







一、背景意义
随着对鲨鱼生态和生物多样性的关注加深,鲨鱼牙齿的分类和识别成为海洋生物研究中的一个重要课题。鲨鱼牙齿不仅在古生物学研究中具有重要意义,帮助科学家了解古代鲨鱼的演化历程,还在生态学、考古学和生物保护等领域发挥着重要作用。随着深度学习技术的发展,利用计算机视觉和深度学习算法对鲨鱼牙齿进行自动识别和分类,能够显著提高研究效率,并为相关领域提供有力的数据支持。
二、数据集
2.1数据采集
首先,需要大量的鲨鱼牙齿图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示鲨鱼牙齿特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
鲨鱼牙齿数据集涵盖了多个复杂分类,包括鹰鱼、灰鲨、巨齿鲨、斜牙鲨和沙虎等多样海洋生物。标注这些分类需要深入了解每种生物的牙齿特征,如形状、大小、纹理等,以确保准确标注。由于牙齿在形态上存在微小差异,标注过程需要高度专业知识和技术技能,提高了标注的复杂度和工作量。
标注鲨鱼牙齿数据集需要耗费大量时间和精力,标注员需具备海洋生物学和牙齿形态学方面的专业知识,以确保准确标注。细微特征的标注、多样性挑战和标注一致性要求增加了标注的复杂性。标注员需要细致入微地分析每个分类的特征,保持标注的一致性和准确性,使数据集成为深度学习和计算机视觉项目的可靠基础。
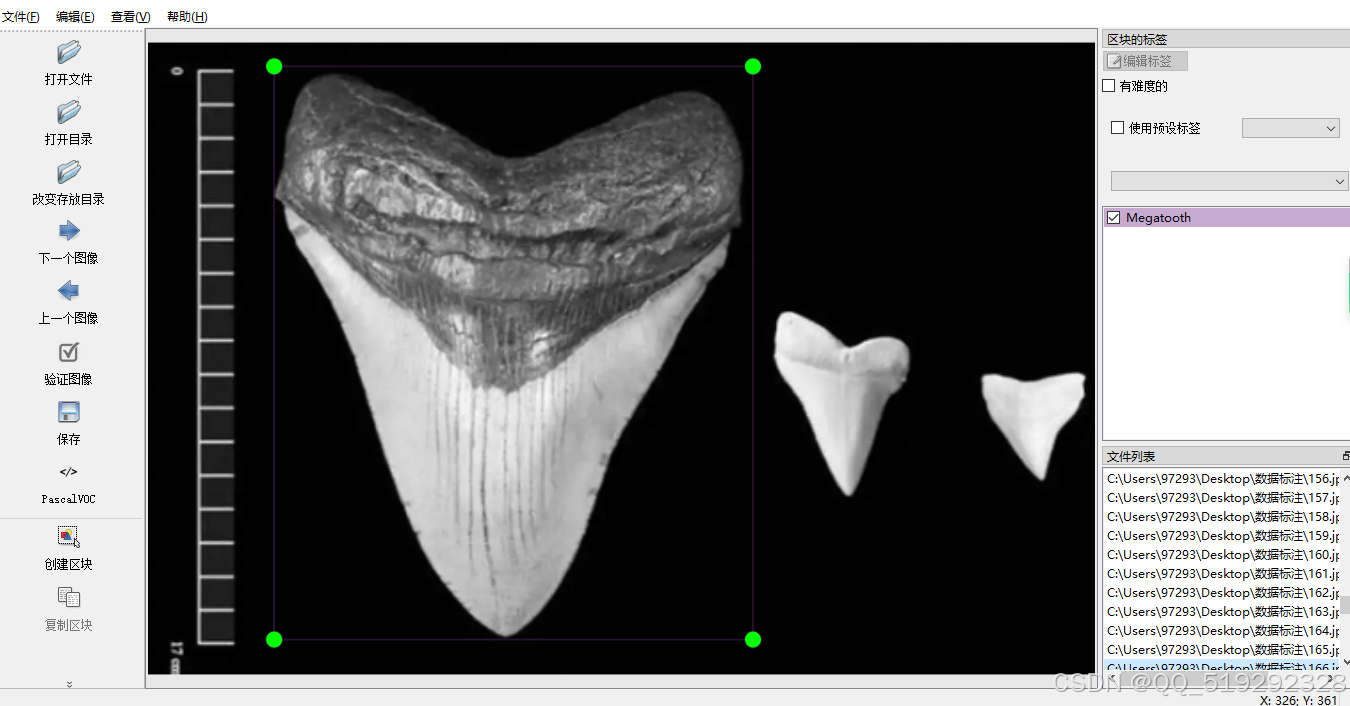
包含1090张鲨鱼牙齿图片,数据集中包含以下几种类别
- 鹰鳐:水族馆中的一种鱼类,具有独特的鹰状外形。
- 灰鲨:水族馆中的一种灰色的鲨鱼品种。
- 巨齿:水族馆中的一种鱼类,以其巨大的牙齿而著名。
- 斜齿:水族馆中的一种鱼类,牙齿呈斜角状。
- 沙虎鲨:水族馆中的一种鲨鱼,常栖息于沙海中。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 数据清洗:去除重复、无效或有噪声的数据。
- 数据标准化:例如,对图像进行尺寸调整、归一化,对文本进行分词和清洗。
- 数据增强:通过旋转、缩放、裁剪等方法增加数据的多样性,防止模型过拟合。
- 数据集划分:将数据集划分为训练集、验证集和测试集,确保模型的泛化能力。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络(CNN)通过多层结构逐步提取图像特征,主要包括以下几个关键步骤:
- 特征提取:CNN通过卷积层提取图像的局部特征,如边缘、纹理和形状。卷积核在输入图像上滑动,生成特征图,从而捕捉不同区域的信息。
- 降维处理:通过池化层(如最大池化)减少特征图的尺寸,降低计算复杂度,提高模型的鲁棒性,保留重要特征信息。
- 非线性激活:激活函数(如ReLU)被引入以增强模型的非线性,帮助模型学习复杂的特征表示。
- 全连接层:在网络的末端,经过卷积和池化后的特征被整合到全连接层中,进行最终的分类或回归,输出每个类别的概率。
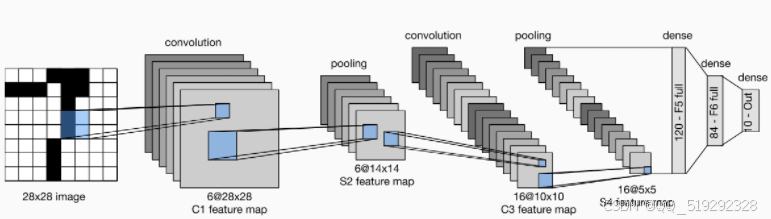
CNN的基本结构通常包含以下几个层:
- 输入层:接收原始图像数据,通常为三维张量(宽度、高度、通道数)。
- 卷积层:通过卷积操作提取图像特征,每个卷积核在输入图像上滑动,计算局部区域的加权和,生成特征图。
- 激活层:使用非线性激活函数(如ReLU)引入非线性,增强模型的表达能力。
- 池化层:通过下采样减少特征图的尺寸,降低计算量并提高模型的泛化能力。
- 全连接层:将提取的特征映射到类别标签,进行最终的分类。

卷积神经网络(CNN)在鲨鱼牙齿监测系统中的优势体现在多个方面。首先,CNN能够自动从原始图像中学习特征,无需手动设计特征提取方法,这使其在处理鲨鱼牙齿的多样性和复杂性时更加高效。其次,CNN具备平移不变性,能够有效识别不同姿态和位置的鲨鱼牙齿,确保识别的准确性。此外,通过参数共享和局部连接,CNN显著减少了模型的参数数量,从而提高了训练和推理的效率,使其成为处理复杂图像数据的理想选择。
3.2模型训练
步骤1:数据预处理
在这一步骤中,需要将准备好的鲨鱼牙齿数据集进行预处理,包括数据增强、标签转换等。
# 数据增强示例
from imgaug import augmenters as iaa
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 随机水平翻转
iaa.Affine(rotate=(-10, 10)) # 随机旋转
])
# 应用数据增强
image_aug, bbs_aug = seq(image=image, bounding_boxes=bbs)
步骤2:模型训练
在这一步骤中,需要使用准备好的数据集对 YOLO 模型进行训练。
# YOLO 模型训练示例
import darknet
config_file = "yolov3.cfg"
data_file = "obj.data"
weights = "yolov3.weights"
network, class_names, class_colors = darknet.load_network(config_file, data_file, weights)
步骤3:模型评估
在这一步骤中,您可以评估已经训练好的模型,检查其性能和准确性。
# 模型评估示例
detections = darknet.detect_image(network, class_names, image_path)
for label, confidence, bbox in detections:
print(f"Detected: {label} with confidence {confidence}")
步骤4:模型推理
在这一步骤中,您可以使用训练好的模型进行推理,检测鲨鱼牙齿数据集中的目标。
# 模型推理示例
image_path = "test_image.jpg"
detections = darknet.detect_image(network, class_names, image_path)
for label, confidence, bbox in detections:
print(f"Detected: {label} with confidence {confidence}")四、总结
鲨鱼牙齿数据集包含了多个分类,涵盖了鹰鱼、灰鲨、巨齿鲨、斜牙鲨和沙虎等多样海洋生物。这些分类反映了海洋生态系统中不同鲨鱼及相关物种之间的多样性和特征。通过对这些分类进行研究和标注,可以深入了解每种生物的牙齿形态特征,从而为海洋生物学研究和生态保护提供重要的数据支持。
标注鲨鱼牙齿数据集是一项具有挑战性的任务,因为不同分类之间存在着复杂的形态差异和细微的特征变化,需要标注员具备高度专业知识和技术技能。这些数据的标注将为机器学习和计算机视觉项目提供基础,例如使用YOLO等目标检测算法进行鲨鱼牙齿的识别和分类,进一步推动了对海洋生物多样性和生态系统的理解和保护工作。

















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









