







一、背景意义
随着深度学习技术的迅猛发展,计算机视觉在各个领域的应用逐渐深入,尤其是在食品检测和分类方面。海鲜作为人类饮食中重要的组成部分,种类繁多,常见的海鲜包括螃蟹、龙虾和虾等。这些海鲜在市场上不仅需求量大,而且因其新鲜度和品质直接影响消费者的健康与安全。在传统的海鲜分类中,人工识别容易出现误差,且效率低下。通过构建深度学习模型,利用海鲜数据集进行训练和测试,可以实现对海鲜的自动化识别与分类,从而提高分类的准确性和效率。利用深度学习模型,可以有效处理复杂的视觉特征,提高对不同种类海鲜(如螃蟹、龙虾和虾)的识别精度,减少人工分类中的错误。准确分类海鲜有助于确保消费者获取新鲜、优质的食品,从而提高食品安全水平,保护消费者的健康
二、数据集
2.1数据采集
首先,需要大量的海鲜类图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示海鲜特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
数据标注是为每张图像分配相应的类别标签,以便于后续的模型训练。具体步骤包括:
- 选择标注工具:使用图像标注工具(如LabelImg)对收集的图片进行标注。
- 标记类别:对每张图片进行分类,标注为“Crab”(螃蟹)、“Lobster”(龙虾)或“Shrimp”(虾)。
- 边界框标注:如果需要进行目标检测,可以为每个物体添加边界框,记录其在图像中的位置。
- 格式统一:确保所有标注数据保存为统一的格式,如YOLO或Pascal VOC,以便于后续处理和模型训练。
数据集包含螃蟹、龙虾和虾等海鲜分类。使用LabelImg标注这个数据集将面临较高的复杂度和工作量,因为这些海鲜动物具有复杂的外观特征和多样的形态。标注人员需要耗费大量时间和精力对每个样本进行准确标注,以确保模型能够准确地识别和分类这些不同种类的海鲜。这需要对海鲜的细微特征和形态有深入的了解,以提高标注的准确性和数据集的质量,为后续的机器学习训练提供可靠的基础。

包含581张海鲜图片,数据集中包含以下几种类别
- 螃蟹:通常指海洋或淡水中的甲壳类动物,是一种常见的海鲜食材。
- 龙虾:大型甲壳动物,被广泛用作高级海鲜食材。
- 虾:小型甲壳类动物,是一种常见的海鲜食材,具有丰富的蛋白质和营养价值。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
数据清洗:去除重复、无效或有噪声的数据。
图像调整:图像调整是数据预处理的第一步。所有图像需统一调整为相同的尺寸(例如640x640像素),以确保输入数据的一致性。具体过程包括:
- 缩放:根据需要缩放图像,保持宽高比,避免失真。
- 填充:对于长宽比不同的图像,使用边缘填充或黑色填充,确保图像保持指定大小。
数据增强:通过对原始图像进行多种变换,增加数据集的多样性,提升模型的泛化能力。常用的增强方法包括随机旋转图像一定角度、水平或垂直翻转图像、随机裁剪图像的一部分,以及调整图像的亮度和对比度,以模拟不同的光照条件,从而增强模型的鲁棒性。
数据集划分:将数据集划分为训练集、验证集和测试集,以便进行有效的模型训练和评估。常见的划分比例为:
- 训练集(70%):用于模型的训练,提供足够多的样本以学习特征。
- 验证集(20%):用于调优模型超参数,监控模型在训练过程中的表现,避免过拟合。
- 测试集(10%):用于最终评估模型性能,确保模型在未见数据上的准确性。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络(CNN)是一种深度学习模型,广泛应用于图像识别、目标检测和计算机视觉等领域。CNN通过模拟人类视觉系统的方式,自动提取图像中的特征,具有强大的图像处理能力。CNN的基本架构通常包括以下几种层:
- 卷积层:这是CNN的核心,利用卷积操作提取输入图像的局部特征。每个卷积核(滤波器)在输入图像上滑动,生成特征图。通过多个卷积层,CNN可以逐层提取更复杂的特征。
- 激活层:常用的激活函数是ReLU,它在卷积层后引入非线性,帮助网络学习更复杂的模式。
- 池化层:池化操作用于减少特征图的尺寸,降低计算复杂度,同时保留重要特征。常见的池化方法是最大池化(Max Pooling),它取每个区域的最大值。
- 全连接层:在经过多个卷积和池化层后,特征图会被展平并输入到全连接层,负责将提取的特征映射到最终的分类结果。

卷积神经网络(CNN)具有自动提取重要局部特征的能力,这一特点显著减少了传统手工特征提取方法的复杂性。传统方法往往需要专家知识和大量的时间来选择和设计特征,这不仅耗时且容易受主观因素影响。相比之下,CNN通过多层卷积操作,能够自动学习最有助于分类的特征。每一层卷积网络都能从原始图像中提取不同层次的特征。例如,初始层通常捕捉到基本的边缘和线条,而后续层则能够识别更复杂的形状和纹理。这种层次化的特征提取使得CNN在处理各种视觉任务时具有更强的适应性和准确性。
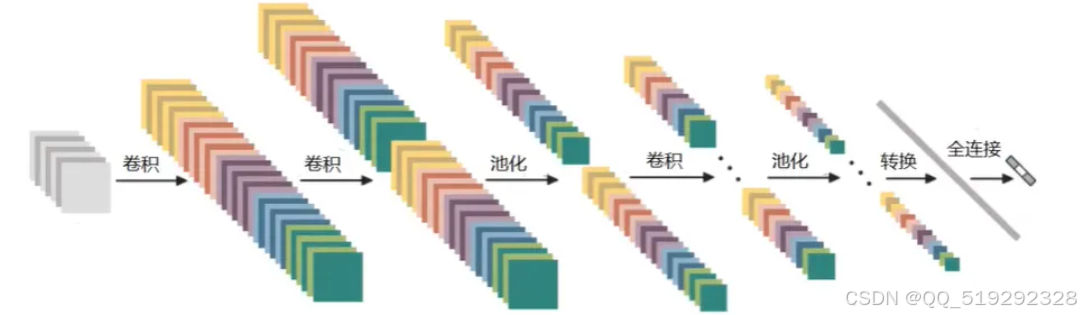
随着网络深度的增加,CNN能够捕捉到图像中越来越复杂的特征,形成丰富的特征表示。这种深层特征表示不仅提高了分类和识别的准确性,还使得网络能够有效处理多样化的输入数据。CNN在图像分类任务中表现尤为突出,如在ImageNet等大型数据集上的应用,显示了其在识别数千种物体类别时的优越性能。此外,CNN的特征提取能力还可用于迁移学习,将在一个任务中学到的特征应用于其他相关任务,从而节省训练时间并提高性能。这种灵活性使得CNN在诸如目标检测、图像分割和人脸识别等多个领域的应用中展现出广泛的潜力和价值。
3.2模型训练
步骤一:定义数据集和模型配置文件
在 YOLO 项目中,首先需要定义数据集的类别和模型的配置文件。创建并编辑 obj.names 文件以存储类别名称。
# 创建并编辑 obj.names 文件
echo "Crab" > obj.names
echo "Lobster" >> obj.names
echo "Shrimp" >> obj.names
# 设置类别数
sed -i 's/CLASSES = 80/CLASSES = 3/' yolov3.cfg
# 设置 anchors
sed -i 's/anchors =/anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326/' yolov3.cfg
# 设置 filters
let FILTERS="((CLASSES + 5) * 3)"
sed -i "s/filters =/filters = $FILTERS/" yolov3.cfg
步骤二:生成标注文件和训练列表
使用标注工具对数据集进行标注,生成每个对象的类别和边界框信息,并保存为相应的标注文件(如 .txt 文件)。然后,将标注文件的路径组织成训练列表文件,每行包含图像路径和对应的标注文件路径,以便模型训练时能够读取并使用这些信息。
# 假设每个标注文件包含类别、边界框信息,保存为 txt 格式
# 可以使用脚本将标注信息转换为 YOLO 格式
# 假设每个标注文件的格式为 "<类别> <中心点X> <中心点Y> <宽度> <高度>"
# 例如: "0 0.5 0.5 0.3 0.4" 表示一个类别为0的物体,中心点坐标为(0.5, 0.5),宽度为0.3,高度为0.4
# 生成训练列表文件
find /path/to/images -name '*.jpg' > image_list.txt
find /path/to/annotations -name '*.txt' > annotation_list.txt
# 将标注信息转换为 YOLO 格式的函数
convert_to_yolo_format() {
local input_file="$1"
local output_file="$2"
while IFS= read -r line; do
class=$(echo $line | awk '{print $1}')
centerX=$(echo $line | awk '{print $2}')
centerY=$(echo $line | awk '{print $3}')
width=$(echo $line | awk '{print $4}')
height=$(echo $line | awk '{print $5}')
# 转换为 YOLO 格式:"<类别> <中心点X> <中心点Y> <宽度> <高度>"
echo "$class $centerX $centerY $width $height" >> $output_file
done < $input_file
}
# 对每个标注文件进行转换
while IFS= read -r annotation_file; do
output_file="$(basename $annotation_file .txt)_yolo.txt"
convert_to_yolo_format $annotation_file $output_file
done < annotation_list.txt
# 生成最终的训练列表文件
paste -d' ' image_list.txt *_yolo.txt > train.txt步骤三:训练模型和评估调优
下载 Darknet 的预训练权重,作为 YOLO 模型的初始权重。使用生成的数据集、配置文件和预训练权重,开始训练 YOLO 模型。训练完成后,对模型进行评估和调优,调整超参数以提高模型性能,确保其能够准确识别螃蟹、龙虾和虾这三类海鲜动物。
# 下载 Darknet 预训练权重
wget https://pjreddie.com/media/files/yolov3.weights
# 开始训练 YOLO 模型
./darknet detector train data/obj.data cfg/yolov3.cfg yolov3.weights | tee training_log.txt
# 模型训练完成后,进行评估和调优
# 可以使用验证集进行评估,调整超参数以提高模型性能
# 评估模型
./darknet detector map data/obj.data cfg/yolov3.cfg backup/yolov3_last.weights
# 调整超参数
# 例如,调整学习率和迭代次数
./darknet detector train data/obj.data cfg/yolov3.cfg backup/yolov3_last.weights -map | tee tuning_log.txt
# 查看模型预测
./darknet detector test data/obj.data cfg/yolov3.cfg backup/yolov3_last.weights -ext_output < test_image_path.jpg > predictions.txt四、总结
数据集包含了三种主要类别:螃蟹、龙虾和虾。这个数据集旨在为计算机视觉和深度学习领域的研究人员提供训练和评估海鲜识别模型的资源。螃蟹具有硬壳和十足,龙虾身体细长并带有大型钳爪,而虾通常是小型海鲜,具有扁平的身体和明显的触须。通过这个数据集,研究人员可以开发自动化海鲜分类系统,促进海鲜产业的质量控制,并为生物学研究提供支持,以推动海洋生物多样性的保护和了解。这个数据集的研究和应用有助于推动计算机视觉技术在海洋保护和食品行业中的发展和应用。

















 1487
1487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









