










一、软件安装
前言:
-
./代表ragflow项目路径 -
版本以及硬件需求
CPU ≥ 4 cores
RAM ≥ 16 GB
Disk ≥ 50 GB
Docker >= 24.0.0 &
Docker Compose >= v2.26.1
node >= 18.20.1
python < 3.12
- 官方教程(ARM64): 本教程参考官方部署文档
1. 安装Homebrew(Mac的软件管家)
-
逐行执行:
# 先给终端开权限(防止卡死) sudo chmod -R 755 /usr/local/bin # 输入密码后回车 /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 常见问题:
- 报错Failed to connect to raw.githubusercontent.com → 开科学上网
- 报错Permission denied → 前面chmod命令没执行成功,重试!
2. 安装Docker Desktop(比谈恋爱还重要)
Step 1:官网下载:
- 访问 https://www.docker.com/products/docker-desktop
- 点击「Download for Mac」→ 选「Apple Chip」版本(M1/M2/M3/M4芯片必选!)
Step 2:手动安装:
- 双击下载的
.dmg文件 - 把Docker图标拖到Applications文件夹(就像拖走前任的照片)
- 第一次启动时:系统会弹窗警告 → 点「打开」
- 菜单栏出现小鲸鱼图标 → 说明安装成功!
Step 3:配置镜像加速:
- 点击小鲸鱼图标 → Preferences → Docker Engine
- 在JSON配置中添加:
"registry-mirrors": [
"https://registry.docker-cn.com",
"https://docker.mirrors.ustc.edu.cn"
]
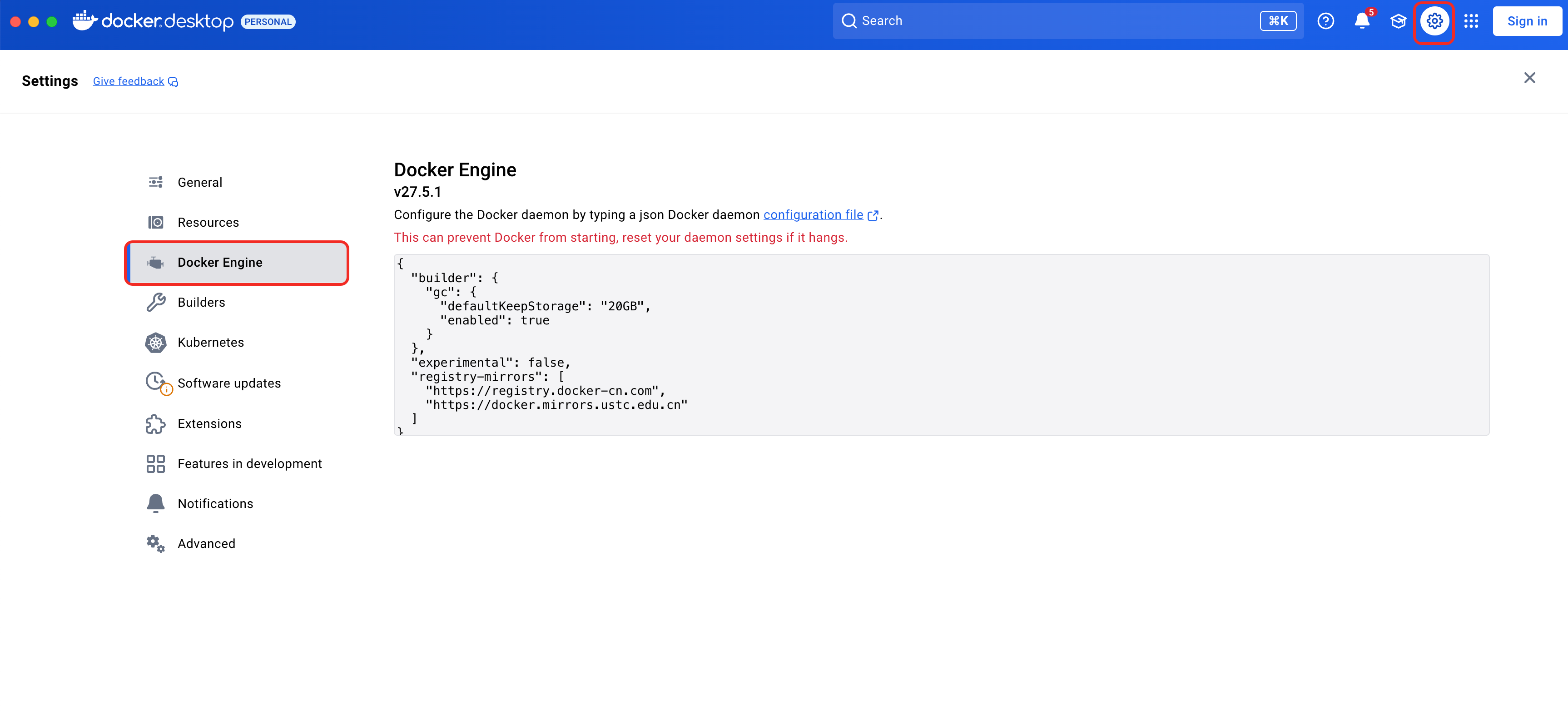
- 点击「Apply & Restart」→ 等鲸鱼吐泡泡重启
Step 4:验证安装:
docker --version # 应该显示Docker version v27.5.1+
二、系统设置(遇到对应错误再设置即可)
1. 调整虚拟内存限制(防Elasticsearch崩溃)
# 临时生效(立刻生效)
sudo sysctl -w vm.max_map_count=262144
# 永久生效(防止重启后失效)
echo 'vm.max_map_count=262144' | sudo tee -a /etc/sysctl.conf
原因: Elasticsearch需要大量虚拟内存,默认值太小会导致启动报错「max virtual memory areas vm.max_map_count [65530] is too low」
2. 修改文件句柄限制(防Too many open files错误)
-
创建配置文件:
sudo nano /Library/LaunchDaemons/limit.maxfiles.plist -
copy以下内容:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version="1.0"> <dict> <key>Label</key> <string>limit.maxfiles</string> <key>ProgramArguments</key> <array> <string>launchctl</string> <string>limit</string> <string>maxfiles</string> <string>65535</string> <string>65535</string> </array> <key>RunAtLoad</key> <true/> <key>ServiceIPC</key> <false/> </dict> </plist> -
加载配置:
sudo launchctl load -w /Library/LaunchDaemons/limit.maxfiles.plist reboot # 必须重启!
三、下载RAGFlow
1. 安装Git
brew install git # Homebrew的优势体现出来了!
2. 克隆仓库
-
方案A:直接克隆(适合网络好):
git clone https://github.com/infiniflow/ragflow.git cd ragflow -
方案B:国内镜像加速(适合下载慢):
git clone https://gitee.com/mirrors/RAGFlow.git # 码云镜像 cd RAGFlow
3. 安装python依赖
**m系列芯片必看:**打开./pyproject.toml,把以来中的xgboost==1.5.0改成xgboost==1.6.0
-
安装 uv:
pipx install uv -
安装python依赖:
# 局部 uv sync --python 3.12 # 全局 uv sync --python 3.12 --all-extras
tips: 由于每个人的环境都是不一样的,这里可能会出现依赖安装出现问题,大家直接根据具体报错解决就好了,一般都是依赖冲突或者需要前置依赖
四、Docker配置(划重点)
修改./docker/docker-compose-base.yml
# 如果是m4芯片并且是最新版的docker需要在配置文件中添加如下内容
- ES_JAVA_OPTS=-Xms2g -Xmx2g -XX:UseSVE=0
- CLI_JAVA_OPTS=-XX:UseSVE=0
# 如果添加完上面的内容启动es还报错,需要把es的版本调高一点(博主的M4是会报错的):
image: elasticsearch:8.17.3
完整的docker-compose-base.yml配置文件如下:
services:
es01:
container_name: ragflow-es-01
profiles:
- elasticsearch
image: elasticsearch:8.17.3
volumes:
- esdata01:/usr/share/elasticsearch/data
ports:
- ${ES_PORT}:9200
env_file: .env
environment:
- node.name=es01
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- bootstrap.memory_lock=false
- discovery.type=single-node
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=false
- xpack.security.transport.ssl.enabled=false
- cluster.routing.allocation.disk.watermark.low=5gb
- cluster.routing.allocation.disk.watermark.high=3gb
- cluster.routing.allocation.disk.watermark.flood_stage=2gb
- TZ=${TIMEZONE}
- ES_JAVA_OPTS=-Xms2g -Xmx2g -XX:UseSVE=0
- CLI_JAVA_OPTS=-XX:UseSVE=0
mem_limit: ${MEM_LIMIT}
ulimits:
memlock:
soft: -1
hard: -1
healthcheck:
test: ["CMD-SHELL", "curl http://localhost:9200"]
interval: 10s
timeout: 10s
retries: 120
networks:
- ragflow
restart: on-failure
infinity:
container_name: ragflow-infinity
profiles:
- infinity
image: infiniflow/infinity:v0.6.0-dev3
volumes:
- infinity_data:/var/infinity
- ./infinity_conf.toml:/infinity_conf.toml
command: ["-f", "/infinity_conf.toml"]
ports:
- ${INFINITY_THRIFT_PORT}:23817
- ${INFINITY_HTTP_PORT}:23820
- ${INFINITY_PSQL_PORT}:5432
env_file: .env
environment:
- TZ=${TIMEZONE}
mem_limit: ${MEM_LIMIT}
ulimits:
nofile:
soft: 500000
hard: 500000
networks:
- ragflow
healthcheck:
test: ["CMD", "curl", "http://localhost:23820/admin/node/current"]
interval: 10s
timeout: 10s
retries: 120
restart: on-failure
mysql:
# mysql:5.7 linux/arm64 image is unavailable.
image: mysql:8.0.39
container_name: ragflow-mysql
env_file: .env
environment:
- MYSQL_ROOT_PASSWORD=${MYSQL_PASSWORD}
- TZ=${TIMEZONE}
command:
--max_connections=1000
--character-set-server=utf8mb4
--collation-server=utf8mb4_unicode_ci
--default-authentication-plugin=mysql_native_password
--tls_version="TLSv1.2,TLSv1.3"
--init-file /data/application/init.sql
ports:
- ${MYSQL_PORT}:3306
volumes:
- mysql_data:/var/lib/mysql
- ./init.sql:/data/application/init.sql
networks:
- ragflow
healthcheck:
test: ["CMD", "mysqladmin" ,"ping", "-uroot", "-p${MYSQL_PASSWORD}"]
interval: 10s
timeout: 10s
retries: 3
restart: on-failure
minio:
image: quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z
container_name: ragflow-minio
command: server --console-address ":9001" /data
ports:
- ${MINIO_PORT}:9000
- ${MINIO_CONSOLE_PORT}:9001
env_file: .env
environment:
- MINIO_ROOT_USER=${MINIO_USER}
- MINIO_ROOT_PASSWORD=${MINIO_PASSWORD}
- TZ=${TIMEZONE}
volumes:
- minio_data:/data
networks:
- ragflow
restart: on-failure
redis:
# swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/valkey/valkey:8
image: valkey/valkey:8
container_name: ragflow-redis
command: redis-server --requirepass ${REDIS_PASSWORD} --maxmemory 128mb --maxmemory-policy allkeys-lru
env_file: .env
ports:
- ${REDIS_PORT}:6379
volumes:
- redis_data:/data
networks:
- ragflow
restart: on-failure
volumes:
esdata01:
driver: local
infinity_data:
driver: local
mysql_data:
driver: local
minio_data:
driver: local
redis_data:
driver: local
networks:
ragflow:
driver: bridge
修改./docker/entrypoint.sh
当我们打开文件后会看到两个切换真实路径和nginx路径的提示,要把真实路径替换成项目的真实路径,nginx路径直接注释掉即可,下面是参考配置:
#!/bin/bash
# replace env variables in the service_conf.yaml file
rm -rf ./conf/service_conf.yaml
while IFS= read -r line || [[ -n "$line" ]]; do
# Use eval to interpret the variable with default values
eval "echo \"$line\"" >> ./conf/service_conf.yaml
done < ./docker/service_conf.yaml.template
# /usr/sbin/nginx
export LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu/
PY=python3
if [[ -z "$WS" || $WS -lt 1 ]]; then
WS=1
fi
function task_exe(){
JEMALLOC_PATH=$(pkg-config --variable=libdir jemalloc)/libjemalloc.so
while [ 1 -eq 1 ];do
LD_PRELOAD=$JEMALLOC_PATH $PY rag/svr/task_executor.py $1;
done
}
for ((i=0;i<WS;i++))
do
task_exe $i &
done
while [ 1 -eq 1 ];do
$PY api/ragflow_server.py
done
wait;
修改./docker/service_conf.yaml.template
-
修改这个配置文件的原因主要是因为启动时容器中的mysql和es的端口号和配置文件的对应不上
-
参考配置:
ragflow: host: ${RAGFLOW_HOST:-0.0.0.0} http_port: 9380 mysql: name: '${MYSQL_DBNAME:-rag_flow}' user: '${MYSQL_USER:-root}' password: '${MYSQL_PASSWORD:-infini_rag_flow}' host: '${MYSQL_HOST:-mysql}' port: 5455 max_connections: 100 stale_timeout: 30 minio: user: '${MINIO_USER:-rag_flow}' password: '${MINIO_PASSWORD:-infini_rag_flow}' host: '${MINIO_HOST:-minio}:9000' es: hosts: 'http://${ES_HOST:-es01}:1200' username: '${ES_USER:-elastic}' password: '${ELASTIC_PASSWORD:-infini_rag_flow}' infinity: uri: '${INFINITY_HOST:-infinity}:23817' db_name: 'default_db' redis: db: 1 password: '${REDIS_PASSWORD:-infini_rag_flow}' host: '${REDIS_HOST:-redis}:6379'注: 博主之前遇到过启动RAGFlow服务时报连接不上,排查方法就是
五、启动服务
1. 安装ragflow运行时需要的组件
docker compose -f docker/docker-compose-base.yml up -d
使用docker ps命令如果mysql、redis、es都正常运行表示成功了:

2. 修改端口映射文件
需要把运行ragflow所需要的容器端口映射到本地
open /etc/hosts
# hosts文件中追加一行即可:
127.0.0.1 es01 infinity mysql minio redis
3. 配置环境变量和hf地址
source .venv/bin/activate
export PYTHONPATH=$(pwd)
export HF_ENDPOINT=https://hf-mirror.com
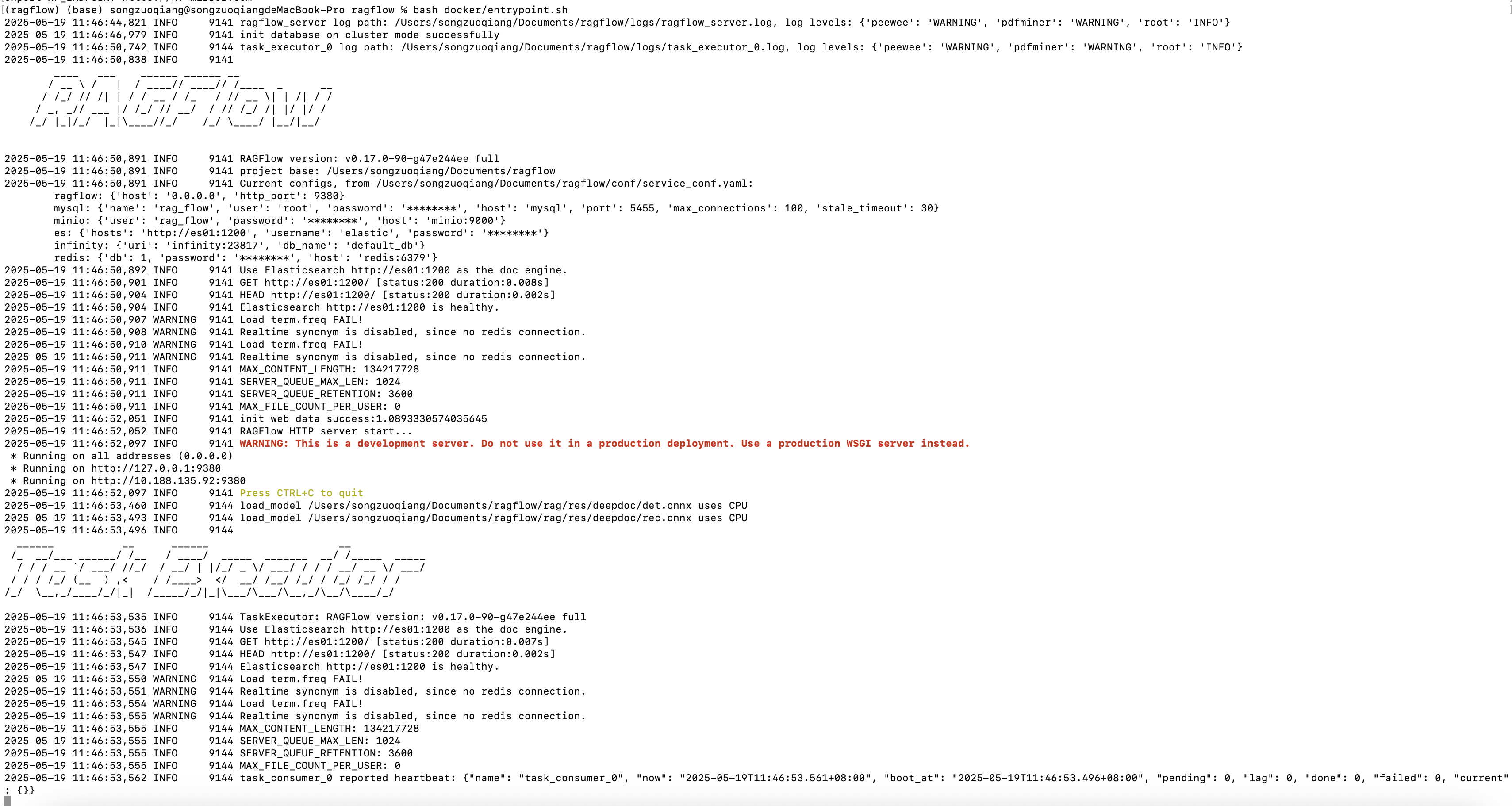
4. 启动RAGFlow 后台服务
bash docker/entrypoint.sh
如果如果在执行的时后报缺少nltk、worknet或者其他的库文件不存在的错误,根据提示安装即可
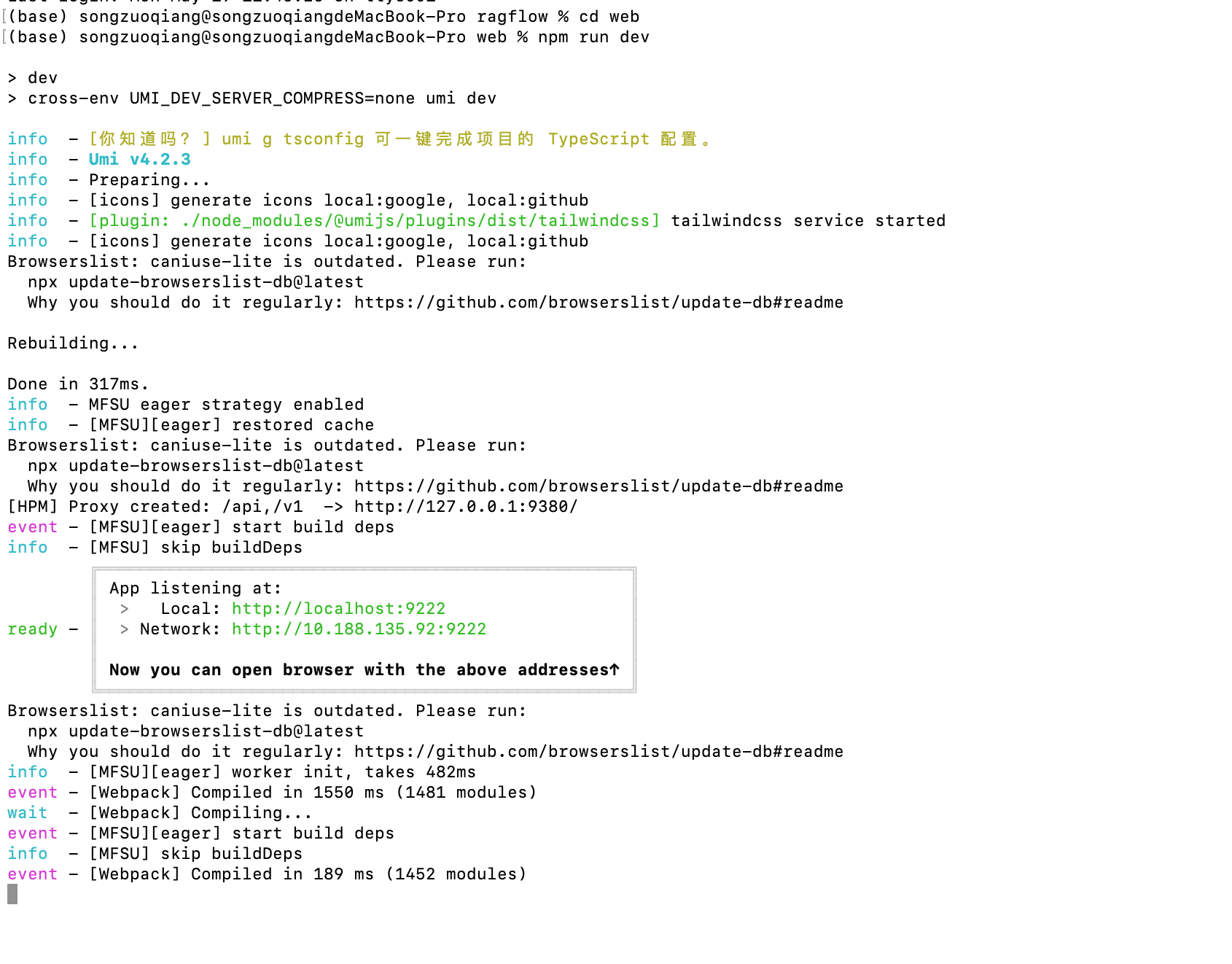
5. 启动RAGFlow 前端服务
因为上面的终端服务不能停止,需要在项目根目录中再打开一个终端窗口:
cd web
npm install
npm run dev
6. RAGFlow启动脚本
由于本小节中的1、3、4、5步每次启动RAGFlow时都要重复执行,所以我们可以写一个脚本来帮我们完成以上操作,启动脚本代码如下:
#!/bin/bash
# 获取当前工作目录的绝对路径
CURRENT_DIR=$(pwd)
# 第一部分:启动Docker容器
osascript -e "tell application \"Terminal\" to do script \"cd '$CURRENT_DIR' && docker compose -f docker/docker-compose-base.yml up -d\""
# 等待10秒让Docker服务启动
echo "等待Docker服务初始化(10秒)..."
sleep 10
# 第二部分:激活虚拟环境并运行Python相关命令
osascript -e "tell application \"Terminal\" to do script \"cd '$CURRENT_DIR' && source .venv/bin/activate && export PYTHONPATH=\$(pwd) && export HF_ENDPOINT=https://hf-mirror.com && bash docker/entrypoint.sh\""
# 第三部分:启动web开发服务器
osascript -e "tell application \"Terminal\" to do script \"cd '$CURRENT_DIR/web' && npm run dev\""
直接在项目根据路中创建一个.sh脚本,每次想要启动时直接在项目根目录运行当前脚本即可。
六、验证安装
1. 基础检查
# 检查容器状态(STATUS应为running)
docker ps -a | grep ragflow
# 检查端口监听(看是否有9000端口)
lsof -i :900
2. 浏览器验证:
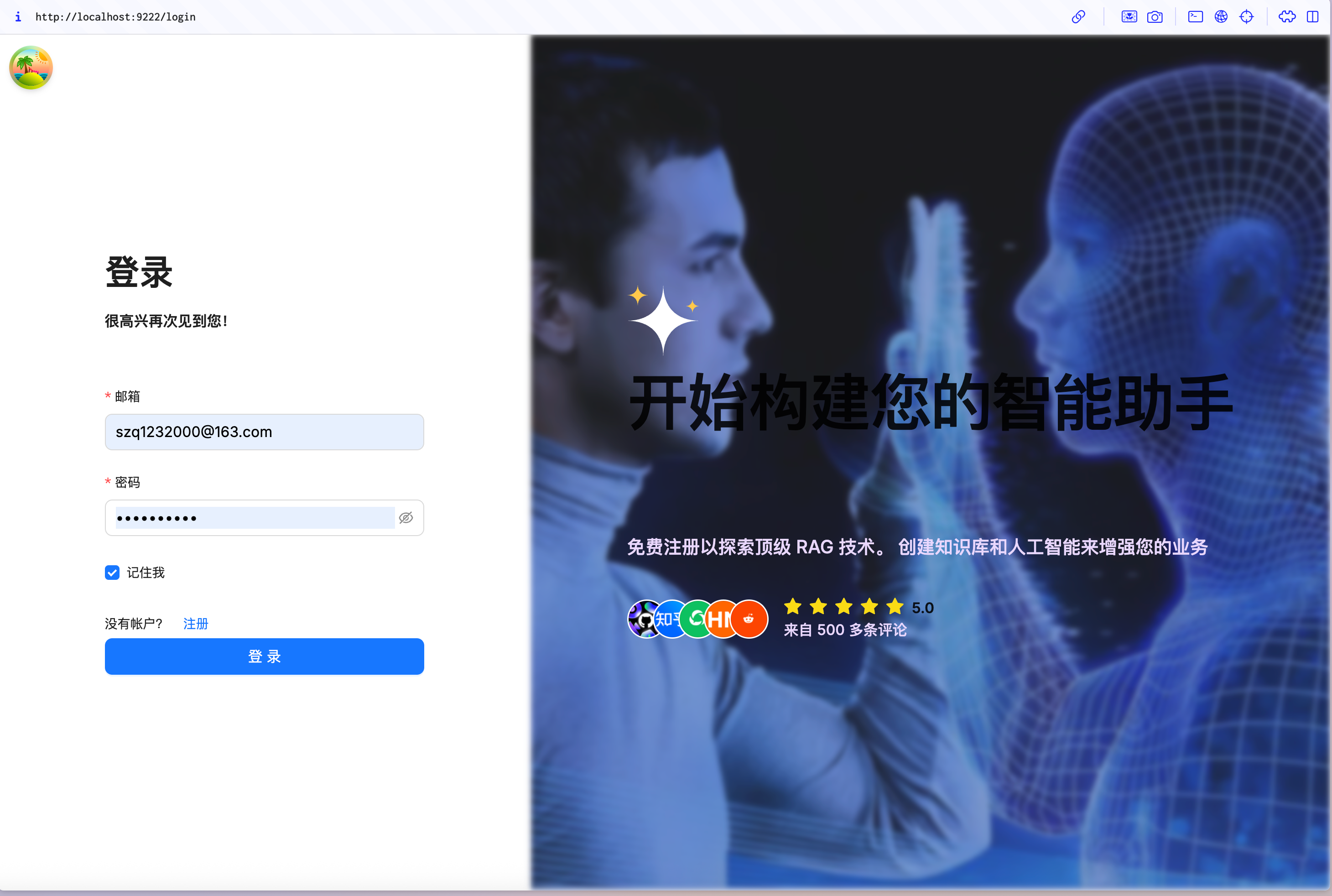
打开Chrome → 输入http://localhost:9222(如果你没有改端口),如能你可以成功进去的下面的界面并且可以完成注册和登录那么你的RAGFlow就算启动成功了:
七、模型配置
本文使用Ollama运行本地模型来作为RAGFlow的模型提供方,如果大家想方便的话也可以选一个喜欢的模型然后用官方的api-key即可
1. Ollama安装与配置
-
Ollama安装:Ollama的安装教程可参考我的这一篇文章:Ollama安装
-
设置环境变量:
export OLLAMA_HOST=0.0.0.0:11434 -
运行模型:
Ollama run model-name
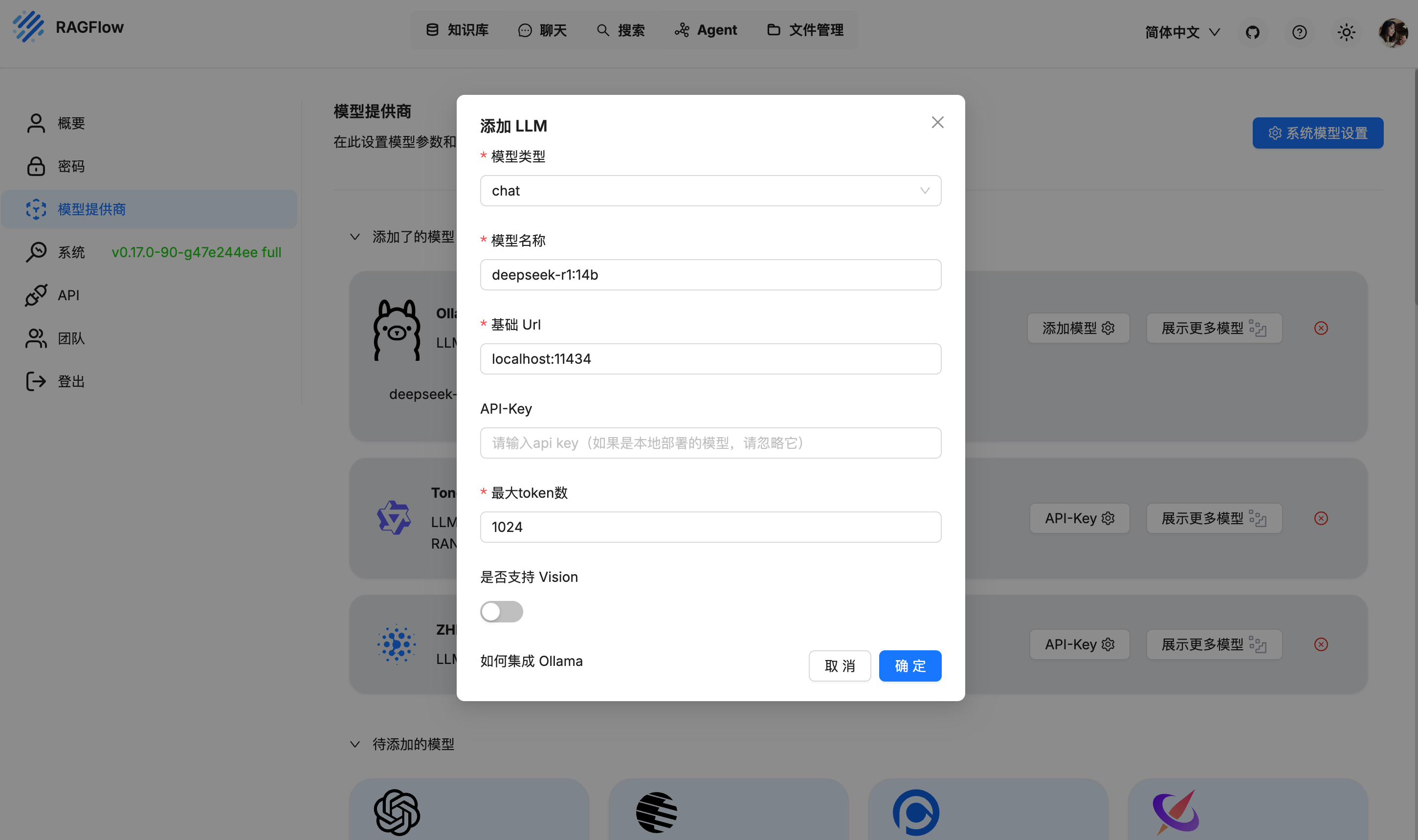
2. 在RAGFlow 中添加模型
-
登录RAGFlow网页 → 点击右上角头像 → 「模型供应商」
-
往下拉在「待添加的模型」→ 选择「Ollama」,然后按照图片中的配置:
下面是各输入框的解释:
-
模型类型
- Chat模型(AI的“嘴皮子”)
- 干啥用的:负责和你聊天对话,生成人类能看懂的回答
- 经典模型:Llama3、Qwen、GPT、DeepSeek
- 举个栗子🌰:
当你问“如何安装Ollama”,Chat模型就会像话痨同事一样,把安装步骤一条条讲给你听 - 选型秘诀:
- 需要“话多且准”:选参数大的模型(比如70B)
- 电脑配置低:用7B小模型(虽然可能胡说八道)
- Embedding模型(文字“翻译官”)
- 干啥用的:把文字变成一串数字(向量),方便计算机理解语义
- 经典模型:BGE、text2vec、OpenAI的text-embedding-3-small
- 灵魂比喻:
相当于给每句话发一个身份证号,说“春天”和“花开”的号码接近,“冰箱”和“宇宙”的号码离得远 - 选型秘诀:
- 中文优先:选
bge-large-zh这类中文专用模型 - 速度优先:用
small版(精度会下降)
- 中文优先:选
- Rerank模型(结果“质检员”)
- 干啥用的:对搜索出的100条结果重新打分,把最相关的排到最前面
- 经典模型:bge-reranker、cohere-rerank
- 举个栗子🌰:
你搜“苹果”,初步结果可能包含水果、手机、电影公司。Rerank模型会说:“根据上下文,用户其实想查iPhone”,然后把手机相关结果置顶 - 选型秘诀:
- 精准度 vs 速度:大模型准但慢,小模型快但糙
- 可选项少:目前主流就2-3种
- Image2Text模型 —— 图片的“解码器”
- 干啥用的:把图片里的文字抠出来(比如扫描版PDF/照片里的文字)
- 经典模型:PaddleOCR、Donut、EasyOCR
- 灵魂场景:
你上传一张表情包截图,AI能读出上面的字:“一键三连的都是帅哥美女!” - 选型秘诀:
- 中文场景:优先选
PaddleOCR(国产之光) - 复杂排版:用
Donut(但吃显卡)
- 中文场景:优先选
“四大天王的工作流程”:
你问问题 → if image then Image2Text先提取文字 → Embedding模型翻译成向量 → 搜索知识库 → Rerank模型重新排序 → Chat模型组织答案 → 返回人话 - Chat模型(AI的“嘴皮子”)
-
模型名称:
Ollama中的模型名称,一定要与Ollama中的模型名称保持一致 -
基础url:调用模型的url
-
API-key:如果是使用API的方式调用模型时需要填写此内容
-
最大token数:模型返回的最大token数量
-
-
上面是添加的
chat模型,添加Embedding模型同理,博主这里使用的是智谱的Embedding模型,大家本地启动Embedding模型或者使用API-key都可以
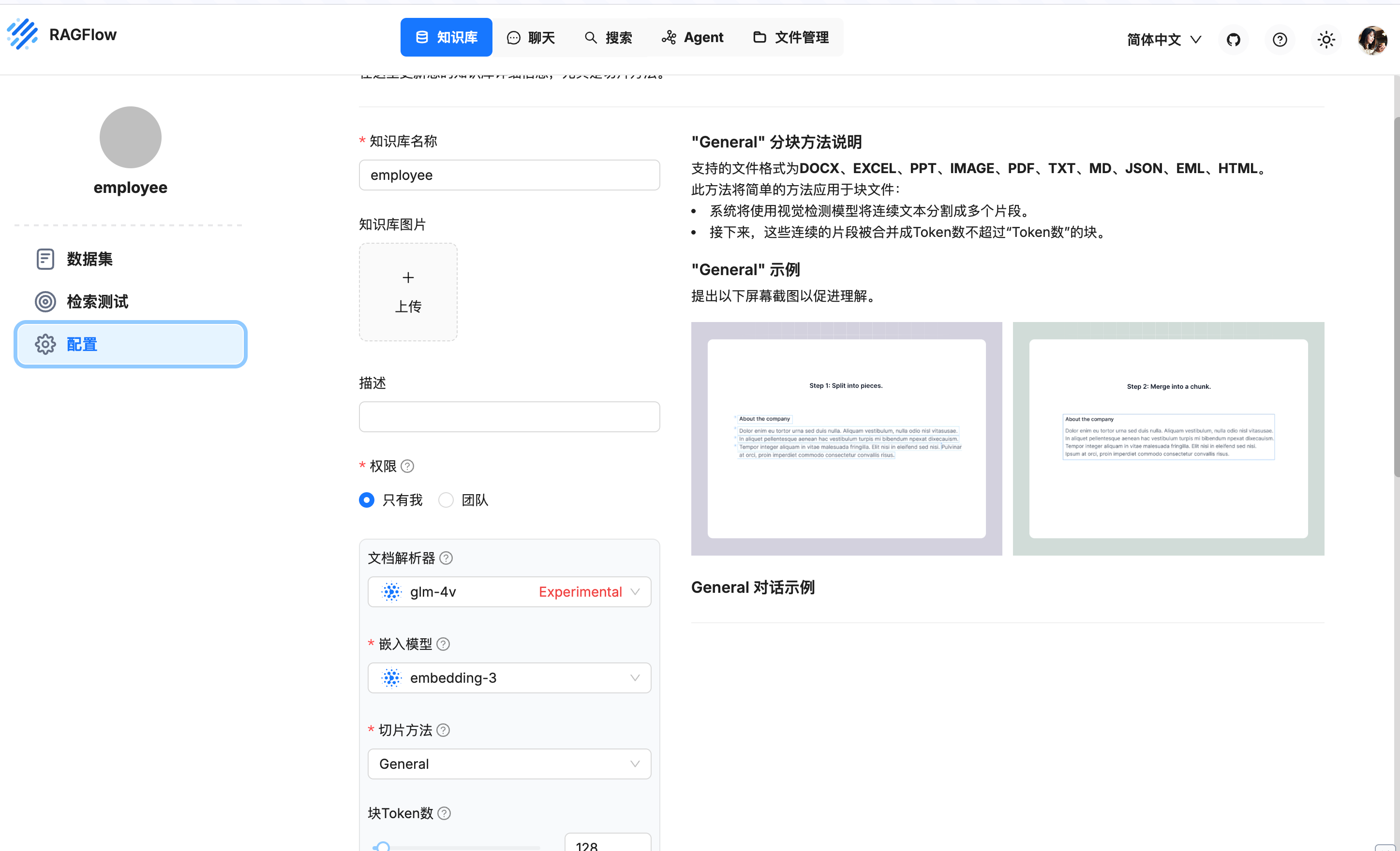
3. 上传知识库
-
点击「知识库」→ 「创建知识库」→ 输入知识库名称
-
进行知识库配置
-
上传文件限制:
- 格式:PDF/DOCX/TXT/Markdown
- 单文件≤100MB(超过会卡到怀疑人生)
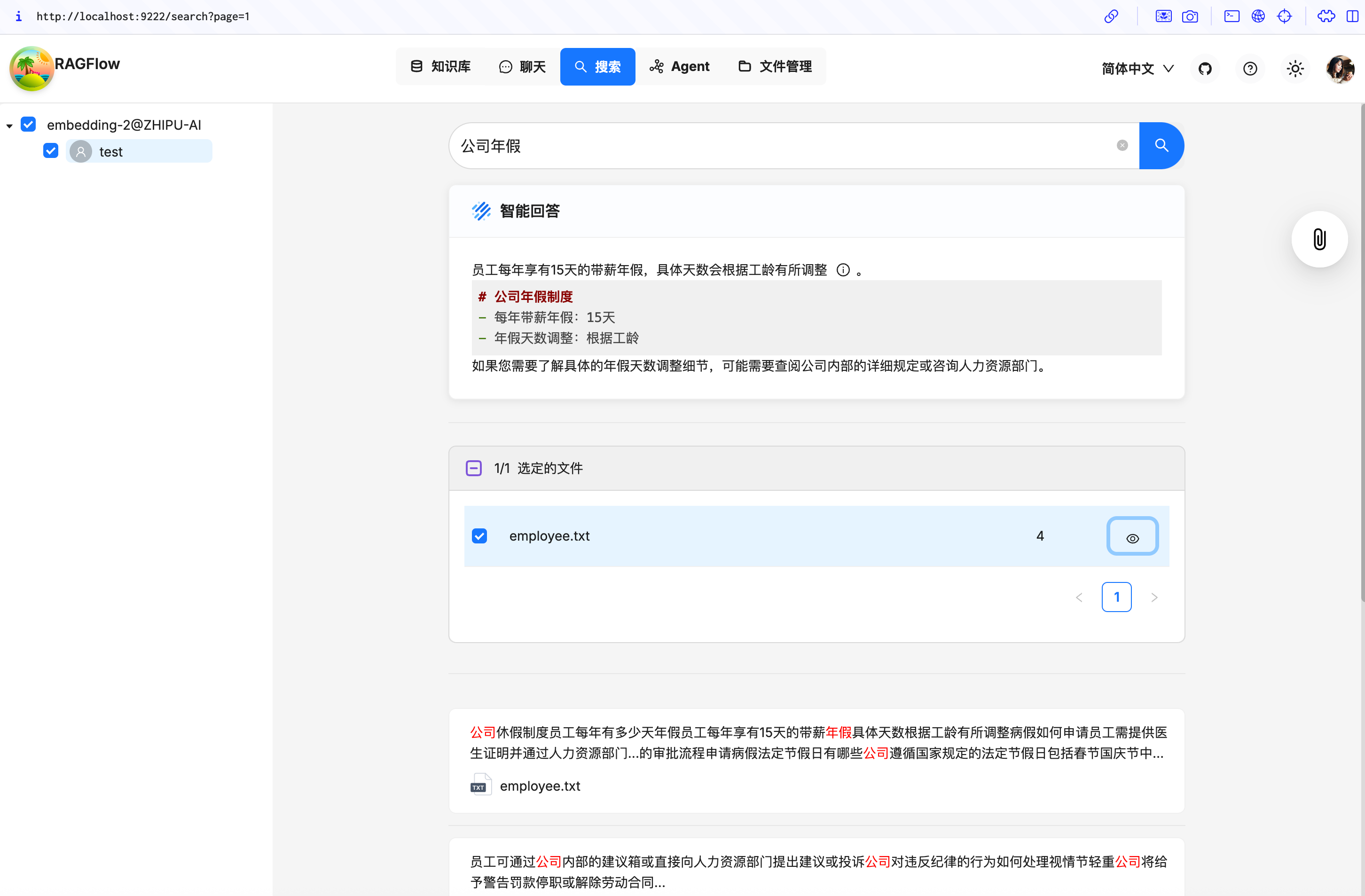
当文件上传成功之后我们可以搜索页面对刚刚上传的文档进行验证:
4. 进行聊天
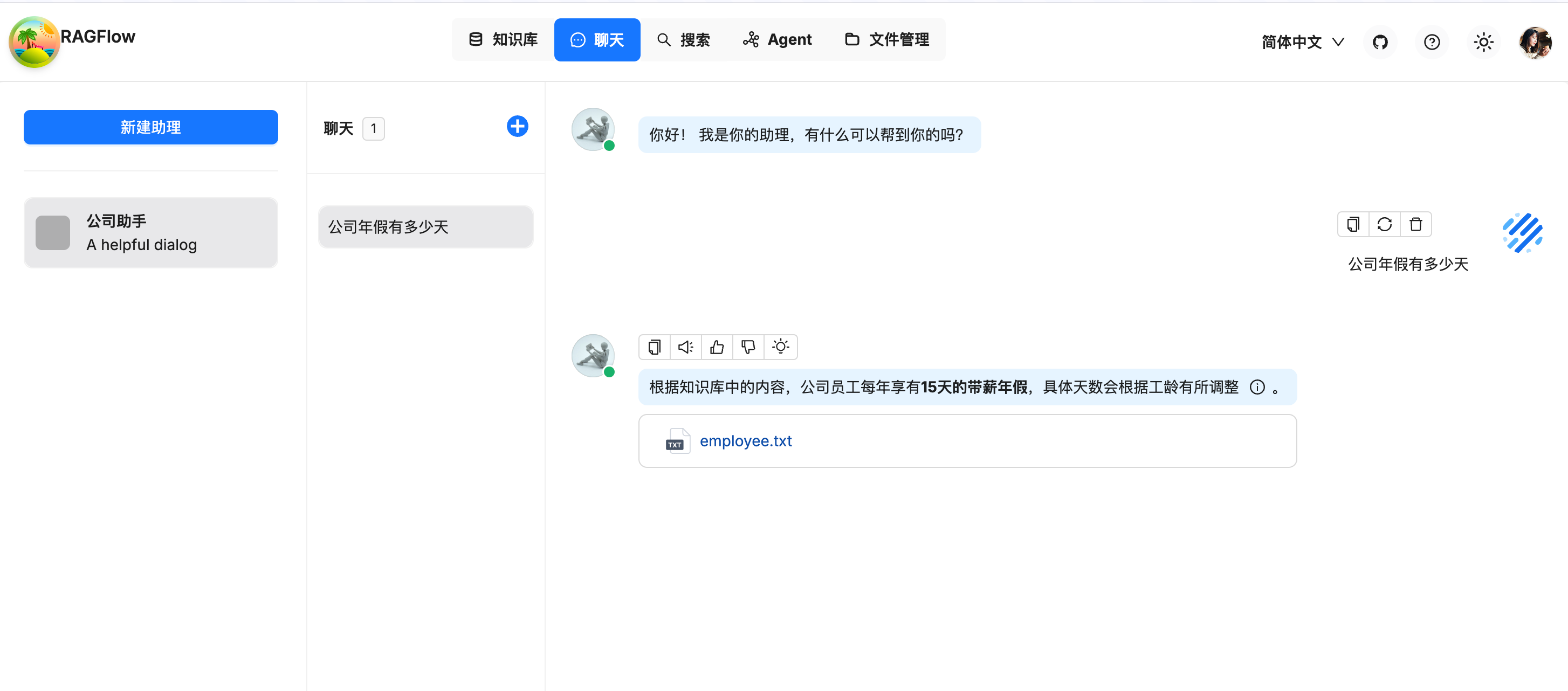
当上述的工作都完成后我们就可以点击RAGFlow的聊天页面进行聊天啦,当我们第一次进行这个页面时是什么都没有的,需要先点击[创建助手]以配置助手的基本信息,包括:助手的名字,助手使用的知识库以及模型等等,当我们这些工作都做完之后就可以与智能助手进行聊天了:
八、常见错误大全
-
Docker报错
no space left on device-
原因:Docker虚拟磁盘满了(默认只分配64GB)
-
解决:
-
打开Docker Desktop → Settings → Resources
-
调整Disk image size到100GB+
-
点击Apply & Restart
-
-
-
CUDA out of memory- 原因:模型太大,Mac的GPU扛不住
- 优雅降级法:
- 在RAGFlow网页 → 模型管理
- 选择更小模型(如
bge-small-zh) - 修改推理参数:
max_length=512
-
文件解析卡住并且一直在1%以下,解析状态提示
Task is queued如果文件解析卡住时首先要检查一下后台服务器有没有报错,如果没有报错的话可以耐心等待一会或者重新试一下,如果报错的话就需要根据报错来解决相应的问题了, 以下是常见问题:
-
During handling of the above exception, another exception occurred:
- 原因: mysql数据库中存在脏数据,把mysql数据库中脏数据清空即可,一般是task表中有脏数据
- 完整报错:
Traceback (most recent call last): File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/peewee.py", line 7253, in get return clone.execute(database)[0] File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/peewee.py", line 4553, in __getitem__ return self.row_cache[item] IndexError: list index out of range During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/Users/songzuoqiang/Documents/ragflow/rag/svr/task_executor.py", line 231, in build_chunks cks = await trio.to_thread.run_sync(lambda: chunker.chunk(task["name"], binary=binary, from_page=task["from_page"], File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/trio/_threads.py", line 447, in to_thread_run_sync return msg_from_thread.unwrap() File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/outcome/_impl.py", line 213, in unwrap raise captured_error File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/trio/_threads.py", line 373, in do_release_then_return_result return result.unwrap() File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/outcome/_impl.py", line 213, in unwrap raise captured_error File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/trio/_threads.py", line 392, in worker_fn ret = context.run(sync_fn, *args) File "/Users/songzuoqiang/Documents/ragflow/rag/svr/task_executor.py", line 231, in <lambda> cks = await trio.to_thread.run_sync(lambda: chunker.chunk(task["name"], binary=binary, from_page=task["from_page"], File "/Users/songzuoqiang/Documents/ragflow/rag/app/naive.py", line 252, in chunk callback(0.1, "Start to parse.") File "/Users/songzuoqiang/Documents/ragflow/rag/svr/task_executor.py", line 139, in set_progress cancel = TaskService.do_cancel(task_id) File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/peewee.py", line 3128, in inner return fn(*args, **kwargs) File "/Users/songzuoqiang/Documents/ragflow/api/db/services/task_service.py", line 175, in do_cancel task = cls.model.get_by_id(id) File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/peewee.py", line 6816, in get_by_id return cls.get(cls._meta.primary_key == pk) File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/peewee.py", line 6805, in get return sq.get() File "/Users/songzuoqiang/Documents/ragflow/.venv/lib/python3.10/site-packages/peewee.py", line 7256, in get raise self.model.DoesNotExist('%s instance matching query does ' api.db.db_models.TaskDoesNotExist: <Model: Task> instance matching query does not exist: SQL: SELECT `t1`.`id`, `t1`.`create_time`, `t1`.`create_date`, `t1`.`update_time`, `t1`.`update_date`, `t1`.`doc_id`, `t1`.`from_page`, `t1`.`to_page`, `t1`.`task_type`, `t1`.`begin_at`, `t1`.`process_duation`, `t1`.`progress`, `t1`.`progress_msg`, `t1`.`retry_count`, `t1`.`digest`, `t1`.`chunk_ids` FROM `task` AS `t1` WHERE (`t1`.`id` = %s) LIMIT %s OFFSET %s Params: ['e63e63c4347d11f08cfc0ed34b4b35a3', 1, 0] -
如果用的是官方的Embedding模型,RAGFolw会默认从huggingface中下载模型,如果不用魔法时文件解析也会卡住:
- 解析方案:启用魔法或者环境变量中进行添加hf镜像:
# 手动下载模型到本地 export HF_ENDPOINT=https://hf-mirror.com huggingface-cli download --resume-download BAAI/bge-large-zh --cache-dir ~/.cache/huggingface # 重启RAGFlow docker compose restart
- 解析方案:启用魔法或者环境变量中进行添加hf镜像:
-
-
持续更新中…
结语: 如果你通过这篇文章成功搭建了RAGFlow,那么请告诉你的朋友:“关注这个博主,毕竟TA连你都可以教会诶!” ,如果你有任何关于RAGFlow的问题或疑惑欢迎在评论区讨论🥳。


















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











