的第3和第4个Bottleneck替换为Bot-transformer。通过这种改进方式,在保证计算复杂度的前提下,有效地融合了CNN和Transformer的优势,提升了模型的特征表达能力和泛化能力。

2.2 GSConv
GSConv是一种全局稀疏卷积操作,通过在特征图上引入全局稀疏性,实现了对全局信息的有效聚合,相比传统的普通卷积,在保持全局信息的同时,GSConv利用了全局稀疏性,仅对稀疏位置进行卷积计算,大大减少了计算量和参数数量。
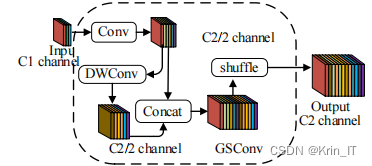
在特征金字塔模块中使用GSConv处理多尺度特征信息会更好,重复信息较少,改进YOLOv5模型的准确率会非常接近原YOLOv5模型。在特征金字塔部分中,将Conv卷积替换为GSConv,同时简化四个有效输出特征层的通道数,均为256,能够减轻模型的复杂度,加快算法的推理速度,适合在资源受限的环境中部署。
相关代码:
import torch
import torch.nn as nn
class Focus(nn.Module):
def __init__(self, in_channels, out_channels):
super(Focus, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
# 获取输入特征图的尺寸
_, _, height, width = x.size()
# 对特征图进行切片操作
tl = x[:, :, :height//2, :width//2] # 左上角切片
tr = x[:, :, :height//2, width//2:] # 右上角切片
bl = x[:, :, height//2:, :width//2] # 左下角切片
br = x[:, :, height//2:, width//2:] # 右下角切片
# 将切片后的特征图拼接起来
out = torch.cat([tl, tr, bl, br], dim=1)
# 对拼接后的特征图进行卷积操作
out = self.conv(out)
return out
# 使用示例
in_channels = 256
out_channels = 64
# 创建Focus模块
focus = Focus(in_channels, out_channels)
# 输入示例特征图
x = torch.randn(1, in_channels, 32, 32)
# 前向传播
output = focus(x)
print(output.shape)三、检测的实现
3.1 数据集
由于网络上没有现有的合适的数据集,学长决定自己去工地进行拍摄,收集图片并制作了一个全新的数据集。这个数据集包含了各种建筑施工场景的照片,其中包括作业人员佩戴安全帽的情况以及其他相关安全设施。通过现场拍摄,我能够捕捉到真实的场景和多样的工作环境,这将为我的研究提供更准确、可靠的数据。

为了解决自制数据集样本数量较少的问题,我决定对拍摄的图片进行数据增强。数据增强是一种通过对原始图像进行变换和扩充来增加样本多样性和数量的技术。我使用了多种数据增强方法,包括旋转、翻转、缩放、平移等,以及改变亮度、对比度和色彩等方面的调整。通过这些操作,我能够生成更多的样本,使得数据集变得更加丰富和多样化。
3.2 实验环境搭建
实验环境:CPU为Intel Core i7-10700,24G运行内存,GPU为NVIDIA Quadro P4000,8G显存,Window10,64位操作系统,通过Pytorch1.8.0深度学习框架实现模型的搭建、训练和验证,计算架构为CUDA11.3.1,加速软件为CUDNN8.2.1。超参数设置为:训练图片分辨率为640*640,批次大小设置为4,使用SGD优化器,初始学习率设置为0.01,mixup为0.5,冻结训练50个epoch,总迭代运行次数为300个epoch。所有参照模型均按照以上参数进行训练。
3.3 实验及结果分析
为了验证改进后的YOLOv5模型在安全帽小目标上的表现,我们在数据集上进行多次对比实验,并对模型的权重大小,推理时间,平均精度和召回率四个指标进行验证,由实验结果可知改进后的YOLOv5模型能有效提高安全帽这类小目标的精度,改善安全帽漏检问题,显著提高了模型性能。

mAP和Recall的曲线图:
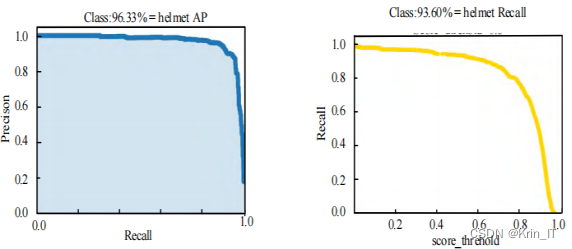
改进后的YOLOv5模型在小目标的检测性能上要远远优于原模型,而且具有较高的准确率和召回率。这意味着改进后的模型能够减少小目标漏检和误检的概率,从而更好地满足目前的需求。
相关代码如下:
image = cv2.imread('image.jpg')
image_tensor = F.to_tensor(image)
image_tensor = image_tensor.unsqueeze(0)
# 使用模型进行推理
with torch.no_grad():
predictions = model(image_tensor)
# 处理模型的预测结果
boxes = predictions[0]['boxes']
labels = predictions[0]['labels']
scores = predictions[0]['scores']
# 遍历每个预测结果并绘制边界框
for box, label, score in zip(boxes, labels, scores):
# 获取边界框坐标和类别标签
xmin, ymin, xmax, ymax = box.tolist()
class_label = class_labels[label]
# 绘制边界框和类别标签
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)
cv2.putText(image, class_label, (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 显示结果图像
cv2.imshow('Detection Result', image)
cv2.waitKey(0)
cv2.destroyAllWindows()实现效果图样例

创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!














 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









