






前言:当我们进行机器学习时,如果想识别手势信息,比较好的办法就是把手部信息给裁剪出来。这样在进行模型预测时,通过把手部裁剪部分进行预测就可以大大提高准确率。所以应该如何进行手部裁剪呢?
在这里我们将介绍开源模型mediapipe,其通过把手部信息用21个坐标来确定手部,就像这样

那么,我们想知道他存储手部这些信息用的什么数据结构呢,看下面代码:
results.multi_hand_landmarks = [
# 第一只手的关键点列表(21个Landmark)
<NormalizedLandmarkList landmarks=[
<NormalizedLandmark x=0.5 y=0.3 z=-0.1>,
<NormalizedLandmark x=0.6 y=0.4 z=-0.2>,
... # 共21个
]>,
# 第二只手的关键点列表
<NormalizedLandmarkList landmarks=[
<NormalizedLandmark x=0.2 y=0.7 z=-0.3>,
...
]>
]通过这个输出信息我们可以看到multi_hand_landmarks通过列表来表示一个手部的信息,如21个关键点的坐标,而我们可以通过遍历其中的landmark列表来获取21个坐标信息,其中每一个坐标信息存储均通过归一化。
tips:其中的z表示的是点位离摄像头的距离,不知道之前一直在想手部怎么建立三维坐标。。。
好的,现在我们要实现框选手部信息就会非常简单,通过以下代码就可以实现:
import cv2
import mediapipe as mp
# mediapipe初始化
mp_hands = mp.solutions.hands
hands = mp_hands.Hands() # 采用默认配置
cap = cv2.VideoCapture(0)
padding = 20
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break # 处理视频读取错误
results = hands.process(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
h, w, _ = frame.shape
if results.multi_hand_landmarks:
# 取第一个检测到的手
hand_landmarks = results.multi_hand_landmarks[0]
# 收集所有关键点的归一化坐标并转换为像素坐标
# for lm in hand_landmarks.landmark为遍历手中的每一个坐标点
x_coords = [int(lm.x * w) for lm in hand_landmarks.landmark]
y_coords = [int(lm.y * h) for lm in hand_landmarks.landmark]
# 计算包围盒边界(添加padding)
#x_min :左边界
#y_min :上边界
#x_max :右边界
#y_max :下边界
x_min = max(0, min(x_coords) - padding)
y_min = max(0, min(y_coords) - padding)
x_max = min(w, max(x_coords) + padding)
y_max = min(h, max(y_coords) + padding)
# 绘制包围盒
cv2.rectangle(frame, (x_min, y_min), (x_max, y_max), (0, 0, 255), 2)
cv2.putText(frame, f"{x_min}", (x_min-20, y_min-8), cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,255),2)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
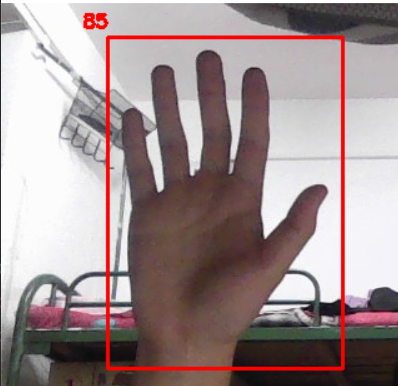
cv2.destroyAllWindows()最后就可以实现下图这种手部信息框选(这里我输出了左上角的边距信息,可以自己DIY,这里是基于笔记本摄像头的):

















 1462
1462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









