







用AI模仿写杰伦歌词是一种什么体验!!!
大家好我是朱同学,一名在校大学生。
最近,做了一个关于循环神经网络的小demo如何学习杰伦的歌词去创作。感受人工智能的魅力!
关于人工智障创作的歌词我们在文章的最后揭晓!
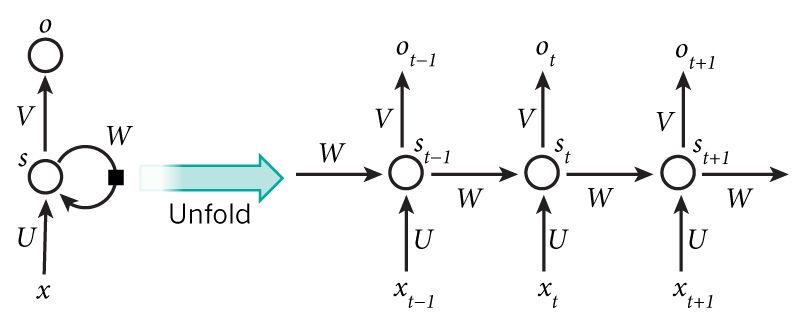
首先给大家介绍一下啥是循环神经网络(RNN, Recurrent Neural Networks)简称RNN
RNN通过使用带自反馈的神经元,能够处理任意长度的时序数据。
什么是时序数据
时序数据,即时间序列数据,按时间维度顺序记录且索引的数据。像智慧城市、物联网、车联网、工业互联网等领域各种类型的设备都会产生海量的时序数据。这些数据将占世界数据总量的90%以上。便于我们根据时间变化对数据进行分析。
神经网络是一门重要的机器学习技术。神经网络是一门重要的机器学习技术。 神经网络是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术。人脑中的神经网络是一个非常复杂的组织。成人的大脑中估计有1000亿个神经元之多。按时间展开的循环神经网络有反馈功能。
做完简单的介绍我们就开始感受deep learning 这项技术吧!
导入包和需要用的工具我们使用的是pytorch框架
import time
import math
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(torch.__version__)
print(device)
将杰伦的全部歌词放入text文件有5820行


one-hot向量
为了将词表示成向量输入到神经网络。假设词典中的不同字符的数量为N。每个字符已从0到N-1的连续整数值索引一一对应。那么我们创建一个全0的长为N的向量,并将其位置为i的元素设为1。向量长度等于词典大小
In [4]:
def one_hot(x, n_class, dtype=torch.float32):
# X shape: (batch), output shape: (batch, n_class)
x = x.long()
res = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device)
res.scatter_(1, x.view(-1, 1), 1)
return res
x = torch.tensor([0, 2])
one_hot(x, vocab_size)
tensor([[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 1., ..., 0., 0., 0.]])
下面的函数将这样的小批量变换成数个可以输入到网络的形状为(批量大小,词典大小)的矩阵
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def to_onehot(X, n_class):
# X shape: (batch, seq_len), output: seq_len elements of (batch, n_class)
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
X = torch.arange(10).view(2, 5)
inputs = to_onehot(X, vocab_size)
print(len(inputs), inputs[0].shape)
5 torch.Size([2, 1027])
初始化模型参数
接下来初始化模型参数。隐藏单元个数num_hiddens是一个超参数
num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size
print('will use', device)
def get_params():
def _one(shape):
ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32)
return torch.nn.Parameter(ts, requires_grad=True)
# 隐藏层参数
W_xh = _one((num_inputs, num_hiddens))
W_hh = _one((num_hiddens, num_hiddens))
b_h = torch.nn.Parameter(torch.zeros(num_hiddens, device=device, requires_grad=True))
# 输出层参数
W_hq = _one((num_hiddens, num_outputs))
b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, requires_grad=True))
return nn.ParameterList([W_xh, W_hh, b_h, W_hq, b_q])
我用的AMD显卡不支持CUDA,rnm退钱!!!
定义模型
我们根据循环神经网络的计算表达式实现该模型。首先定义__init_rnn_state函数来返回初始化的隐藏状态。使用元组为更便于处理隐藏状态含有多个NDarray的情况。
def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
def rnn(inputs, state, params):
# inputs和outputs皆为num_steps个形状为(batch_size, vocab_size)的矩阵
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
H = torch.tanh(torch.matmul(X, W_xh) + torch.matmul(H, W_hh) + b_h)
Y = torch.matmul(H, W_hq) + b_q
outputs.append(Y)
return outputs, (H,)
做个简单测试来观察输出结果的个数(时间步数),以及第一个时间步的输出层输出的形状和隐藏状态的形状
state = init_rnn_state(X.shape[0], num_hiddens, device)
inputs = to_onehot(X.to(device), vocab_size)
params = get_params()
outputs, state_new = rnn(inputs, state, params)
print(len(outputs), outputs[0].shape, state_new[0].shape)
5 torch.Size([2, 1027]) torch.Size([2, 256])
定义预测函数
函数基于前缀prefix来预测接下来的num_chars个字符。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def predict_rnn(prefix, num_chars, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx):
state = init_rnn_state(1, num_hiddens, device)
output = [char_to_idx[prefix[0]]]
for t in range(num_chars + len(prefix) - 1):
# 将上一时间步的输出作为当前时间步的输入
X = to_onehot(torch.tensor([[output[-1]]], device=device), vocab_size)
# 计算输出和更新隐藏状态
(Y, state) = rnn(X, state, params)
# 下一个时间步的输入是prefix里的字符或者当前的最佳预测字符
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(int(Y[0].argmax(dim=1).item()))
return ''.join([idx_to_char[i] for i in output])
predict_rnn('分开', 10, rnn, params, init_rnn_state, num_hiddens, vocab_size,
device, idx_to_char, char_to_idx)
测试一下predic_rnn函数。我们将根据前缀“分开”创作长度为10个字符的一段歌词。因为模型参数为随机值,所以预测结果也是随机的。
'分开分谢也胸理般呆米女祷'
裁剪梯度
循环神经网络中较容易出现梯度衰减或梯度爆炸。为了应对梯度爆炸,我们可以裁剪梯度。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def grad_clipping(params, theta, device):
norm = torch.tensor([0.0], device=device)
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data *= (theta / norm)
我们通常使用困惑度来评价语言模型的好坏。
定义模型训练函数
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, is_random_iter, num_epochs, num_steps,
lr, clipping_theta, batch_size, pred_period,
pred_len, prefixes):
if is_random_iter:
data_iter_fn = d2l.data_iter_random
else:
data_iter_fn = d2l.data_iter_consecutive
params = get_params()
loss = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
if not is_random_iter: # 如使用相邻采样,在epoch开始时初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
l_sum, n, start = 0.0, 0, time.time()
data_iter = data_iter_fn(corpus_indices, batch_size, num_steps, device)
for X, Y in data_iter:
if is_random_iter: # 如使用随机采样,在每个小批量更新前初始化隐藏状态
state = init_rnn_state(batch_size, num_hiddens, device)
else: # 否则需要使用detach函数从计算图分离隐藏状态
for s in state:
s.detach_()
inputs = to_onehot(X, vocab_size)
# outputs有num_steps个形状为(batch_size, vocab_size)的矩阵
(outputs, state) = rnn(inputs, state, params)
# 拼接之后形状为(num_steps * batch_size, vocab_size)
outputs = torch.cat(outputs, dim=0)
# Y的形状是(batch_size, num_steps),转置后再变成长度为
# batch * num_steps 的向量,这样跟输出的行一一对应
y = torch.transpose(Y, 0, 1).contiguous().view(-1)
# 使用交叉熵损失计算平均分类误差
l = loss(outputs, y.long())
# 梯度清0
if params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
grad_clipping(params, clipping_theta, device) # 裁剪梯度
d2l.sgd(params, lr, 1) # 因为误差已经取过均值,梯度不用再做平均
l_sum += l.item() * y.shape[0]
n += y.shape[0]
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, math.exp(l_sum / n), time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn(prefix, pred_len, rnn, params, init_rnn_state,
num_hiddens, vocab_size, device, idx_to_char, char_to_idx))
模型训练函数有以下不同。
1.使用困惑度评价模型
2.再迭代模型参数前裁剪梯度,
3.对时序数据采用不同采样方法将导致隐藏状态初始化不同。
训练模型并创作歌词
首先,设置模型超参数。我们将根据前缀“分开”和“不分开”分别创作长度为50个字符。每过50个迭代周期百年根据当前训练的模型创作歌词。
num_epochs, num_steps, batch_size, lr, clipping_theta = 250, 35, 32, 1e2, 1e-2
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
随机采样训练模型创作歌词
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, True, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
接下来就是万众期待的创作歌词时刻!!!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jGjJzMPw-1650620764559)(D:\文件\markdown\博客\用AI模仿写杰伦歌词是一种什么体验!!!\65e41dec0f9edd13c4da67893eec7537_t.gif)]
epoch 50, perplexity 72.160167, time 0.95 sec
- 分开 我不要 爱你的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯
- 不分开 你给的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱
epoch 100, perplexity 9.715501, time 0.96 sec
- 分开 一只在停留球 哼有的客栈的 快攻光我 说你说 分数怎么 快人 一截棍酒 戒指在通的溪边 默默激柔
- 不分开永 我有你的生写在西元前 深埋在美索不达米亚平原 用楔个文字 让在人人 温小村外的溪边 默默等待 一
epoch 150, perplexity 2.844710, time 0.98 sec
- 分开 一只在停留 谁让它开的字爱 我不在旁二 三两银够不够 景色入秋 漫天黄潮落棍 哼哼哈兮 快使用双截
- 不分开扫 我叫你爸 你打我妈 这样看吗不屈 一身正气 快使用双我棍 哼生我 不知的人我有红的可爱女人 温柔
epoch 200, perplexity 1.573773, time 0.96 sec
- 分开 一只会停留 谁让它停留的 为什么我女朋友场外加油 你却还让我出糗 从小就耳濡目染 什么刀枪跟棍棒
- 不分开期 我叫能爸 你打我妈 这样对吗干嘛这样 何必让酒牵鼻子走 瞎 说也分比谁都 我想想这你牵 你的手不
epoch 250, perplexity 1.287481, time 1.00 sec
- 分开 一只在停留 谁在它停留的 为什么我女朋友场外加油 你却还让我出糗 从小就耳濡目染 什么刀枪跟棍棒
- 不分开期 我叫你爸 你打我妈 这样对吗干嘛这样 何必让酒牵鼻子走 瞎 说上牵飞谁B 我 想和你看棒球 想这
好家伙,当迭代到250时终于能看了
- 分开 一只在停留 谁在它停留的 为什么我女朋友场外加油 你却还让我出糗 从小就耳濡目染 什么刀枪跟棍棒
- 不分开期 我叫你爸 你打我妈 这样对吗干嘛这样 何必让酒牵鼻子走 瞎 说上牵飞谁B 我 想和你看棒球 想这
人工智障变成人工智能之时。
我们再采用相邻采样训练模型并创作歌词
train_and_predict_rnn(rnn, get_params, init_rnn_state, num_hiddens,
vocab_size, device, corpus_indices, idx_to_char,
char_to_idx, False, num_epochs, num_steps, lr,
clipping_theta, batch_size, pred_period, pred_len,
prefixes)
epoch 50, perplexity 59.663039, time 1.15 sec
- 分开 我想要这 快果我有 你谁不直 如果我的手 我不要再 我有了的 我想我的可活 我知了这 快果我有 你
- 不分开 我不要的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏
epoch 100, perplexity 6.977072, time 1.05 sec
- 分开 一颗一 三颗默 一九四三 再头一碗热粥 配上几斤的牛肉 我说店小二 三两银够不够 景色入秋 漫天用
- 不分开觉 你已经离了 让我该要烦相了命 说 你和 我有 再想啊 是你么 停么些三信片老 干你在 干什么
epoch 150, perplexity 2.139989, time 1.05 sec
- 分开 还是我 三子一枪铜币 我说得 瞎我箱 什么了有 这故看 告诉我 印地安的传说 还真是 瞎透了 什么
- 不分开觉 你已经过了的屋内的砖墙 铺著榉木酿的屋内还弥漫 姥姥当年酿的豆瓣酱 我对著黑白照片开始想像 爸和
epoch 200, perplexity 1.321076, time 1.20 sec
- 分开 问候我 谁打神枪手 巫师 他念念 有词的 对酋长下诅咒 还我骷髅头 这故事 告诉我 印地安的传说
- 不分开觉 你已经离开人来后的砖墙 夕著榉木板的屋内 说著一口吴侬软语的姑娘缓缓走过外滩 消失的 旧时光 一
epoch 250, perplexity 1.198892, time 1.09 sec
- 分开 问候我 三子我枪没片 所真人看着 谁人的美丽 你的完美主义 太彻底 让我连恨都难以下笔 将真心抽离
- 不分开觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉 后知了一个秋 后知后觉 我该好好生活 我该好好生
我们来做个对比将迭代到250的创作拿出来
随机采样训练出来
- 分开 一只在停留 谁在它停留的 为什么我女朋友场外加油 你却还让我出糗 从小就耳濡目染 什么刀枪跟棍棒
- 不分开期 我叫你爸 你打我妈 这样对吗干嘛这样 何必让酒牵鼻子走 瞎 说上牵飞谁B 我 想和你看棒球 想这
相邻采样训练出来
- 分开 问候我 三子我枪没片 所真人看着 谁人的美丽 你的完美主义 太彻底 让我连恨都难以下笔 将真心抽离
- 不分开觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉 后知了一个秋 后知后觉 我该好好生活 我该好好生
大家觉的随机采样好的扣1,相邻采样好的扣2.
觉得自己可以随便唱出来的扣3.
如果大家喜欢的话点个赞!
后续大家喜欢的话,为大家写一下更好玩的AI
















 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











