






更多内容点击查看:Python实战 | 文本文件编码问题的 Python 解决方案
本文目录
一、引言
二、非结构化文本文件编码异常问题
1. 读取编码与实际编码不一致
2. 文本中存在无法解码的字符怎么解决?
三、结构化文本文件的编码异常问题
1. CSV 文件
2. dta(Stata)文件
四、总结
五、相关推荐
本文共6687个字,阅读大约需要17分钟,欢迎指正!
Part1 引言
一直以来,文本数据处理在数据处理工作中的占比都不小,很多时候在读取或写入文本文件时会遇到各种编码问题,导致无法读取数据。本期文章我们来分享一些文本文件编码的知识和使用 Python 解决文件编码的一些方法。
Part2 非结构化文本文件编码异常问题
Python 内置的 open() 函数是读取文本文件(主要是 txt、csv 文件)的主要工具,尽管一些第三方库也可以提供读取文本的接口,但其中大部分也是通过调用 open() 函数来实现的。在使用它读取文件时经常会遇到编码异常问题,就像下面这样:
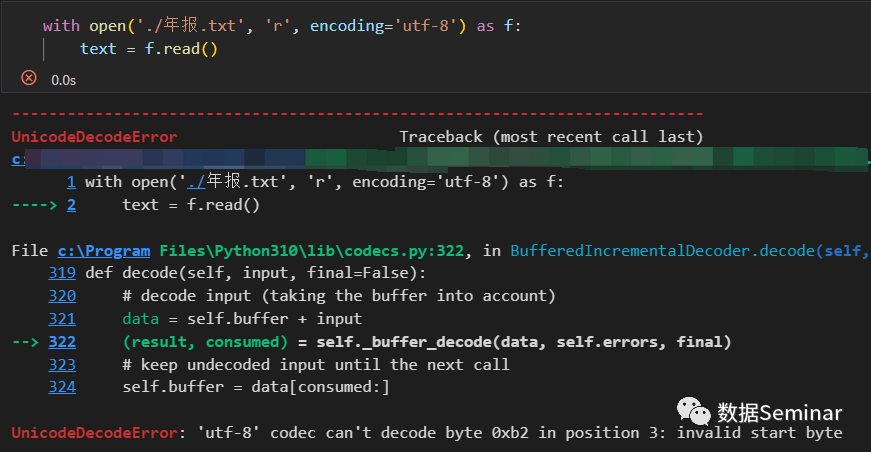
出现上述问题主要有两种情况:
-
读取用的编码与文件编码不一致。
-
读取时使用的编码是正确的,但是文本中出现了一些无法被正确解码的字符。
1. 读取编码与实际编码不一致
如果是第一种情况,我们就要改用正确的编码来读取,那么如何确定文本文件的正确编码就是解决问题的关键。解决这个问题有很多种办法,最简单快捷的方法是使用 Windows 中自带的记事本打开文件,然后依次点击【文件】-【另存为…】就可以看到文件的默认编码。
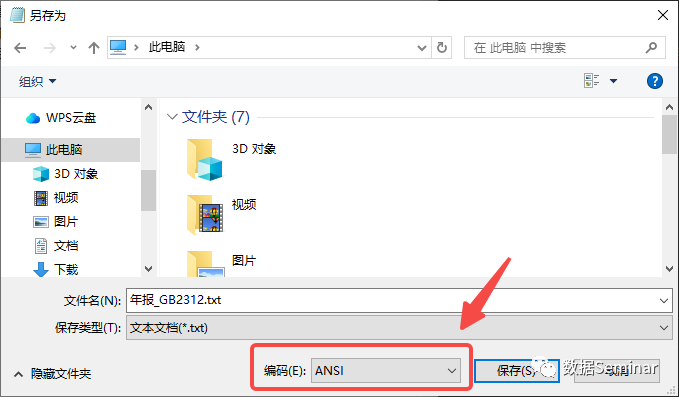
不过记事本只对文件编码进行了简单的区分,我们可能得不到文件的具体编码,例如这里能看出编码是“ANSI”,但实际使用时发现压根就没有这个编码,这是因为 ANSI 实际上类似于一种标准,在不同地区的 windows 操作系统中代表着不同类别的编码格式。在国内,用来表示汉字字符的 GBK、GB2312、GB18030 等编码都被统称为 ANSI,更多细节可以参考这一篇文章:ANSI是什么编码?
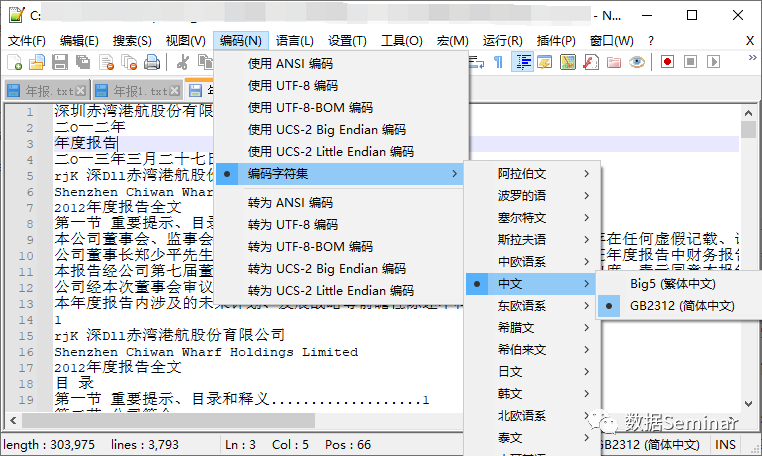
如果不能通过记事本确定文件的编码,那么可以下载一个文本编辑器 notepad++,用它打开文本文件可以帮助你尽可能地获取文件的准确编码。
当然也可以通过 Python 代码来推断编码格式(并不一定完全准确),代码如下:
import chardet
def detect_encoding(file_path):
with open(file_path, 'rb') as f:
raw_data = f.read()
result = chardet.detect(raw_data)
encoding = result['encoding']
confidence = result['confidence']
return encoding, confidence
# 要推断编码的文件路径
file_path = './年报.txt'
encoding, confidence = detect_encoding(file_path)
print('文件编码:', encoding)
print('可信度:', confidence) # 可信度在 0-1 之间
'''
文件编码: GB2312
可信度: 0.99
'''
文本文件常见的编码有以下几种,如果不确定你的文件用哪一种编码,可以都试一遍。
-
ASCII:最早的字符编码标准,使用7位二进制数表示字符,包括基本的英文字母、数字和一些符号。不过不适合用来表示中文文本。 -
UTF-8:一种可变长度的Unicode编码,用于表示世界上几乎所有的字符。它是目前最常用的字符编码之一。 -
UTF-16:也是Unicode编码,使用16位二进制数表示字符。它可以表示Unicode字符集的所有字符。 -
UTF-32:同样是Unicode编码,使用32位二进制数表示字符。与UTF-8和UTF-16相比,UTF-32需要更多的存储空间。 -
ISO-8859-1:也称为Latin-1或latin1,是国际标准化组织(ISO)定义的字符编码标准,用于表示西欧语言的字符。有意思的是latin1编码几乎可以读取其他大部分编码的文件而不报错。 -
GBK、GB2312和GB18030:这些是中国国家标准局定义的汉字字符集编码标准,用于表示汉字字符。
💡 GBK、GB2312 和 GB18030 是中国国家标准局制定的汉字字符集编码标准。这三种编码都是用于表示汉字字符的编码方式,但存在一些差异。
GB2312(国标2312):GB2312 是 1980 年发布的中国国家标准,最初包含了 6763 个汉字字符。它使用两个字节来表示每个字符。GB2312 编码主要用于简体中文,包括了常用的简体汉字和一些常用的符号。
GBK(国标扩展):GBK 是 GB2312 的扩展编码,于 1995 年发布。GBK 在 GB2312 的基础上增加了包括繁体汉字、日文假名、韩文汉字在内的超过 21000 个字符。GBK 使用双字节表示大部分字符,但对于部分生僻字符,使用四字节表示。
GB18030(国标18030):GB18030 是 GB2312 和 GBK 的进一步扩展编码,于 2000 年发布。GB18030 是目前中国官方推荐的字符编码标准,它包含了超过 70000 个字符的汉字、拉丁字母、符号和其他文字。GB18030 编码使用一个、两个或四个字节表示字符。
GB2312 是 GB18030 和 GBK 的前身,是最早的汉字编码标准之一。GBK 是对 GB2312 的扩展,解决了GB2312 无法表示的一些字符。而 GB18030 是对 GBK 的进一步扩展,支持更多的字符。
2. 文本中存在无法解码的字符怎么解决?
很多人都知道读取文件要选择合适的编码,知道这一点已经可以解决大多数编码问题。但有些时候,在已经知道正确编码的情况下仍无法成功读取,这大概率是因为文件的来源不一致(例如其他非 Python 工具所生成的文件)所导致的字符编码问题,文件中的极少数字符(大多是一些空白字符或生僻字、符号)无法被正常解码,这个问题在 Python 中也有办法解决。
Python 内置的文件操作函数open()提供了一个errors参数,这个参数用于控制 Python 在遇到编码异常问题时的处理模式,默认的处理模式是严格模式,遇到任何编码问题都会直接抛出异常。这个参数同时也提供了能够忽略解码异常字符的模式,errors参数最常见的取值和含义如下表所示:
| 参数取值 | 说明 |
| 'strict' | 默认的参数值,表示严格模式,遇到编码或解码错误时直接抛出异常。 |
| 'ignore' | 忽略模式,当遇到编码错误时,忽略错误字符并继续进行读取或写入操作,不会抛出异常。使用此模式时,编码异常的字符不会被读取,读取结果可能会少于实际的字符数量。 |
| 'replace' | 替换模式,当遇到编码错误时,使用问号�或其他指定的替换字符替代错误字符。 |
在了解这个实用的参数之后,如何解决文本文件中存在异常字符的问题就迎刃而解了,在使用 open 函数读取文件时,可以将参数errors设置为'ignore'或'replace',设置为'ignore'将会忽略异常字符,更有利于读取后的分析;设置为'replace'时异常字符会被读取为�,有利于验证异常字符的数量,操作代码如下:
file_path = './年报.txt'
# 使用 utf-8 编码读取,异常字符处理模式为替换
with open(file_path , 'r', encoding='utf-8', errors='replace') as f:
text = f.read()
有一点需要再做说明,如果使用替换模式读取后发现读取结果中大部分字符都是�时,很有可能是选择的编码不合适,建议试试其他编码。
最后,在写入文本文件时参数errors依然可以发挥作用。
Part3 结构化文本文件的编码异常问题
1. CSV 文件
这里的“结构化文本文件”主要指的是表示表格的文本文件,最常见的就是 csv 文件和 dta(Stata) 文件,虽然 dta 文件本身是二进制文件,但其内部的变量是通过文本存储的,读取时程序内部同样采用文本读取模式。
在 Python 中处理 csv 文件一般使用 Pandas 库,有时候也使用 csv 库,其中 csv 库是需要联合 open() 函数一起使用,所以在异常编码处理方法上可以向上一节中的 errors 参数用法看齐,这里不再赘述。现阶段最热门的表格数据处理工具库是 Pandas,它不仅可以读写和处理 csv 文件,也支持操作 dta 文件。pandas 中读取 csv 文件的是 read_csv() 函数,这个函数的必要参数和解决编码问题的参数如下表:
| 参数 | 说明 |
|
| 必填参数,CSV 文件所在的路径或返回文件对象的函数 |
|
| 读取时采用的字符编码,默认以 utf-8 编码进行读取 |
|
| 读取 csv 文件时在解码过程中遇到编码错误时的处理方式 |
pd.read_csv() 函数中的encoding_errors参数与 open() 函数中的errors参数的常见取值和功能也完全一样,如下表:
| 参数取值 | 说明 |
| 'strict' | 默认的参数值,表示严格模式,遇到编码或解码错误时直接抛出异常。 |
| 'ignore' | 忽略模式,当遇到编码错误时,忽略错误字符并继续进行读取或写入操作,不会抛出异常。使用此模式时,编码异常的字符不会被读取,读取结果可能会少于实际的字符数量。 |
| 'replace' | 替换模式,当遇到编码错误时,使用问号 �或其他指定的替换字符替代错误字符。 |
所以如果遇到含有编码异常字符的 csv 文件时,可以使用encoding_errors进行异常处理。
2. dta(Stata)文件
处理 dta 数据时,情况就不一样了,因为 pd.read_stata() 函数没有提供encoding参数,不能指定读取文件时使用的编码,默认是以 UTF-8 编码进行读取。Stata 老用户都知道,从 Stata 14 开始,Stata 全面启用了适用性更广的 UTF-8 编码格式,而国内更早版本的 Stata 在存储 dta 文件时一般使用的是 gb2312、gbk 或 gb18030 编码。这就导致早期文件的编码与现在不一致,使用 pd.read_stata() 读取 dta 文件时,如果不能以 UTF-8 编码正常读取,则会改用国际标准化组织(ISO)定义的字符编码标准ISO-8859-1(latin1)进行读取,这样读取后就会得到一个中文乱码的结果,就像下面这样:
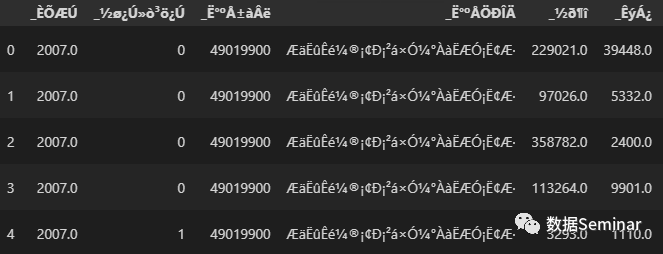
此时我们可以使用 Python 中自带的字符串转码方法对读取结果进行转码,转码时设置异常处理,不能转码的数据将保留原始值。代码如下:
# 读取结果为 data
# 定义转码函数
def Transcoding(x):
x = str(x)
try:
# 尝试转码,转为dta文件原始的编码
res = x.encode('iso-8859-1').decode('gb18030')
return res
except:
return x
# 先对字段名进行转码
data.columns = [Transcoding(col) for col in data.columns]
# 再对表中所有值进行转码,数字不会受到影响
data = data.fillna('').applymap(Transcoding)
# 查看转码后的数据
data
经过转码后,数据中的字符就可以正常显示了。当然,这不一定是最好的解决方案,我们也可以先使用 Stata 软件对 dta 文件进行转码,或者将其导出为 csv 文件后再使用 Python 进行处理。
Part4 总结
处理文本文件经常遇到字符编码异常问题,问题基本集中在两种情况,一是读取或写入的方法有问题,没有用对正确的编码,二是文件出了问题,里面包含编码异常的字符。本文针对这两个问题给出了 Python 中的解决方案,希望能给大家提供帮助。
如果你想学习各种 Python 编程技巧,提升个人竞争力,那就加入我们的数据 Seminar 交流群吧,欢迎大家在社群内交流、探索、学习,一起进步!同时您也可以分享通过数据 Seminar 学到的技能以及得到的成果。














 2325
2325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









