







机器学习经典案例——鸢尾花分类预测
简介
鸢尾花数据集是机器学习中经典的数据集之一,它被广泛用于分类问题的研究和练习。本文将介绍如何使用Python和Scikit-Learn库来进行鸢尾花的分类预测,通过一个完整的机器学习流程,包括数据预处理、模型训练和性能评估。
数据集介绍
鸢尾花数据集包含了三个不同种类的鸢尾花的测量特征,共有150个样本。数据集中的特征包括花萼长度、花萼宽度、花瓣长度和花瓣宽度,目标变量是鸢尾花的种类(Setosa、Versicolor、Virginica)。
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris = load_iris()
# 查看数据集的基本信息
print("数据集大小:", iris.data.shape)
print("特征名称:", iris.feature_names)
print("目标值:", iris.target)
print("目标值名称:", iris.target_names)
数据基本处理
首先,我们需要将数据集分割为训练集和测试集,以便评估模型的性能。我们使用Scikit-Learn的train_test_split函数,并指定了测试集的大小和随机种子以确保结果可重复。
pythonCopy codefrom sklearn.model_selection import train_test_split
# 分割数据集为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=66)
特征工程
在进行模型训练之前,我们对特征进行归一化处理,使用MinMax Scaling方法将特征缩放到0到1的范围。
pythonCopy codefrom sklearn.preprocessing import MinMaxScaler
# 创建MinMaxScaler对象
scaler = MinMaxScaler()
# 对训练集和测试集进行特征缩放
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
机器学习模型选择
为了解决鸢尾花分类问题,我们选择了随机森林算法作为我们的机器学习模型。随机森林是一个强大的集成算法,通常对分类问题表现良好。
pythonCopy codefrom sklearn.ensemble import RandomForestClassifier
# 实例化随机森林分类器
estimator = RandomForestClassifier()
# 模型训练
estimator.fit(x_train, y_train)
模型评估
我们使用模型在测试集上的性能来评估模型的准确性。首先,我们进行预测并将预测结果与真实值进行比较。然后,我们计算模型的准确率作为性能指标。
pythonCopy code# 预测值结果输出
y_pred = estimator.predict(x_test)
# 计算准确率
accuracy = (y_pred == y_test).mean()
print("准确率:", accuracy)
结论
通过这个示例,我们演示了如何使用Python和Scikit-Learn库进行鸢尾花的分类预测。这个案例涵盖了机器学习流程中的关键步骤,包括数据预处理、模型选择、模型训练和性能评估。鸢尾花数据集是一个经典的机器学习练习案例,可以帮助初学者了解和实践机器学习技术。
参考资料
源码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.ensemble import RandomForestClassifier
## 1.获取数据集
# 获取鸢尾花数据集
iris = load_iris()
# 查看数据集的详细信息
print(iris.data.shape)
print("鸢尾花特征的名称:\n",iris["feature_names"])
print("鸢尾花的目标值:\n",iris["target"])
print("鸢尾花目标值的名称:\n",iris["target_names"])
## 2.数据基本处理
# 对鸢尾花数据集进行分割
# 训练集的特征值x_train,测试集的特征值x_test 训练集的目标值y_train,测试集的目标值y_test
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=66) # 若不指定训练集和测试集比例,默认按3:1划分 random_state确保随机性操作的可重复性,在不同运行中获得相同的随机结果
# print("x_train:\n",x_train)
print(x_test.shape)
## 3.特征工程(特征预处理,这里使用的是归一化的Min-Max Scaling)
# 创建MinMaxScaler对象
scaler = MinMaxScaler()
# 对训练集进行Min-Max缩放
x_train = scaler.fit_transform(x_train)
# 对测试集进行Min-Max缩放
x_test = scaler.fit_transform(x_test)
## 4.机器学习(这里选择的是随机森林算法)
# 实例化随机森林分类器
estimator = RandomForestClassifier()
# 模型训练
estimator.fit(x_train,y_train)
## 5.模型评估
# 预测值结果输出
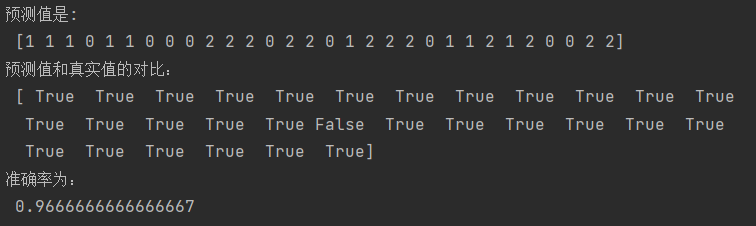
y_pre = estimator.predict(x_test)
print("预测值是:\n",y_pre)
print("预测值和真实值的对比:\n",y_pre == y_test)
# 准确率计算
score = estimator.score(x_test,y_test)
print("准确率为:\n",score)
















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











