







数据分析的四阶段
-
提出需求:确定目标
-
准备数据:数据搜集和规整,最花时间(公司内部:办公室相关人员;系统、网站管理员找数据库)(公开信息:互联网爬虫)
-
分析数据
-
描述性分析:指标计算和可视化
-
探索性分析:建模,预测 (设计建模,基础含量高,市场上绝大报告没有)
-
-
总结和建议
1 需求
数据情况
数据由3个单元表组成:
- 订单信息表:
- 订单ID
- 客户ID
- 订单状态
- 1表示正常完成订单
- 0表示未完成订单
- 优惠类型
- 0表示无优惠
- 1表示优惠
- 货物信息表:
- 订单ID
- 货物ID
- 货物名称
- 优惠额度
- 分组显示优惠额度
- 顾客信息表:
- 客户ID
- 登陆次数
- 注册时间(距1970-1-1的秒数)
- 本次购买时间(距1970-1-1的秒数)
- 经验值
- 订单数
需求
-
核心需求:分离在本电商平台购物的无价值用户
- 将平台购物的用户分为正常用户和无价值用户,
- 无价值用户一般指很少购买正常价格商品,大多购买优惠和促销商品的用户
-
其他综合需求:
- 分析下平台的订单情况、商品情况
- 分离正常用户和无价值用户后,进一步分析二者在网站上的行为差异
-
针对性需求1:货物信息表
- 不同优惠额度的订单数量
- 能否根据优惠额度分组可视化产品销量情况
- 能否输出正常价格下销量最好的前10个产品
- 能否输出优惠价格下销量最好的前10个产品
-
针对性需求2:订单信息表
- 能否根据订单状态筛选出已完成订单
- 能否根据客户id和优惠类型分出 正常客户和无价值客户
-
针对性需求3:顾客信息表
- 能否将订单信息表得出的 正常客户和无价值客户列,合并到本表中
- 能否通过客户id列,和正常、无效客户列,得出正常和无效客户分别在:
- 登陆次数,注册时间,本次购买时间,经验值,订单数,等指标下的对比差异?
- 注册和登录时间间隔的对比差异?
产出
要求:根据给定数据和需求,从头完成一个完整版的数据分析报告
并产出下列文档:
- Jupyter-Notebook版
- 综合:用于数据分析项目代码实现和演讲、传播
- HTML网页版
自动生成,用于传播交流 - PDF版
自动生成,用于传播交流
- PPT版
- 手动制作,用于演讲展示
可以使用Jupyter快速导出HTML和PDF版本(chrme打印网页),但效果一般。
如果对效果要求较高,建议导出md格式,自行编辑,再使用markdown导出HTML和PDF
2 数据规整(数据预处理,数据清洗,数据重构)
数据规整是数据分析的预操作,数据分析报告中不体现
# 导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
plt.style.use('seaborn') # 改变图像风格
plt.rcParams['font.family'] = ['Arial Unicode MS', 'Microsoft Yahei', 'SimHei', 'sans-serif'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # simhei黑体字 负号乱码 解决
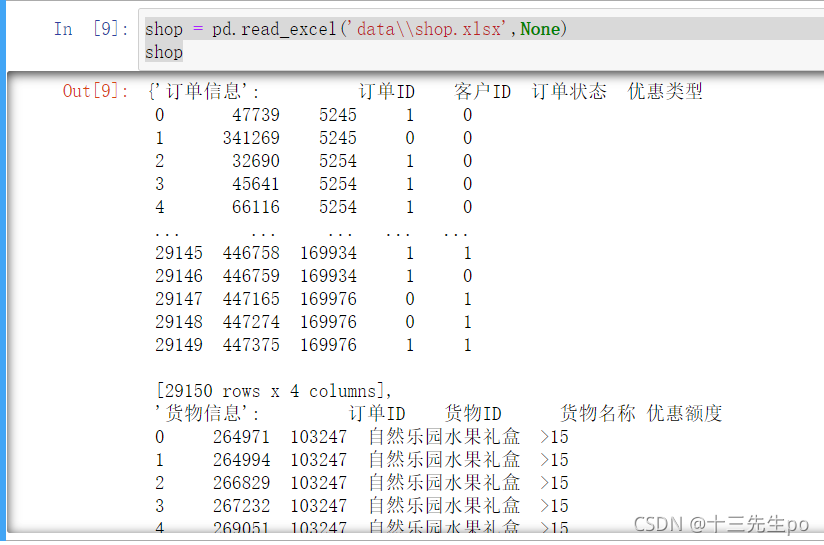
- 读取文件
shop = pd.read_excel('data\\shop.xlsx',None)
shop
- 对不同表格赋予实参
dingdan = shop['订单信息']
huowu = shop['货物信息']
guke = shop['顾客信息']
dingdan
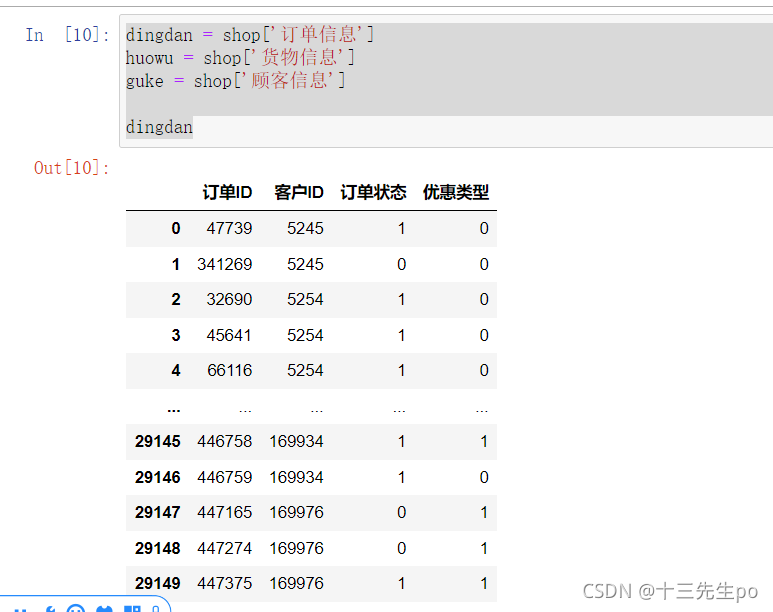
成功读取
2.1 数据预处理
检查数据是否有缺失值和异常列类型
提前自己判断一下每张表每列数据的一般数据类型,如果有异样就检查,例如一列只有数字的,却是object字符串类型(只要有一个字符画,整列都算字符串类型)
# 数据预处理
# 检查数据是否有缺失值和异常列类型
# 提前自己判断一下每张表每列数据的一般数据类型,如果有异样就检查,例如一列只有数字的,却是object字符串类型
dingdan.info()
huowu.info()
guke.info()
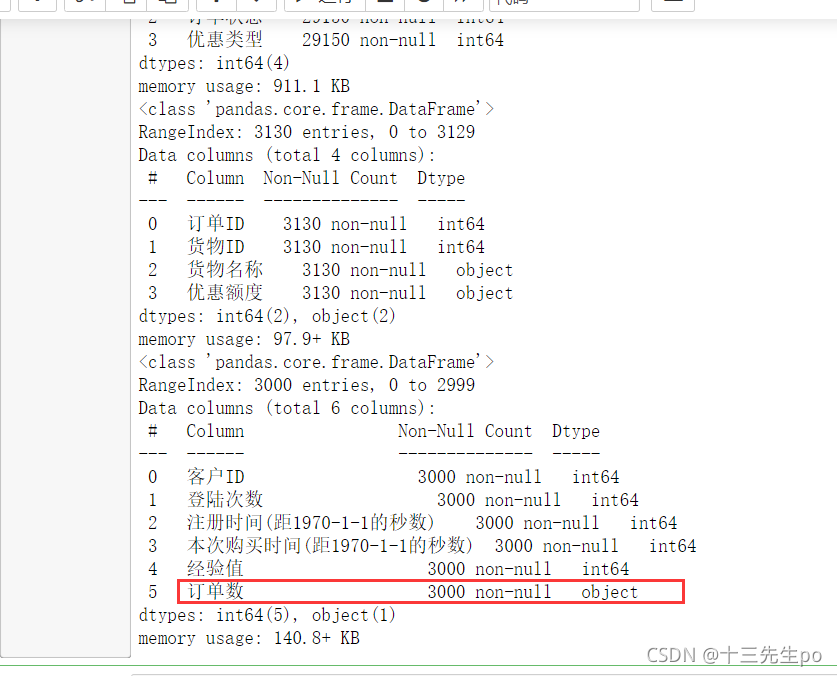
发现顾客信息的订单数一列,通常只有数字值,却是object字符串类型
2.1.1 发现错误的对策
随机找一个值看看有没有问题
# 随机找一个值看看有没有问题
type(guke.loc[0,'订单数']) # 写法1
type(guke.loc[0,'订单数']) == int # 写法2 布尔判断
type(guke.loc[0,'订单数']) == np.int # 写法3 正规写法,这里的int类型不是普通的int类型

如果没有
- 方法1:使用遍历方式找到错误值
# 使用遍历方式找到错误值
for index,row in guke.iterrows():
# print(index) # 表格的行号
# print(row) # 表格的行
# print(type(row)) # <class 'pandas.core.series.Series'>
# print(row['订单数']) # 每行中订单数对应的值
if type(row['订单数']) != np.int:
# 如果不是int类型,输出行号和该行订单数对应的值
print(index,'--',row['订单数'])
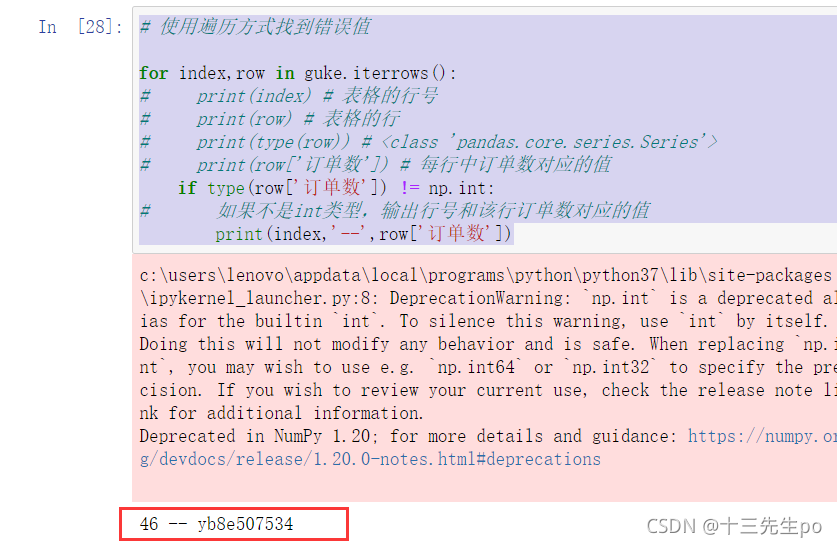
使用索引方法loc查看一下
guke.loc[46]

找到了错误值
- 方法2:使用Pandas自定义函数实现
在自定义函数中遍历对应值,并对判断正确的值返回False值,对判断错误的值返回True值,利用pandas数据结构默认输出True值的特点锁定错误值
# 使用Pandas自定义函数实现
def check(x):
# print(x['订单数']) # 我们发现可以用传入的参数锁定到‘订单数’列
if type(x['订单数']) == np.int:
# 布尔值True和False调转输出,
# 我们可以直接锁定输出True的值,而输出True的值恰恰是错误的值
return False
else:
return True
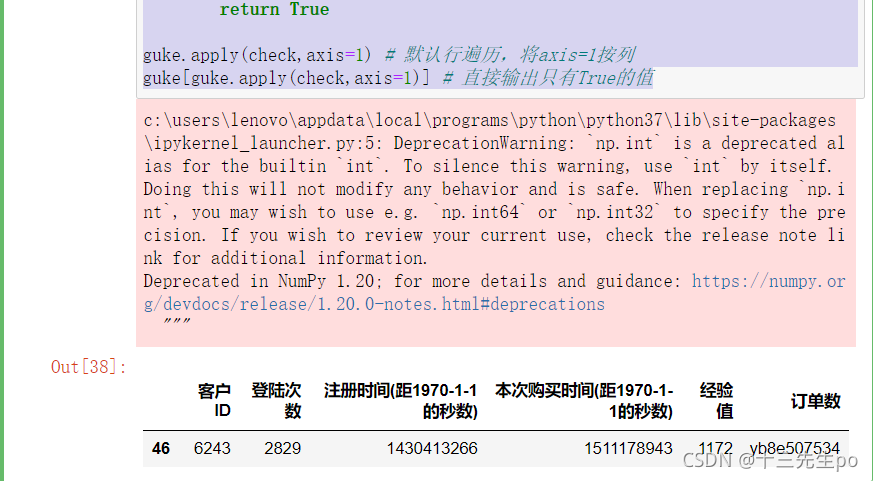
guke.apply(check,axis=1) # 默认行遍历,将axis=1按列
guke[guke.apply(check,axis=1)] # 直接输出只有True的值
- 写法3:自定义函数的匿名函数写法
#匿名函数写法
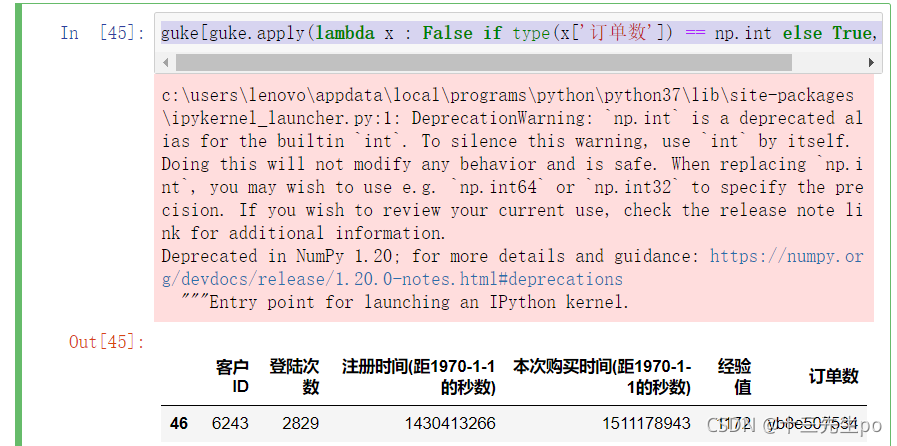
guke[guke.apply(lambda x : False if type(x['订单数']) == np.int else True,axis=1)]
2.1.2 修正缺失值
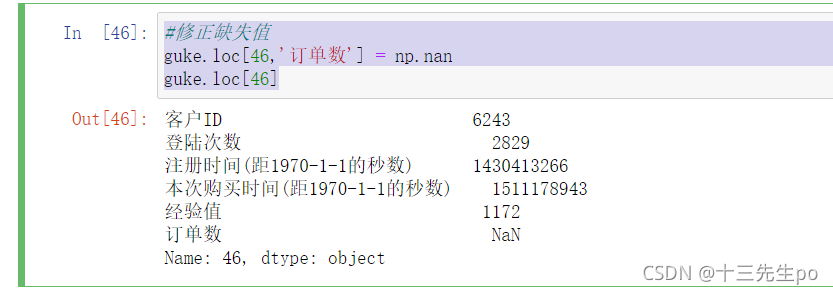
#修正缺失值
guke.loc[46,'订单数'] = np.nan
guke.loc[46]
2.2 修正错误数据
方法1:取平均值/中位数
用经验值列判断错误订单数数据大致范围,取平均值/中位数
特点:通用,套路,无脑操作
# 修正错误数据
# 方法1
# 查看订单数和经验值的关系
guke['订单数'].mean() # 所有客户平均订单数8.448
guke['经验值'].mean() # 所有客户经验值672.35
# 该错误数据的经验值为1172,我们检查一下相似经验值的客户的订单数
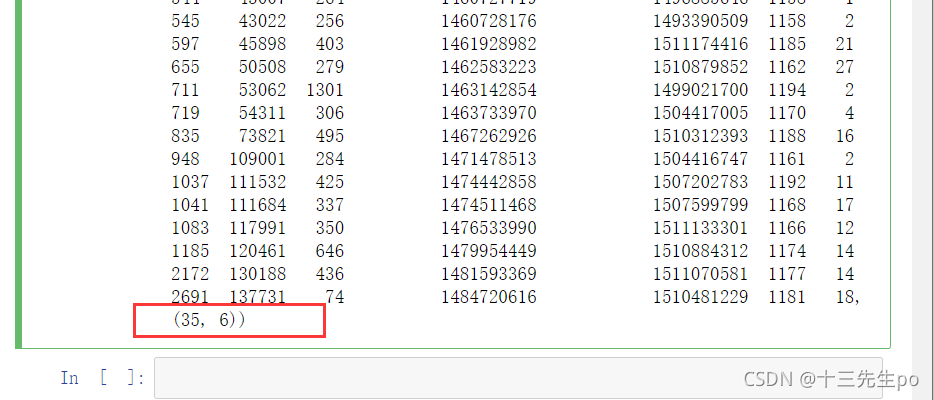
# 发觉区间定在1100-1200之间订单数差距较大,改小范围
# si = guke[(guke['经验值']>1100) & (guke['经验值']<1200)]
si = guke[(guke['经验值']>1150) & (guke['经验值']<1200)]
si,si.shape
# 查询该区间最大值,最小值,平均值
si['订单数'].min(),si['订单数'].max(),si['订单数'].mean(),si['订单数'].median() # 写法1
si.订单数.min(),si.订单数.max(),si.订单数.mean(),si.订单数.median() # 写法2

方法2:从其他表数据设法得出本客户ID订单数据
可能不完全对,但准确率超过自行求值
优点:最精确
缺点:对数据有要求。仅在部分情况下能够使用
需要超凡的洞察力,大力研究已有表格数据
-截取出出错的部分
# 方法2:从其他表数据设法得出本客户ID订单数据
# 截取出出错的部分
guke.loc[45:48]
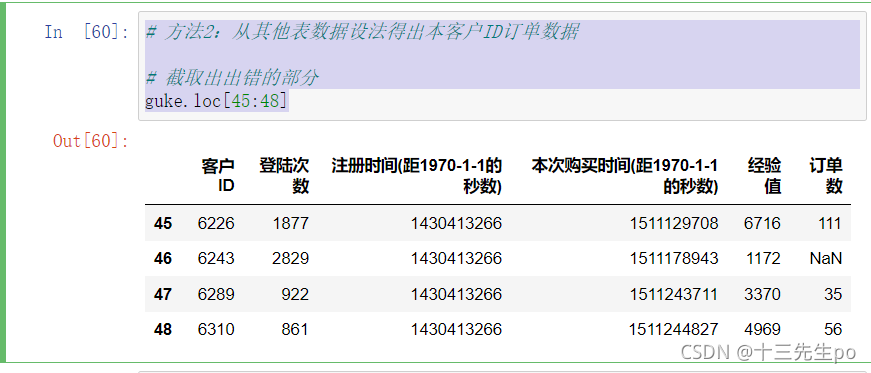
- 对比一下其他表格
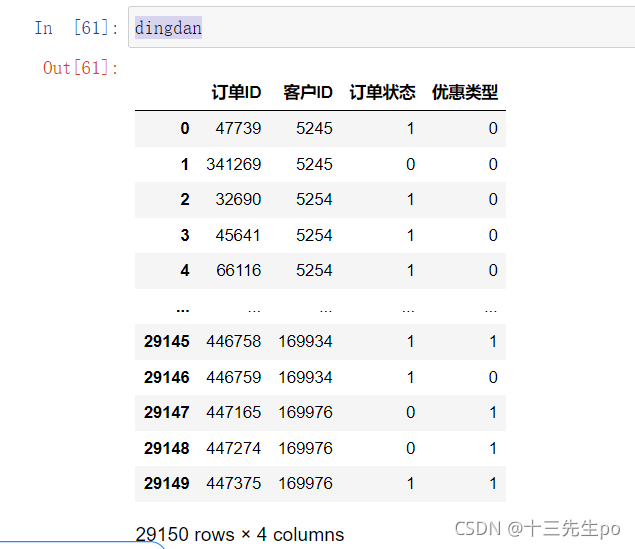
订单表格中的客户id有重合,而且有订单状态计数,尝试将客户id=6226有记录的数据找出来,两个表格对比数据对比一下
# 客户ID 6226 对应的订单数
guke.loc[45, '订单数'] # 111
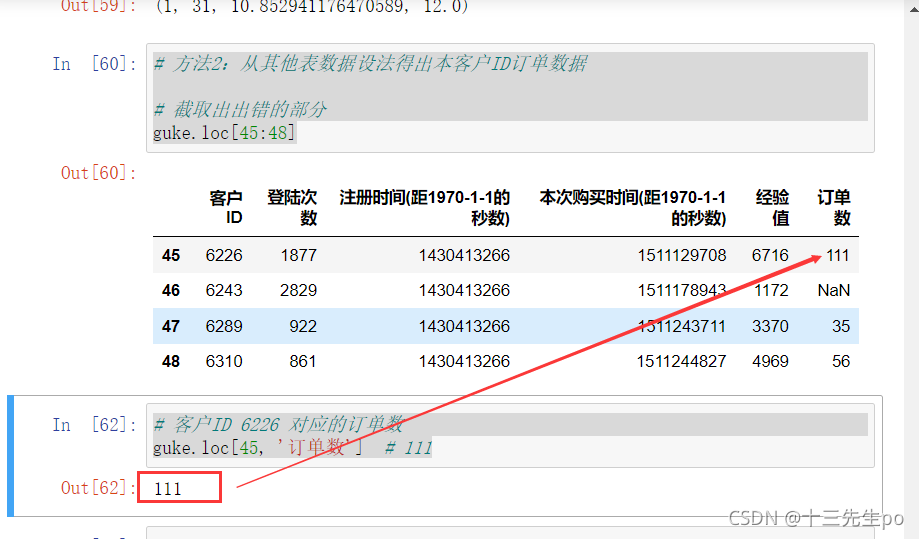
查看客户ID 6226 在订单表格中对应的订单数,发觉数据比较相似
# 客户ID 6226 在订单表格中对应的订单数
dingdan[dingdan['客户ID'] == 6226].shape[0] ## 104

再缩小范围,检索一下其成交的订单数,数值减小,说明所有的订单数加起来才和客户表中的订单数值比较相似
# 客户ID 6226 在订单表格中对应的订单数
dingdan[dingdan['客户ID'] == 6226].shape[0] ## 104
# 再缩小范围,检索一下其成交的订单数,数值减小,说明所有的订单数加起来才和客户表中的订单数值比较相似
dingdan[(dingdan['客户ID'] == 6226) & (dingdan['订单状态'] == 1)].shape[0] # 97
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1508
1508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









