







 计算机自动寻找垃圾信息共同特征在新信息中检测是否包含垃圾信息特征内容,判断其是否为垃圾邮件部分特征:发件人、是否群发、网址、元、赢、微信、免费根据数据类别与部分特征信息,自动寻找类别与特征信息的关系,判断一个新的样本属于哪种类别特征信息以列为单位,行是不同人的信息,输出数据类别(如0是正常,1是垃圾),然后去寻找关系通过股价预测任务区分回归任务与分类任务分类:非连续性判断类别模型输出:非连续型标签(明天股价预测为:上涨)回归:连续性数值预测模型输出:连续型数值(明天
计算机自动寻找垃圾信息共同特征在新信息中检测是否包含垃圾信息特征内容,判断其是否为垃圾邮件部分特征:发件人、是否群发、网址、元、赢、微信、免费根据数据类别与部分特征信息,自动寻找类别与特征信息的关系,判断一个新的样本属于哪种类别特征信息以列为单位,行是不同人的信息,输出数据类别(如0是正常,1是垃圾),然后去寻找关系通过股价预测任务区分回归任务与分类任务分类:非连续性判断类别模型输出:非连续型标签(明天股价预测为:上涨)回归:连续性数值预测模型输出:连续型数值(明天
逻辑回归
计算机自动寻找垃圾信息共同特征
在新信息中检测是否包含垃圾信息特征内容,
判断其是否为垃圾邮件

部分特征:发件人、是否群发、网址、元、赢、微信、免费
- 根据数据类别与部分特征信息,自动寻找类别与特征信息的关系,
判断一个新的样本属于哪种类别
特征信息以列为单位,行是不同人的信息,输出数据类别(如0是正常,1是垃圾),然后去寻找关系


- 通过股价预测任务区分回归任务与分类任务

分类:非连续性判断类别
模型输出:非连续型标签
(明天股价预测为:上涨)
回归:连续性数值预测
模型输出:连续型数值
(明天股价预测为:125.1)
水位判断案例引入逻辑回归计算原理
任务:根据水位,判断水池是否需要蓄水或放水

特征信息:水位数据
数据类别:待蓄水(0)、放水(1)

- 先尝试用线性回归判断(复杂场景就不适用了)

求得一元线性回归直线方程


但如果数据样本复杂度增加,模型准确率下降明显

例如增加了一个x=50后,y的直线方程输出了异常的数据,如x=1时,方程判断结果=0

逻辑回归
根据数据特征,计算样本归属于某一类别的概率P(x),根据概率数值判断其所属类别

Y(x)界线明显,分类效果好!
- 逻辑回归处理更复杂的分类任务1

需要画分界线,将p(x)中的x变成了函数g(x),如果g(x)>0 ,则输出方形;如果g(x)<0,则输出三角形

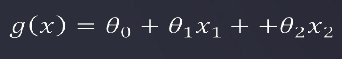
- 逻辑回归处理更复杂的分类任务2
g(x)大于0,小于0,等于0分别对应值在圆圈外,圆圈内,圆圈上

通过以上两个复杂任务的探索,可以知道:
逻辑回归结合多项式边界函数可解决复杂的分类问题
模型求解的核心,在于寻找到合适的多项式边界函数
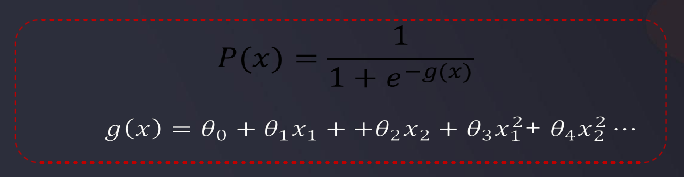
- 因此求解边界函数变成了主要的问题
求解边界函数(可以理解为找到回归方程,但输出的未必是一条直线,而是分界线),需要用到损失函数J来判断预测值和实际值的偏差程度:
求损失函数J(判断预测值和实际值的偏差程度),由原来计算一元线性回归时计算预测yi值与实际y值差的平方和变成了如下图的公式,此时yi就是实际要判断出来值(不是机器预测的值),而-log(p(x))、-log(1-p(x))就是对p(x)这个预测值计算出损失函数J

P(x)就是刚刚的逻辑函数,公式为:
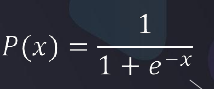
输出的是偏向0或1的值
- 损失函数J计算值的解释

如果y=1,而p(x)=1,则计算出的J=0
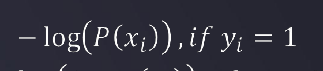

如果y=1,而p(x)=0(说明预测错了),则计算出的J会很大,即损失值很大

同理,对于要测出的实际值是0,如果y=0,而p(x)=1,则计算出的J=0,是符合的
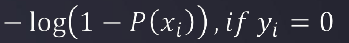

如果y=0,而p(x)=1(说明预测错了),则计算出的J会很大,即损失值很大,也是符合我们的预期判断的

- 损失函数有关计算汇总
损失函数的两个公式可以整合成一个,也是合理的,当yi=0时,yi*log(p(x))就会=0,而恰好log(1-P(x))就可以输出值;当yi=0时,同理可得,也能得到相应的值

而g(x)中各个θ需要通过梯度下降法进行求解,令θ=tempθ,重新代入计算,直到收敛

单次项逻辑回归代码示例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression # 逻辑回归
# 数据读取
data = pd.read_csv(r'task1_data.csv')
data.head()
# 可视化数据
fig1 = plt.figure()
plt.scatter(data.loc[:,'尺寸1'],data.loc[:,'尺寸2'])
plt.title('size1-size2')
plt.xlabel('size1')
plt.ylabel('size2')
plt.show()

# 建立一个用于筛选类别的变量
mask = data.loc[:,'y'] ==1
print(mask)

# 重新数据可视化,利用布尔筛选显示的数值
ok = plt.scatter(data.loc[:,'尺寸1'][mask],data.loc[:,'尺寸2'][mask])
ng = plt.scatter(data.loc[:,'尺寸1'][~mask],data.loc[:,'尺寸2'][~mask])
plt.title('size1-size2')
plt.xlabel('size1')
plt.ylabel('size2')
plt.legend((ok,ng),('ok','ng'))
plt.show()

# x,y赋值
x = data.drop(['y'],axis=1)
y = data.loc[:,'y']
x.head()
# 创建模型
model = LogisticRegression()
print(model)
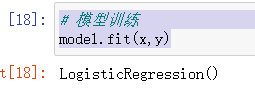
# 模型训练
model.fit(x,y)
# 预测值
y_predict = model.predict(x)
print(y_predict)

# 预测值
y_test = model.predict([[1,10]])
print('ok' if y_test == 1 else 'ng')

二阶项及以上项式的边界函数计算和绘制
如果想输出这样的边界函数

需要用到的g(x)函数就会变成如下图的二阶边界函数

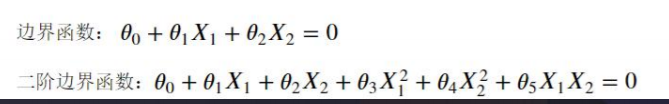
而二阶函数其实也是一个二次函数(抛物线方程),数值方面可以进行变成,变成如下图的:
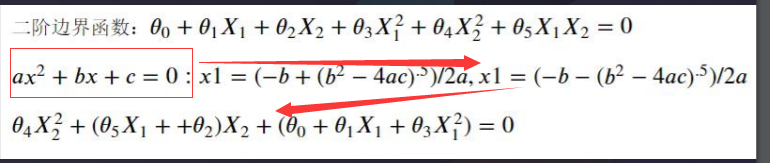
二阶多项式逻辑回归案例
就是有更多的θ,画的边界曲线也更加复杂,如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8744
8744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









