






更多详情请点击查看原文:Python 实战 | 利用 Python 做长宽面板转换(附数据&代码)
Python教学专栏,旨在为初学者提供系统、全面的Python编程学习体验。通过逐步讲解Python基础语言和编程逻辑,结合实操案例,让小白也能轻松搞懂Python!
>>>点击此处查看往期Python教学内容
本文目录
一、前言
二、处理思路浅析
三、处理代码
1. 读取原表
2. 分年份提取数据
3. 合并所有年份数据并排序
4. 保存为 Excel 表
四、总结
五、相关推荐
本文共 3925 个字,阅读大约需要 10 分钟,欢迎指正!
一、前言
从 Wind 下载的一些上市公司信息表样式比较复杂,字段非常多,就像下面这样。
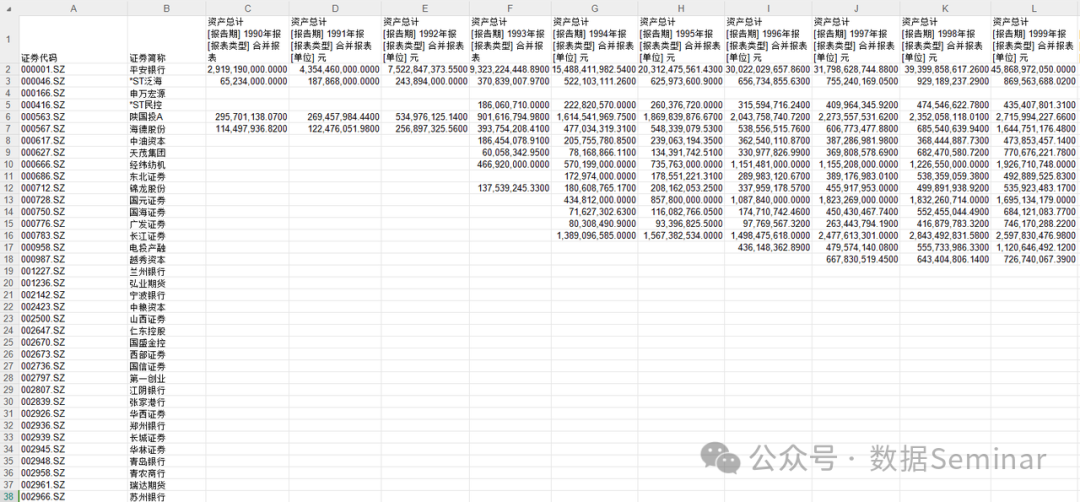
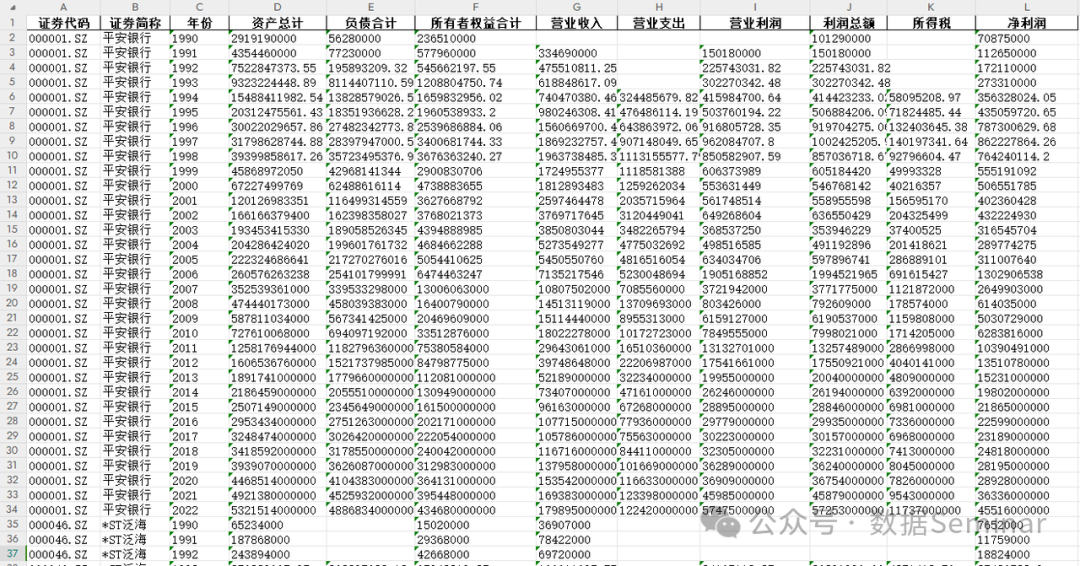
上述表格记录了部分上市公司1990-2022年的九项信息,但每一个字段只记录了一项信息一年的数据,这样算下来全表字段数量已经接近 300 个,这样一个“长表”非常不利于我们精准查找信息。所以我们可以使用 Python 将其转换为如下图所示易用的宽面板数据。
二、处理思路浅析
要将上述长表转换为宽表,无非就是利用 Pandas 进行表格结构的转换,我们有以下两种思路:
-
先读取原表,然后在原表的基础上变换表格结构来达到目的。
-
读取原表,每次从中取出一年的数据,然后再将它们合并起来,最后按序排序即可。
第一种方式难度更高一些,因为字段名称中同时包含了指标名称和年份,所以我们需要把年份独立出来,但这显然不是通过常规的转置等操作就可以实现的。因此使用第二种方式更为方便。
三、处理代码
1. 读取原表
import pandas as pd
# dtype=str 表示以字符类型读取所有列,这是为了防止 pandas 字段类型特性改变数字的精度
data = pd.read_excel('./金融机构上市信息-财务信息20230519.xlsx', dtype=str)
data
2. 分年份提取数据
# 获取原表中所有的指标名称
New_cols1 = [COL.split('\n')[0] for COL in list(data.columns)[2:]]
# 对指标名称去重
New_cols = list(set(New_cols1))
# 去重后再根据原始顺序排序
New_cols.sort(key=New_cols1.index)
# ['资产总计', '负债合计', '所有者权益合计', '营业收入', '营业支出', '营业利润', '利润总额', '所得税', '净利润']
# 先获取所有包含指标名称和年份的原始表字段名
ORICOLS = list(data.columns)[2:]
# 创建一个列表,用于存放每一年的数据
ALL_YEARS = []
for year in list(range(1990, 2023)):
# 循环年份
# COL_year 是后续从原始表中取数据时需要的字段
COL_year = ['证券代码', '证券简称']
# 循环筛选后面的字段,找出符合年份要求的字段名
for col in ORICOLS:
if str(year) in col:
COL_year.append(col)
# 根据前面获取的字段名列表从原始表中筛选数据
data_year = data.loc[:,COL_year]
# 插入年份字段
data_year.insert(2, '年份', str(year))
# 优化字段名,仅保留指标名称
data_year.columns = [COL.split('\n')[0] for COL in list(data_year.columns)]
# 处理后的单个年份的数据表存入提前准备好的列表 ALL_YEARS 中
ALL_YEARS.append(data_year)
3. 合并所有年份数据并排序
# 循环结束后,将所有年份的数据纵向合并在一起形成宽面板
ALL_DATA = pd.concat(ALL_YEARS)
# 按照证券代码和年份进行排序
ALL_DATA.sort_values(by=['证券代码', '年份'], inplace=True)
ALL_DATA
合并、排序后,最终表的结构如下。

4. 保存为 Excel 表
# index=False 表示写入时不保留行索引
# 行索引是 DataFrame 类型特有的属性,若无特殊需求,一般在写入时都不会保留索引
ALL_DATA.to_excel('./金融机构上市信息-财务信息20230519_宽面板.xlsx', index=False)
四、总结
💡本期文章分享了一个非常简单的 Python 数据处理案例,虽然处理思路和过程十分简单,但还是用到了数据分析库 Pandas 中的多个函数,例如读写数据、数据切片、数据排序等,十分有利于 Python 新手拿来练手。最后我们将本文用到的数据集和代码分享给大家,欢迎大家交流讨论。
👉数据 Seminar (GZH) 后台回复关键词“20240419”获取本文演示代码以及演示所用数据。
如果你想学习各种 Python 编程技巧,提升个人竞争力,那就加入我们的数据 Seminar 交流群吧(请查看原文,以获取交流方式),欢迎大家在社群内交流、探索、学习,一起进步!同时您也可以分享通过数据 Seminar 学到的技能以及得到的成果。















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









