







一、背景意义
随着农业技术的进步和深度学习的广泛应用,奶牛姿势检测逐渐成为智能农业的重要研究方向。奶牛的姿势不仅影响其健康和生产效率,还与乳品质量和牛奶产量密切相关。因此,建立一个高质量的奶牛姿势数据集,对于研究和开发自动化监测系统具有重要意义。该数据集包含多种姿势分类,如站立、坐卧、行走、饮水和进食等,旨在为深度学习模型提供丰富的训练和测试样本。通过对奶牛姿势的自动检测,农场主可以实时监控奶牛的健康状态,从而及时调整饲养管理,提升整体生产效率。结合深度学习技术,可以实现奶牛姿势的自动化监测,推动智能农业的进步,减少人力成本,提高管理效率
二、数据集
2.1数据采集
首先,需要大量的奶牛姿势图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示奶牛特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
创建一个奶牛姿势数据集是一项复杂而繁重的任务,需要准确标注奶牛在不同姿势下的表现。该数据集的分类包括奶牛的躺卧、站立和行走动作。使用标注工具如LabelImg,标注人员需要耗费大量时间和精力来准确识别奶牛的各种姿势,并标注它们的边界框和类别信息。躺卧姿势可能涉及奶牛身体各部位的接触面和位置,站立时需要考虑奶牛四肢的姿势和身体垂直度,而行走时则需要捕捉奶牛移动过程中的姿势变化和步态特征。标注人员必须面对复杂的场景,如奶牛之间的重叠、部分遮挡以及不同光照条件下的表现差异。确保数据集的高质量和准确性对于训练有效的机器学习模型至关重要,这将为农业智能监测系统和畜牧业管理提供宝贵的数据支持,但也需要克服标注过程中的复杂性和耗时性带来的挑战。

包含4932张奶牛图片,数据集中包含以下几种类别
- 躺卧:奶牛躺在地面上,四肢伸直或者稍微弯曲,头部可能放在前腿之间或者侧躺。
- 站立:奶牛身体直立,四肢支撑着身体重量。站立觅食、休息或者进行社交互动。
- 行走:四肢交替运动,身体向前推进。奶牛行走的速度和方式反映其活跃程度和健康状态。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 数据清洗:去除重复、无效或有噪声的数据。
- 数据标准化:例如,对图像进行尺寸调整、归一化,对文本进行分词和清洗。
- 数据增强:通过旋转、缩放、裁剪等方法增加数据的多样性,防止模型过拟合。
- 数据集划分:将数据集划分为训练集、验证集和测试集,确保模型的泛化能力。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
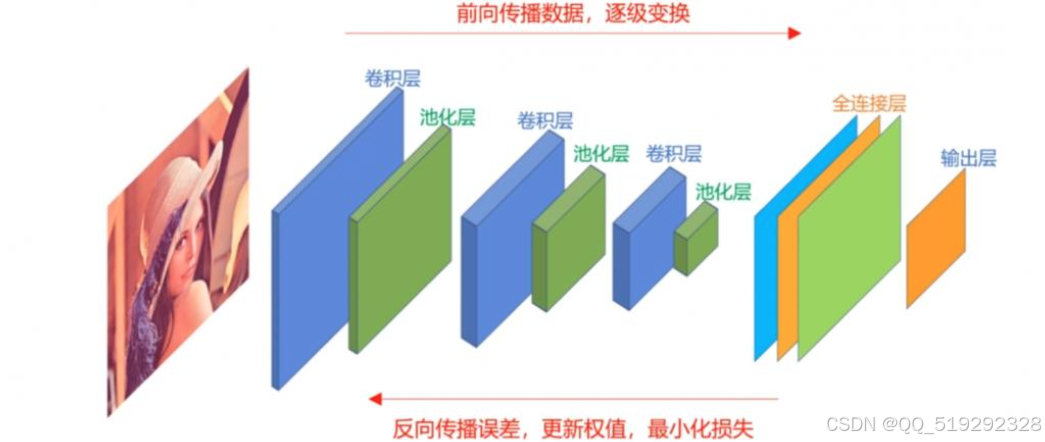
在深度学习中,卷积神经网络(CNN)是最适合奶牛姿势检测的算法。CNN专为处理图像数据而设计,能够自动提取和学习图像中的特征,广泛应用于物体识别、姿势估计和图像分类任务。CNN的主要结构由以下几个部分组成:
-
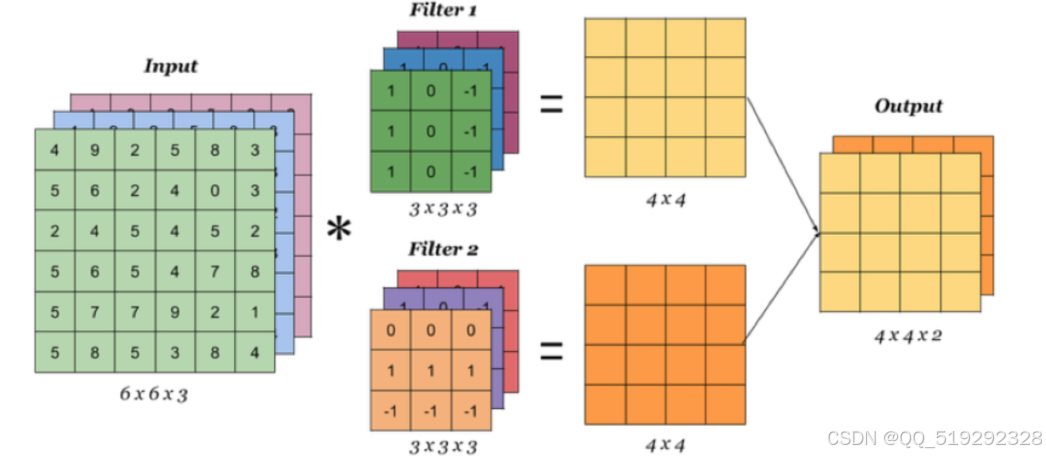
卷积层:卷积层是CNN的核心,利用多个卷积滤波器对输入图像进行卷积操作。每个滤波器能够学习到图像中的局部特征,如边缘、纹理和形状。通过堆叠多个卷积层,网络可以提取出越来越复杂的特征。
-
激活层:通常使用ReLU(修正线性单元)作为激活函数,引入非线性因素,帮助模型更好地拟合复杂的函数。
-
池化层:池化层通常跟随卷积层,进行下采样,减少特征图的维度,降低计算复杂度,并防止过拟合。常用的池化方法有最大池化和平均池化。
-
全连接层:在网络的最后部分,通常会有一个或多个全连接层,将提取到的特征映射到具体的类别上,输出每个类别的概率。
与传统的机器学习方法不同,CNN能够从原始图像中自动学习和提取特征,无需手动设计复杂的特征提取算法。这种自动化的过程不仅大大节省了时间和精力,也使得模型能更有效地捕捉到数据中的潜在模式和特征。通过共享权重和局部连接的机制,CNN能够显著减少参数数量,这使得模型在计算效率上相较于传统的全连接神经网络更为优化,尤其适合处理大规模图像数据。这种高效性不仅加快了训练过程,还降低了内存消耗,使得模型在资源有限的设备上也能高效运行。经过大规模数据集的训练,CNN能够有效地适应不同的环境和条件,减少过拟合的风险。这使得CNN在现实应用中更加可靠,能够在不同场景中保持较高的识别精度。
3.2模型训练
在完成奶牛姿势数据集的划分和准备后,开发一个基于 YOLO模型的项目需要经过以下几个关键步骤:模型配置、训练模型、评估模型和部署模型。以下是各步骤的详细介绍。
模型配置:
创建一个YAML配置文件,指定训练和验证数据集的路径,以及类别的具体信息。在此过程中,确保数据集的结构清晰,并且每个类别都被准确标注,以便模型能够有效学习。
# YAML 配置文件的代码示例
# yolov5/data/cow_pose.yaml
# 训练集和验证集路径
train: ../data/cow_pose/images/train # 训练集图像路径
val: ../data/cow_pose/images/val # 验证集图像路径
# 类别数量
nc: 3 # 类别数量,例如:站立、坐卧、行走
# 类别名称
names: ['standing', 'lying', 'walking'] # 奶牛姿势分类名称训练模型:
在模型配置完成后,进入训练阶段。这一过程是将YOLO模型应用于准备好的数据集,通过不断迭代学习图像中的特征,优化模型的性能。训练过程中,模型会使用损失函数来评估预测结果与真实标签之间的差距,并根据这一差距不断调整内部参数。训练时,需要设置多个超参数,如图像大小、批次大小、训练轮数等。训练过程可以选择使用预训练模型的权重,这样可以加速收敛并提高模型的准确性。训练完成后,模型会保存为一个文件,便于后续的评估和部署。
# 在终端中运行以下命令
!python train.py --img 640 --batch 16 --epochs 100 --data custom.yaml --weights yolov5s.pt --save-period 5评估模型:
训练完成后,接下来是对模型进行评估。这一步骤的目的是测试模型在未见过的数据上的表现,以确定其泛化能力和准确性。评估通常会使用一个独立的测试集,通过计算各种指标(如平均精度均值mAP、损失值等)来分析模型的表现。
评估过程中,模型会对每张测试图像进行推断,并与真实标签进行比较。通过这些评估指标,研究人员可以判断模型是否达到了预期的性能标准,是否需要进一步的调优或改进。
import torch
# 加载训练好的模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt', force_reload=True)
# 进行评估
results = model.val()
# 输出评估结果
print("模型评估结果:")
print(f"损失: {results.loss}, mAP@0.5: {results.maps[0]}")部署模型
最后一步是模型的部署。这一阶段的目标是将训练好的YOLO模型应用于实际场景中,提供实时的奶牛姿势检测服务。部署可以通过多种方式进行,例如将模型集成到现有的农业管理系统中,或者通过Web应用提供API接口。在部署过程中,可以使用如Flask或FastAPI等Web框架来构建一个简单的服务,通过HTTP请求接收图像,返回检测结果。确保服务能够高效处理请求,具有良好的响应速度和用户体验。
from flask import Flask, request, jsonify
import torch
from PIL import Image
import io
app = Flask(__name__)
# 加载训练好的模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt')
@app.route('/predict', methods=['POST'])
def predict():
# 获取上传的图片
file = request.files['file']
img = Image.open(io.BytesIO(file.read()))
# 进行预测
results = model(img)
# 获取预测结果
predictions = results.pred[0].numpy().tolist()
# 提取预测信息
response = []
for pred in predictions:
response.append({
'class': int(pred[5]), # 类别索引
'confidence': float(pred[4]), # 置信度
'bbox': pred[:4].tolist() # 边界框坐标
})
return jsonify(response)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)四、总结
奶牛姿势数据集是一个专门用于研究和开发奶牛姿势检测系统的重要资源。该数据集涵盖多种姿势分类,包括站立、坐卧、行走等。这些姿势的准确标注为深度学习模型的训练和测试提供了丰富的样本,旨在提升智能农业系统的监测能力。随着农业科技的不断进步,自动化监测奶牛的健康状态和活动情况变得愈发重要。该数据集不仅能帮助研究人员利用卷积神经网络(CNN)等先进算法进行姿势识别,还能为养殖者提供实时反馈,促进奶牛的管理和护理。

















 276
276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









