







Attention-Aware Face Hallucination via Deep Reinforcement Learning 2017 CVPR

Attention-FH:通过深度强化学习的注意感知面孔幻觉
1、引言
1.1 摘要
主要思想
背景:面部幻觉是一个特定领域的超分辨率问题,其目标是从低分辨率(LR)输入图像中产生高分辨率(HR)的面孔
痛点:现有的方法通常是学习从LR图像到HR图像的单一斑块到斑块的映射,并且不考虑斑块之间的上下文相互依存关系
解决:提出了一个新颖的注意力感知的脸部幻觉(Attention-FH)框架,它采用深度强化学习来顺序发现出席的斑块,然后通过充分利用图像的整体相互依存关系来执行面部的增强。
具体来说: 在每个时间步骤中,递归策略网络被建议通过纳入过去发生的事情来动态地指定一个新的出席区域。因此,状态(即整个图像的面部幻觉结果)可以被局部增强网络利用,并在选定的区域内更新。Attention-FH方法通过最大化反映整个图像幻觉表现的长期回报,联合学习递归策略网络和局部增强网络。

1.2 介绍
背景:
现有的人脸幻觉方法[通常集中在如何学习从LR图像到HR图像的辨别性斑块-斑块映射。特别是最近通过采用先进的卷积神经网络(CNN)和多个级联CNN取得了很大进展。脸部结构先验和空间配置通常被视为增强脸部/面部部分的外部信息。
然而,在幻觉处理过程中,面部各部分之间的上下文依赖关系通常被忽略。根据对人类感知过程的研究,人类从感知整个图像开始,通过注意力转移机制连续探索一连串的区域,而不是单独处理局部区域。(想法的由来)
这一发现启发我们探索出一条新的人脸幻觉的管道,即依次寻找注意力的局部区域,并从全局的角度考虑它们的背景依赖性。
提出方法及创新点:
(1)提出了一个注意力感知的面部幻觉(Attention-aware face hallucination)框架,该框架通过充分利用图像的全局相互依赖性,递归性地发现面部部分并增强它们
(2)考虑到人脸图像在模糊度、姿势、光照和脸部外观上的不同特征,为每个人脸幻觉寻找一个最佳的适应性增强路线。
(3)采用深度强化学习(RL)方法来驾驭模型学习,其在全局优化顺序模型上很有效,且不需要对每一步进行监督。
具体来说,Attention-FH框架通过考虑整个脸部以前的增强结果,共同优化了一个递归政策网络(recurrent policy network),该网络学习政策(policies)以在每一步中选择一个可取的面部部位,以及一个用于面部部位幻觉的局部增强网络。
脸部不同部位之间丰富的相关线索可以明确地纳入每一步的局部增强的过程中,如下图
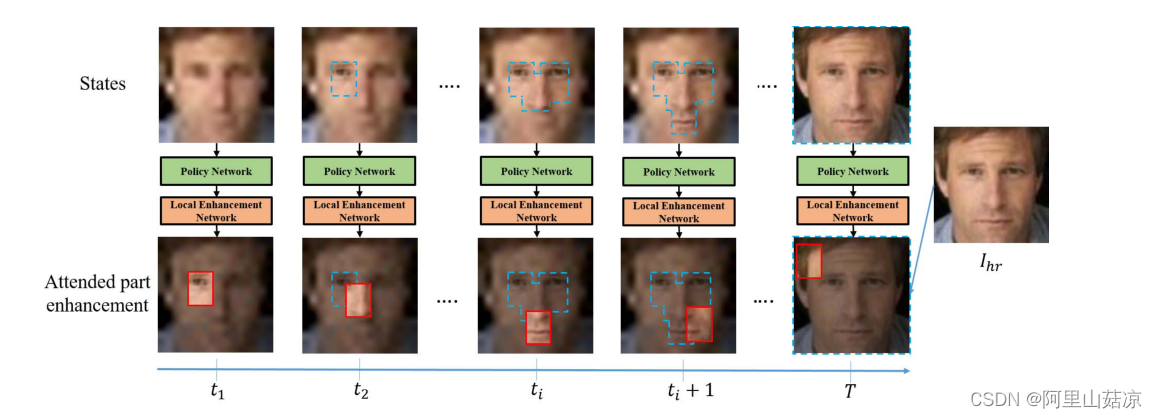
Attention-FH框架中依次发现和增强面部部分:
在每个时间步骤中,作者提出的框架根据过去的幻觉结果指定一个被关注的区域,并通过考虑整个面部的全局视角来增强它。红色实线框表示每一步中最新感知的斑块,蓝色虚线框表示所有先前增强的区域。在序列结束时采用全局奖励来驱动强化学习范式下的框架学习。
(4)通过超分辨率人脸的整体表现来定义强化学习的全局奖励,从而驱动递归策略网络的优化。
递归策略网络按照强化学习(RL)程序进行优化,该程序可被视为马尔科夫决策过程(MDP),并以长期的全局奖励最大化。
(5) 在每个时间步骤中,我们通过对当前增强的整个面部和历史动作进行调节,学习政策(policies)以确定下一个被关注区域的最佳位置。
(6)一个长的短期记忆(LSTM)层被用来捕捉过去被关注的面部区域的信息。
历史动作也被记忆,以避免推理陷入重复动作的循环中。
(7)在每个步骤中给定选定的面部部分,局部增强网络进行超分辨率操作。增强的损失(The loss of enhancement)是根据面部部分的幻觉质量来定义的。值得注意的是,来自面部部位增强的监督信息有效地减少了强化优化过程中不必要的试验和错误。
(8) Attention-FH框架可以明确地生成幻觉过程中的注意力区域序列,这与人类的感知过程非常一致。



2. 详情
2.1 实现算法
(1)
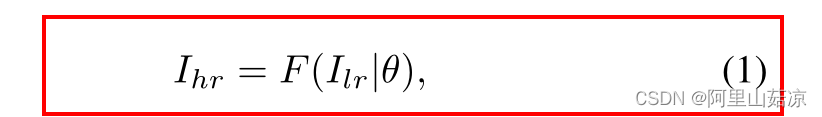
I(lr) :输入的低分辨人脸图像
F(hr) :投影函数 projection function
I(hr) :高分辨率人脸图像,承载着targets
θ :表示函数参数
Attention-FH 提出在每一步中 依次定位和增强被关注的面部部位,这可以被表述为一个深度强化学习过程。
Attention-FH framework 由两个网络组成:
①递归策略网络,动态地确定当前步骤中要增强的特定面部部位;
②局部增强网络,进一步用于增强选定的面部部位。
(2)
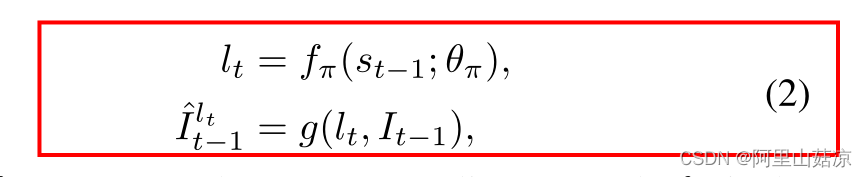
fπ :代表递归策略网络
θπ :是网络参数
st-1 :是递归策略网络的编码输入状态,由输入图像It-1和编码的历史动作ht-1构建
g :表示裁剪操作,从It-1的位置lt裁剪一个固定大小的补丁作为选定的面部部分
(所有面部图像的补丁大小被设定为60×45)
(3)通过局部增强网络 fe 来增强每个局部面部部分![]()
增强的局部补丁![]() 的计算方法:
的计算方法:
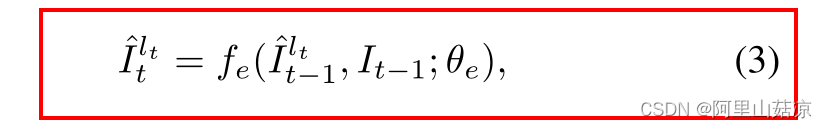
θe :局部增强网络参数
在每个第t步的输出图像 It 是通过用增强的补丁
替换位置 lt 的输入图像It-1的局部补丁而得到的。
(4) sequential Attention-FH 程序可以写成:
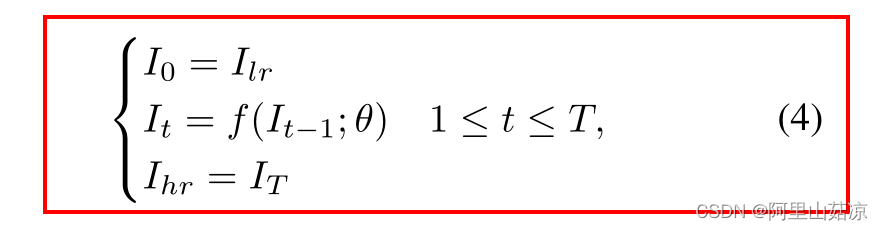
T :局部补丁挖掘步骤的最大数量,根据经验设定T=25
θ = [θπ; θe] f = [fπ; fe].
2.2 网络结构
(1)递归策略网络 Recurrent Policy Network
(2)局部增强网络 Local Enhancement Network
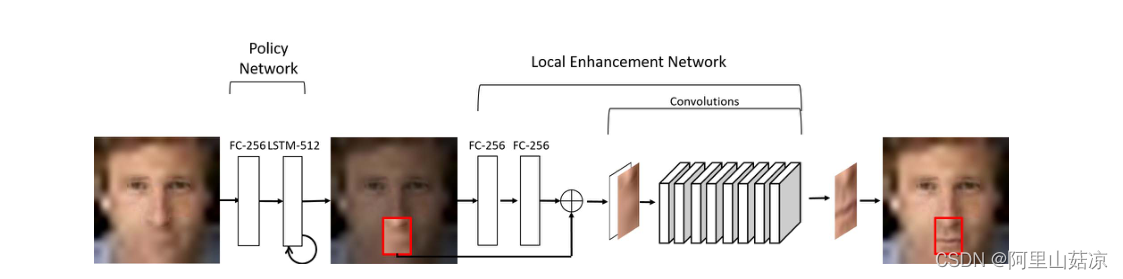
输入:以当前的幻觉结果It-1和由LSTM编码的动作历史向量(512个隐藏状态)
输出:所有W×H位置的动作概率,其中W、H是输入图像的高度和宽度
①策略网络首先用一个全连接层(256个神经元)对It-1进行编码,然后用一个LSTM层将编码后的图像和动作矢量融合。最后附加一个全连接的线性层?来生成W×H-way概率。
②考虑到概率图,我们提取局部补丁,然后将补丁和It-1传入局部增强网络,生成增强的补丁。局部增强网络由两个全连接层(每个有256个神经元)构成,用于编码It-1,8个级联卷积层用于图像补丁增强。因此,一个新的人脸幻觉结果可以通过用一个增强的斑块代替局部斑块而产生。
3、实验结果

缩放系数为8的LFW隧道的定性结果。 SFH和MZQ方法的结果没有显示,因为它们依赖于面部标志,而这些标志在这种低分辨率的图像中往往无法检测。

对比例系数为4的LFW-隧道的定性结果。

增强序列和代理选择的相应斑块的例子结果。一些斑块中的灰色表示原始图像以外的区域。在电子版中通过放大查看效果最佳
4.结论
在本文中,我们提出了一个新的注意力识别的脸部幻觉(Attention-aware Face Hallucination)框架,并使用深度强化学习对其进行了优化。与现有的脸部幻觉方法相比,我们通过将脸部幻觉问题作为一个马尔可夫决策过程,明确地将不同脸部之间的丰富关联线索纳入其中。
















 1259
1259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











