




 本文介绍了深度学习在图像处理领域的几种关键技术,包括语义分割、识别与分割、目标检测和实例分割。语义分割关注像素级别的分类,通过卷积网络结合下采样和上采样层实现。识别与分割任务则涉及分类和定位,目标检测强调找出图像中的多个目标并框定。针对目标检测的效率问题,发展了如RCNN、Fast R-CNN和Faster R-CNN等方法。实例分割则结合了语义分割和目标检测,区分同一类别的不同实例。文章还提到了Mask R-CNN在实例分割中的应用。
本文介绍了深度学习在图像处理领域的几种关键技术,包括语义分割、识别与分割、目标检测和实例分割。语义分割关注像素级别的分类,通过卷积网络结合下采样和上采样层实现。识别与分割任务则涉及分类和定位,目标检测强调找出图像中的多个目标并框定。针对目标检测的效率问题,发展了如RCNN、Fast R-CNN和Faster R-CNN等方法。实例分割则结合了语义分割和目标检测,区分同一类别的不同实例。文章还提到了Mask R-CNN在实例分割中的应用。
一、语义分割 semantic segmentation
1、目标
将图像的每个pixel分到一个类别中,只关注像素,不区分实例instance。如右边的两头牛虽然是两个实例,但我们不能把它们区分开,只会把这一堆像素全部标记为牛。

2、滑动窗口实现语义分割 sliding window
将整张图片分解成若干小碎片,然后对每个小碎片进行分类。但是这样做的计算复杂度很高,因为我们希望为图中的每一个像素点都做label,这就需要我们为每个像素都准备单独的小碎片。且对于有重叠区域的两个碎片来说,它们的重叠区域的卷积计算都是一样的,但是却要计算两遍,没有办法共享计算过程。

3、仅使用卷积层实现分割
有一个很深的卷积网络,我们直接把整个图像(大小为H by W)输入到网络中,然后经过卷积层的输出结果是对每一个像素都做一个分类,也就是C by H by W,其中C是总共的类别数目。
但是这种方法有一个问题,就是我的每一个卷积层都要保持原始图像的尺寸,也就是假设我的通道数选了P,那么我这一层的输出数据量就是P by H by W(因为我要对每个像素都做分类,所以一定是通道数乘上H乘W),那么如果我的输入图像清晰度很高,也就是H乘W很大,那我的计算量就会非常非常大。
4、下采样和上采样结合的卷积网络
为了解决上述的问题,我们不应该只用卷积层,而要结合一些下采样(如池化层或步长较大的卷积层)和上采样层,来先把图像的清晰度降下来,结合进行一系列的卷积处理,最后再通过上采样层把清晰度恢复回输入图像的清晰度,作为输出结果。

上采样层
-
最近距离去池化 nearest neighbor unpooling
-
钉床函数去池化 bed of nails unpooling

-
最大去池化 Max unpooling
最大去池化和最大池化层是对称的,我们在下采样的时候会做一次最大池化,然后要记住那些最大值出现的位置,在上采样对应的最大去池化层中,会把那些最大值的位置赋值,其它位置都取零。这种方法凸显出了特征图中的不均匀性,保留了空间信息,是好的。

-
卷积转置 transpose convolution(也叫去卷积,deconvolution)
以上方法其实都是固定采样,没有学习过程。类似于步长较大的卷积层可以用来做下采样,我们提出了卷积转置层来做可学习的上采样层。
具体过程:我们取输出矩阵中的一个值,例如左上角第一个值,它是一个标量,然后我们把卷积核矩阵中的所有元素都乘上这个值,作为输出矩阵中对应位置的结果。对于重叠的感受野,我们直接求和即可。

交叉熵损失 cross entropy loss???
如果输出结果的值可以是连续的(如坐标),那么一般损失函数选择回归函数,如L1、L2损失函数;
如果输出的值是离散的(如分类结果,仅能是0-9这十个整数),损失函数一般选择交叉熵 / softmax / SVM损失函数。
二、识别和分割 classification plus localization
注:这个识别和分割的特点在于,我们提前知道图片中有几个物体,所以我们只需要产生对应数量个Bbox来做localization即可,同时对Bbox里的物体做分类。这属于固定化回归预测问题,对象都是固定数量的。
而detection与之不同的地方在于我们不知道图片中有几个物体,需要我们自己做检测。

这个任务的实现方法非常类似于classification,只是我们把输出结果改成了两个,一个类别class score,还有一个Bbox的四个边界坐标。所以实际上我们要算两个loss,通常需要选择一个超参数来对这两个loss做加权求和。但由于这个超参数会直接对loss的值产生影响(不同于以往的超参数,我们会取很多值来看它们对loss的影响是怎样的,然后选loss小的那个),因而在选择这个超参数的时候,往往不看loss,而是参考一些benchmark metric的度量结果来选表现最好的那个超参数。
类似已知目标个数来做预测的任务还有简单版的pose estimation:假设图片中仅有一人,一个人的关节数量为14个,那么我们最后就一定会输出14个坐标作为结果。
三、目标检测 object detection
有一些指定的类别(可以是多个类别),我们希望在图片中找到所有属于这些类别的object,并为他们画好Bbox。目标检测与识别加分割的不同点在于我们无法提前得知图像中有多少个目标物体。
1、滑动窗口算法 object detection as classification
(1)思想:将整个图像分割成若干个小块,对于每个小块,做一个classification的工作,如下面这个例子判断每个小块是否属于狗/猫/背景。

滑动窗口的关键问题在于由于目标物体的数量、大小、位置啥啥啥都是不确定的,我们就需要无数无数个窗口,用它们把图片裁成小块,输入到一个巨大的卷积网络里,并且预测出来的大多数结果都是没用的,这对计算量是一个很大的浪费。
2、候选区域算法 region proposals
啊于是我们有了候选区域算法(RCNN的老朋友了属于是)
候选区域法通常会在输入图像中寻找点状区域blobby regions,然后选出指定数量的小区域(RCNN里是2000个),这样相当于从盲目的暴力搜索法改成了有目标的搜索方法。
一个典型的候选区域算法就是选择性搜索selective search!!!

RCNN的问题:慢慢慢!!!训练慢,占用空间大,测试也慢!
Fast R-CNN:
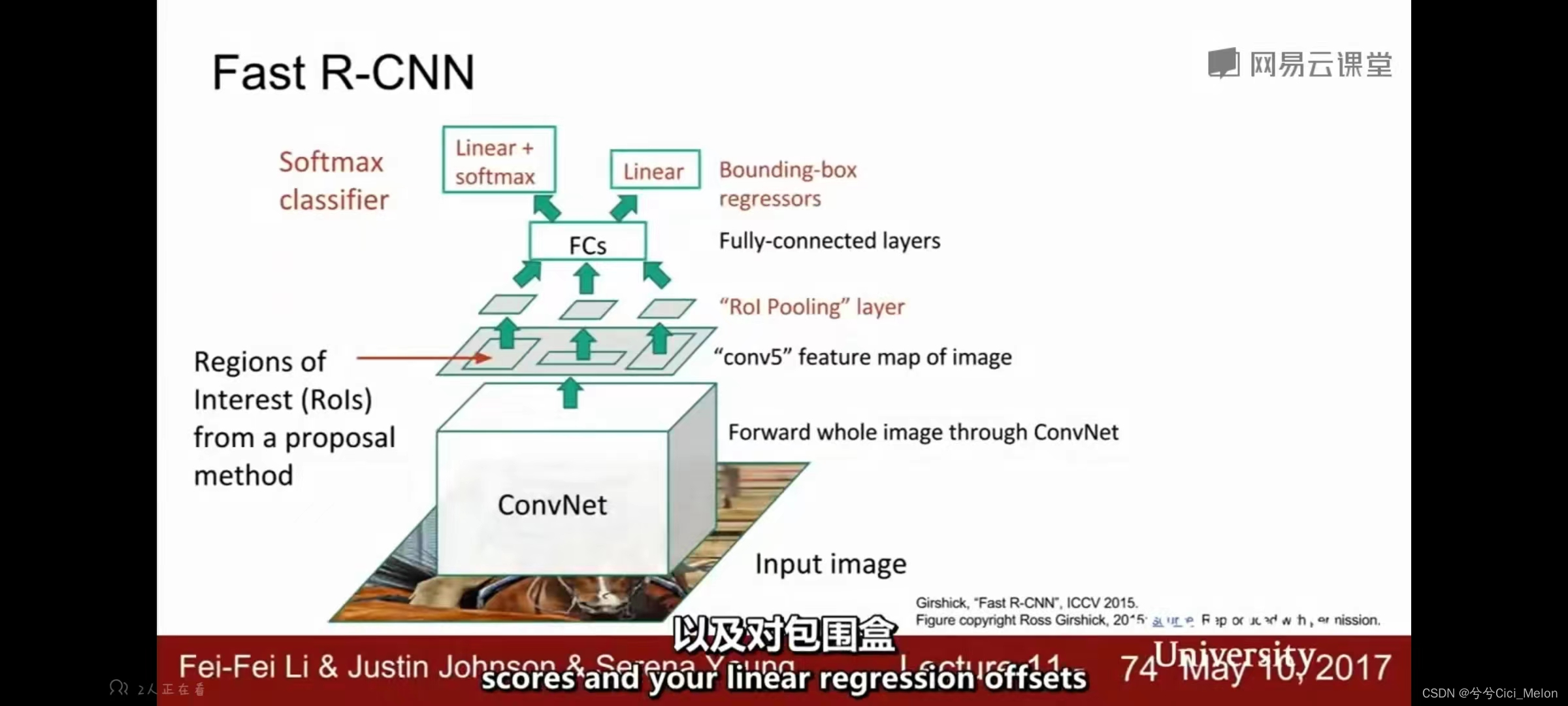
直接将整个图像作为卷积网络的输入,得到对整个图像的高分辨率特征映射。之后我们仍然要用一些固定的(即已经定义好参数的)selective search算法来提前小块,但区别于之前直接在image上进行图片块的裁剪,现在我们要从这个convNet输出的feature map里提取出来一些卷积块。这使得我们可以重复使用卷积网络过程中的很多复杂的计算过程。
之后我们就把这些小卷积块做一些reshape,也就是Roi Pooling那一步,让它们的尺寸都相同,再之后输入到全连接层里,最后用softmax做分类,同时用Bbox regression来算线性回归补偿微调Bbox的位置。
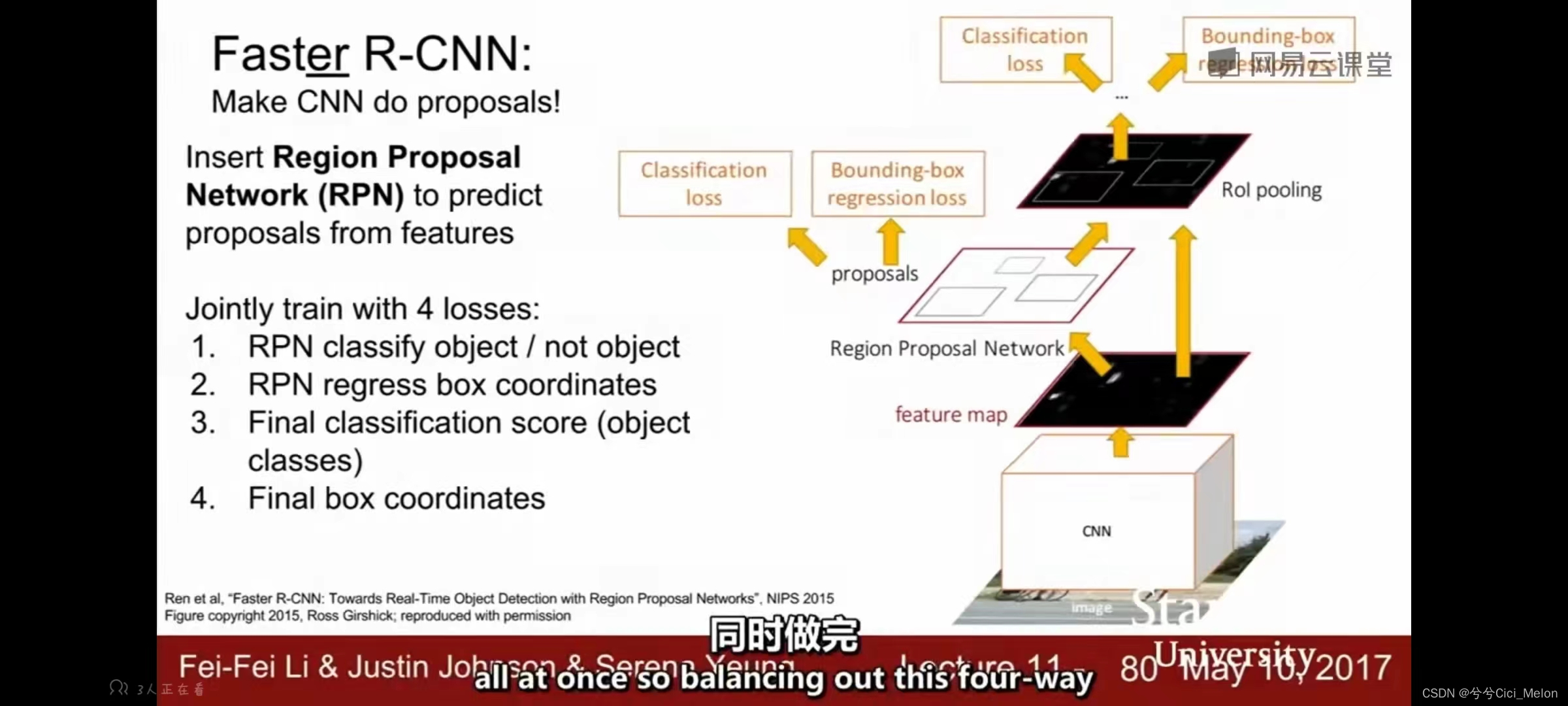
Faster R-CNN:
Fast R-CNN的主要瓶颈在于候选区域的选取,也就是selective search的部分。之前我们用的都是一个固定的selective search的算法,里面的参数是不可学习的,现在在Faster R-CNN中,为了解决这个瓶颈,我们提出一个selective search network,它里面的参数也是需要网络学习出来的,结构如下。这其中就涉及到四个loss值,是多loss优化问题。
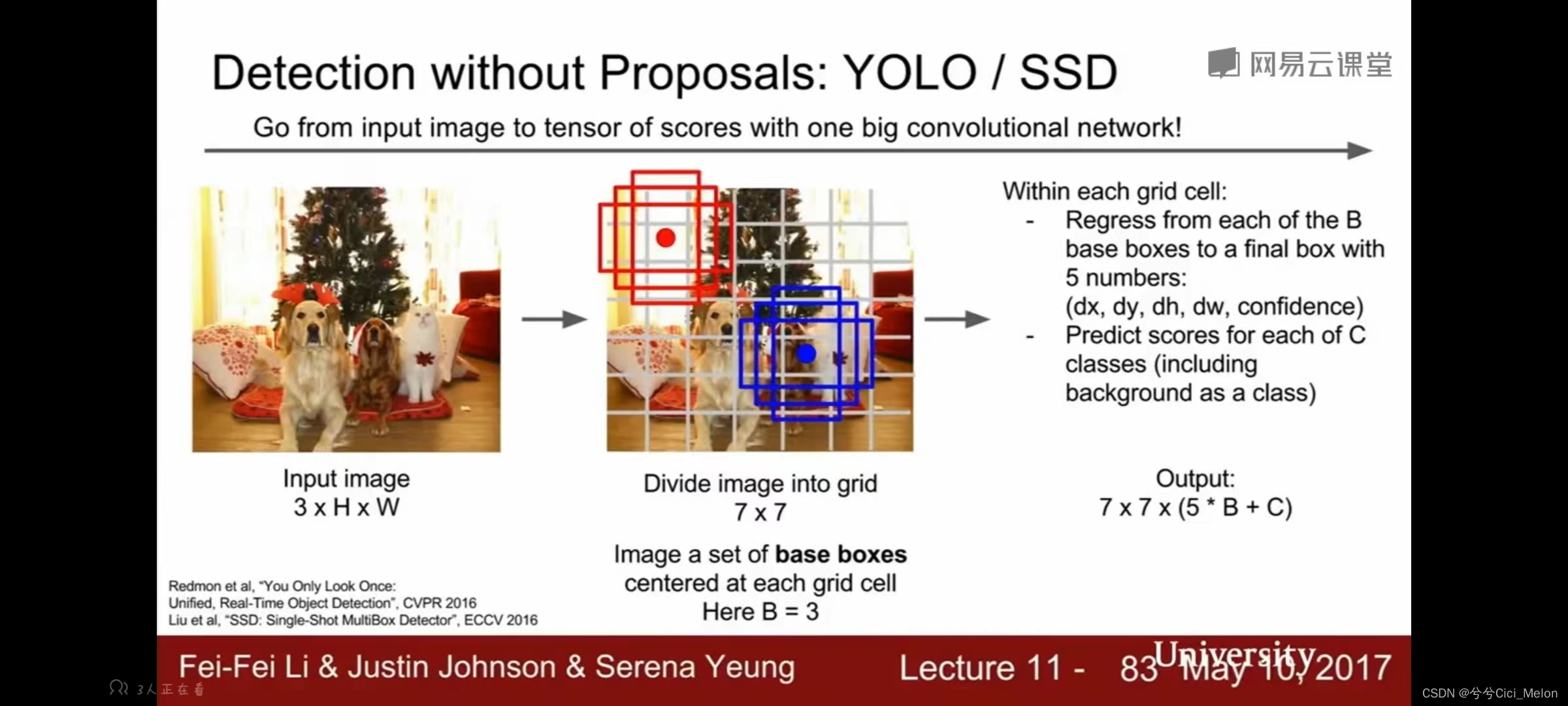
3、不使用候选区域的detection方法
YOLO(you only look once)/ SSD(single shot detection):
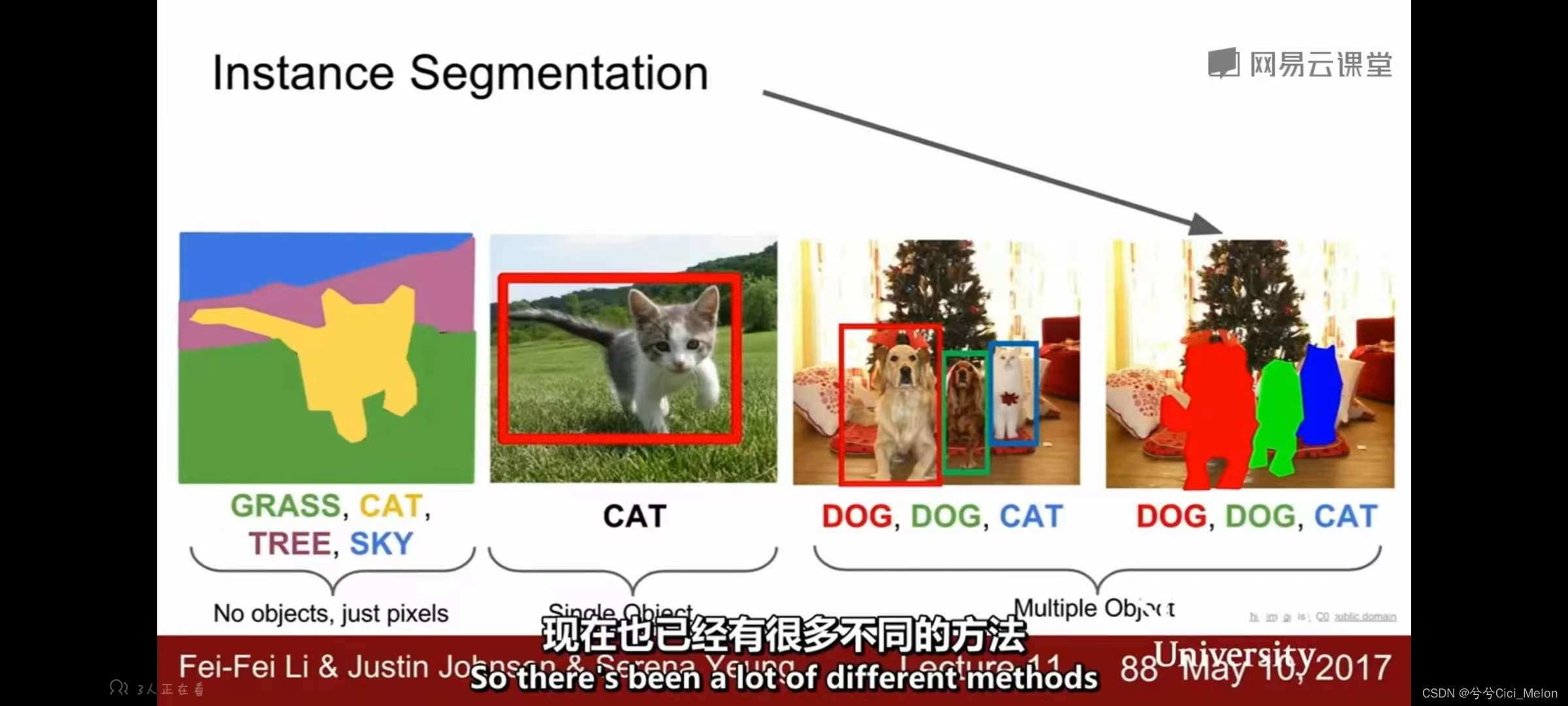
四、实例分割 instance segmentation
在语义分割中,我们不会区分不同的实例,比如那两个牛就会分割到一起去。实例分割相当于是语义分割和目标检测的结合,我们需要检测出不同的实例,同时提供一个像素级别精度的分割。
Mask R-CNN:
模型的前半部分非常类似于Fast R-CNN和Faster R-CNN,但它最后一部分是一个语义分割的迷你网络,相当于对每一个检测出的Bbox中的像素再做一次语义分割的工作。对于人来说它还可以做姿态估计。


















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









