







一、背景意义
在当今社会,数字仪表广泛应用于工业、家庭和商业等多个领域,成为监测和管理电能、时间等重要信息的关键工具。随着科技的不断发展,数字仪表正在逐步向智能化和自动化转型,传统的人工读取方式逐渐被自动识别技术所取代。这不仅提高了信息获取的效率,减少了人为错误,还为智能家居、智慧城市等新兴应用提供了基础支持。数字仪表的准确识别和读取对于用户理解和管理日常用电、能源消耗等信息至关重要,直接影响到电费的计算和资源的有效利用。
二、数据集
2.1数据采集
数据采集是制作数字仪表识别数据集的第一步,主要包括以下几个方面:
- 数据来源确定:选择合适的方式进行数据采集,例如通过实地拍摄、网络爬虫或搜索已有开放数据集等。对于数字仪表,建议在不同环境下拍摄多种类型的仪表,以确保数据的多样性。
- 设备选择:使用高分辨率的相机或智能手机拍摄数字仪表的显示,确保图像清晰且细节丰富。拍摄时应注意光线、角度及距离,尽量避免反光和阴影对数字显示的干扰。
- 样本数量:为了保证数据集的有效性,建议每个类别(如数字“0”-“9”,小点,千瓦时等)收集至少数百张图像,这样能够增强模型的学习能力和泛化能力。
数据清洗的目的是提高数据集的质量,去除无用或低质量的数据:
- 去除重复样本:检查数据集中的重复图像,删除重复的样本,以减少训练过程中的偏差。
- 剔除低质量图像:挑选清晰、没有模糊或失真的图像,剔除因为光线不足、过曝或拍摄角度不当导致的低质量图像,从而确保每张图像的可用性。
- 标记错误修正:在数据采集过程中,可能会对数字的分类产生误判,因此需要仔细检查每张图像的标签,确保每个样本的标签准确无误。
2.2数据标注
数据标注是将图像与相应的类别进行关联,通常包括以下步骤:
- 选择标注工具:可以使用LabelImg等开源标注工具进行数据标注。该工具支持多种输出格式,适合目标检测任务。
- 类别定义:在标注工具中设置对应的类别,包括数字“0”-“9”、小点和千瓦时(kWh),确保标注的一致性。
- 框选目标:使用鼠标框选每张图像中的数字或小点,确保准确标注每个数字的边界,特别是在图像中数字和小点可能重叠的情况下,这需要特别注意。
使用LabelImg进行数据集标注的过程是相对复杂的,尤其是在处理大量图像时,工作量也相对较大。首先,用户需要下载并安装LabelImg工具,安装后打开软件并导入待标注的图像。接下来,用户需逐一打开每张图像,使用鼠标框选出显示的数字及小点,并为其指定相应的类别标签。由于数字仪表的显示可能会受到反光或阴影的影响,特别是在不同的环境和光线条件下,标注工作需要极大的耐心和细致的观察力。此外,在标注过程中,用户可能会遇到数字边界模糊、重叠等复杂情况,这增加了标注的难度和工作量。因此,在整个标注过程中,用户需要投入大量时间和精力,以确保每个样本的标注准确无误。
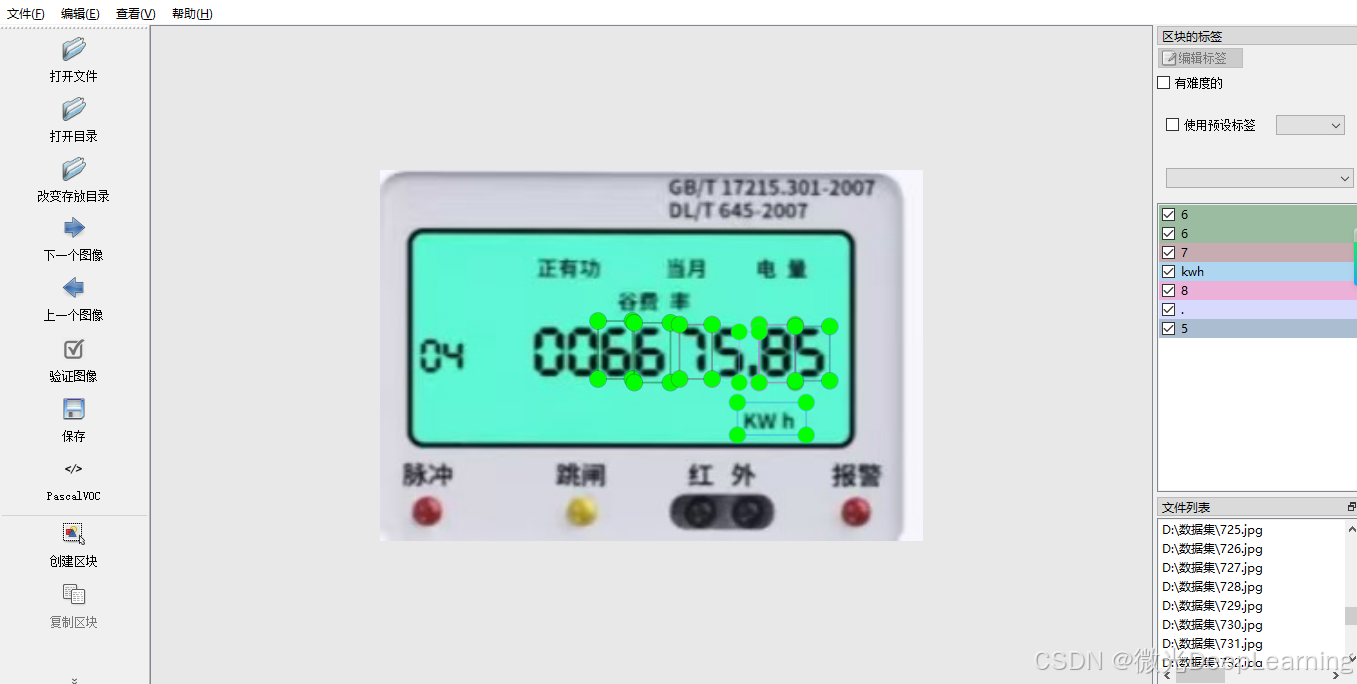
电表数字图片数据集中包含以下几种类别:
- 点:表示数字仪表上的小点,通常用于分隔数字或作为小数点,帮助用户准确读取数值。
- 零:代表数字“0”,在数字显示中起到重要的填补作用,确保其他数字的正确位置。
- 一:代表数字“1”,通常用于表示电量、时间或其他计量单位中的最小值。
- 二:代表数字“2”,在仪表中常用于表示二次电量、时间的第二位数字等。
- 三:代表数字“3”,用于表示电表读数中的第三位数字或三相电的相关数据。
- 四:代表数字“4”,在电量或其他计量单位中,常用于表示四分之一的计量。
- 五:代表数字“5”,在计量中常表示五分之一的电量或重要的阈值。
- 六:代表数字“6”,在电表中通常用于表示第六位数字,可能与用电量相关。
- 七:代表数字“7”,在数字显示中用于表示七分之一的计量,常见于电量读数。
- 八:代表数字“8”,通常用于表示电表中较高的读数或重要的电能计量。
- 九:代表数字“9”,在仪表中常用于表示接近满量程的读数,标志着重要的高值。
- 千瓦时(kwh):表示电能的单位,帮助用户理解和计算用电量的消耗,至关重要于电费的核算。
2.3数据预处理
数据预处理是为模型训练做好准备的重要步骤,通常包括以下几个方面:
- 数据增强:使用旋转、缩放、翻转、裁剪等技术来增加数据的多样性,提升模型的泛化能力。对于数字仪表的图像,适当的旋转和缩放能够模拟不同的拍摄条件。
- 标准化:对图像数据进行归一化处理,将像素值调整到0到1的范围内,有助于加速模型的收敛。
- 划分数据集:将数据集拆分为训练集、验证集和测试集,通常按70%:20%:10%的比例。这有助于后续的模型训练和评估,确保模型的可靠性。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络(CNN)是深度学习领域的一种重要架构,特别适用于图像处理和目标检测任务。CNN的基本组成结构包括输入层、多个卷积层、池化层和全连接层。卷积层通过卷积核对输入图像进行特征提取,能够捕捉图像中的局部特征;池化层则以减少特征图的维度,增强模型的鲁棒性。通过多层次的卷积操作,CNN能够有效学习到图像的复杂特征,从而在后续的全连接层中进行分类和回归任务。

在算法模型中,CNN的优势体现在多个方面。首先,CNN能够自动学习特征,减少了对手动特征提取的依赖,这使得模型能够适应不同的输入数据。其次,随着网络深度的增加,CNN能够逐层提取更为抽象的特征,增强了模型的表达能力。此外,CNN在处理图像数据时具有较强的平移不变性,能够有效应对不同角度和尺度的目标,从而提高检测的准确性。

YOLOv5是一种新颖的目标检测算法,其设计理念是将目标检测视为一个回归问题,通过单个神经网络直接预测目标的边界框和类别。YOLOv5的结构主要包括特征提取网络(如CSPNet)、目标检测头和后处理模块。特征提取网络使用了卷积神经网络以提取图像特征,随后通过检测头生成多个候选框,并利用非极大值抑制算法筛选出最终的检测结果。YOLOv5通过一次前向传播即可完成目标检测任务,使得其在速度和效率上具有明显优势。YOLOv5在算法模型中的优势主要体现在检测速度和准确性。由于其单阶段检测的特点,YOLOv5能够实现实时检测,适用于动态场景下的应用。此外,YOLOv5采用了多尺度特征融合的策略,能够对不同大小的目标进行有效检测,尤其在处理复杂场景时表现优异。YOLOv5还提供了良好的可扩展性,用户可以根据实际需求调整网络结构,以优化检测性能。
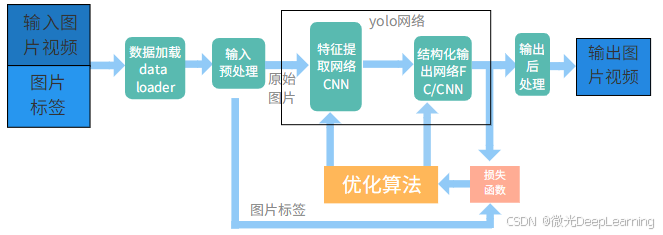
结合CNN和YOLOv5的优势,可以构建一个更为优异的数字仪表识别算法模型。该模型首先利用CNN进行特征提取,以捕捉七段管显示中的细节特征,例如数字的边缘和形状特征。接着,将提取到的特征输入到YOLOv5中进行目标检测,这样可以在保持高效检测速度的同时,进一步提高数字识别的准确性。为了进一步优化模型性能,可以引入注意力机制,以增强模型对重要特征的关注,从而提升在复杂背景下的识别能力。这种结合不仅提升了检测精度,还能有效应对多样化的输入数据。
3.2模型训练
-
环境准备与依赖安装:在开发YOLOv5项目之前,首先需要准备好开发环境。可以使用Anaconda创建一个新的虚拟环境,并安装Python 3.x版本。接着,通过以下命令安装YOLOv5所需的依赖库:
conda create -n yolov5 python=3.8 conda activate yolov5 pip install -r requirements.txt -
数据集准备:将自制的数字仪表数据集划分为训练集、验证集和测试集。通常按70%:20%:10%的比例进行划分。可以使用以下代码示例来处理数据集:
import os import shutil import random def split_dataset(source_dir, train_dir, val_dir, test_dir, train_ratio=0.7, val_ratio=0.2): images = os.listdir(source_dir) random.shuffle(images) train_size = int(len(images) * train_ratio) val_size = int(len(images) * val_ratio) for i, image in enumerate(images): src_path = os.path.join(source_dir, image) if i < train_size: shutil.copy(src_path, train_dir) elif i < train_size + val_size: shutil.copy(src_path, val_dir) else: shutil.copy(src_path, test_dir) split_dataset('digits_images', 'train', 'val', 'test') -
模型配置与训练:在训练模型之前,需要配置YOLOv5的参数和超参数。创建一个
data.yaml文件,定义类别和数据路径,然后使用以下命令进行训练:python train.py --data data.yaml --cfg yolov5s.yaml --weights '' --img-size 640 --batch-size 16 --epochs 50 -
模型评估与调优:训练完成后,需要对模型的性能进行评估。使用验证集评估模型的检测效果,并根据评估结果进行超参数调优。代码示例:
from sklearn.metrics import precision_score, recall_score # 计算精确率和召回率 y_true = [...] # 真实标签 y_pred = [...] # 模型预测标签 precision = precision_score(y_true, y_pred, average='weighted') recall = recall_score(y_true, y_pred, average='weighted') print(f'Precision: {precision}, Recall: {recall}') -
部署与应用:部署训练好的模型到实际应用中。例如,可以开发一个实时检测系统,对视频流进行处理,识别数字仪表上的显示。以下是实时检测的代码示例:
import cv2 import torch model = torch.hub.load('ultralytics/yolov5', 'custom', path='best.pt') # 加载训练好的模型 cap = cv2.VideoCapture(0) # 使用摄像头 while True: ret, frame = cap.read() if not ret: break results = model(frame) # 进行检测 results.render() # 绘制检测结果 cv2.imshow('Digital Meter Recognition', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()
四、总结
针对数字仪表识别问题,构建了一个自制的数据集,涵盖了“0”-“9”数字、小点以及千瓦时(kWh)等重要类别。通过对大量图片的实地采集、清洗和标注,确保了数据集的多样性和可靠性。在数据集制作过程中,采用了数据增强和预处理等技术手段,为后续的模型训练奠定了坚实基础。结合卷积神经网络(CNN)和YOLOv5的优势,开发了一个高效的数字仪表识别算法模型,使得在不同环境下的数字读取变得更加准确和快速。

















 4241
4241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









