







所有图片均来自官方PPT网站Index of /slides/2022
目录
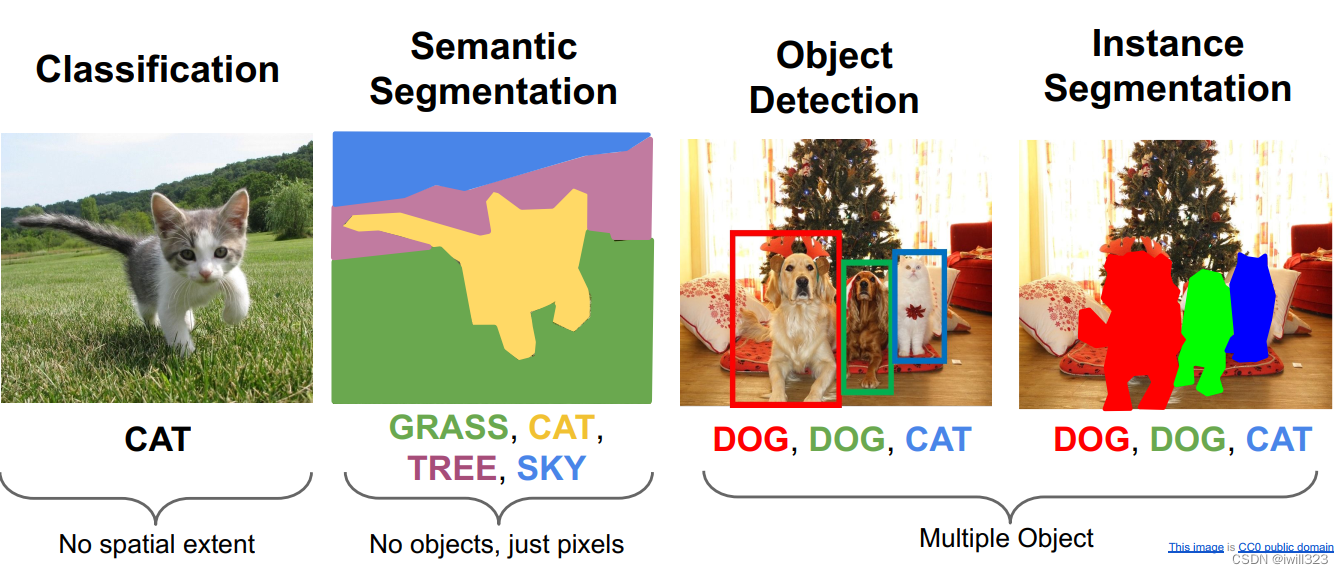
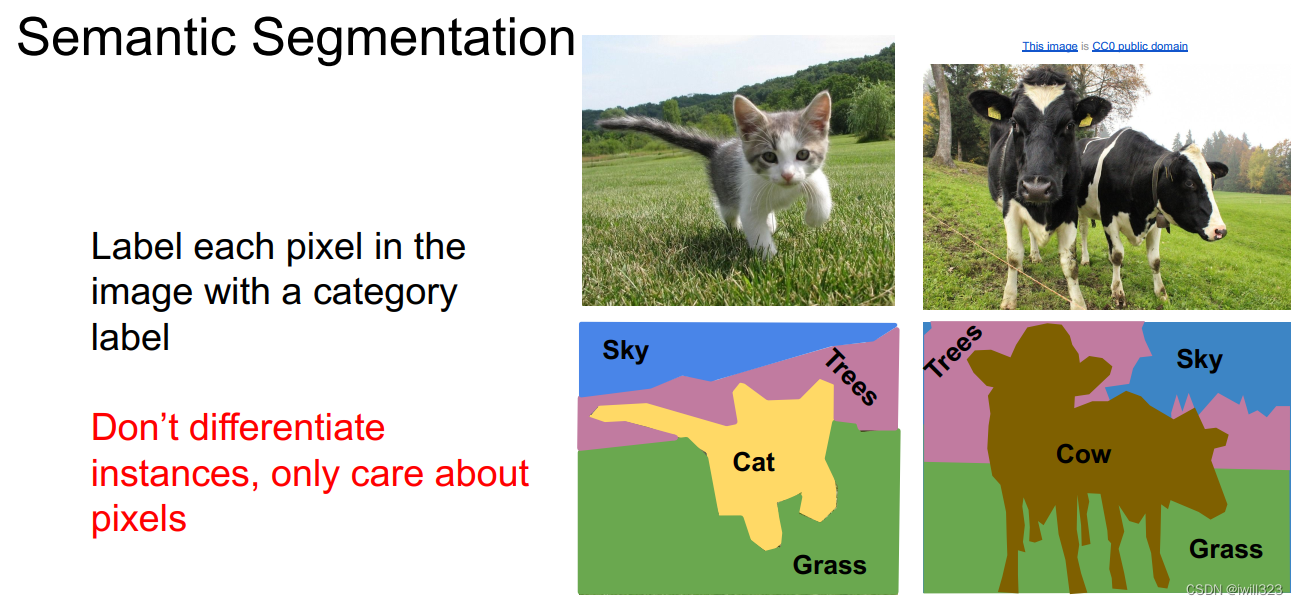
语义分割Semantic Segmentation
对图中的每一个像素做分类。训练的时候,图片中每个像素点都有对应的分类标签(真值),损失函数是每个像素点的softmax,可以求和或者求平均。测试的时候,对图片的每个像素进行分类。
语言分割并不区分同类目标,比如下面的cow,虽然是两头牛,但是他们包含的像素属于同一类。
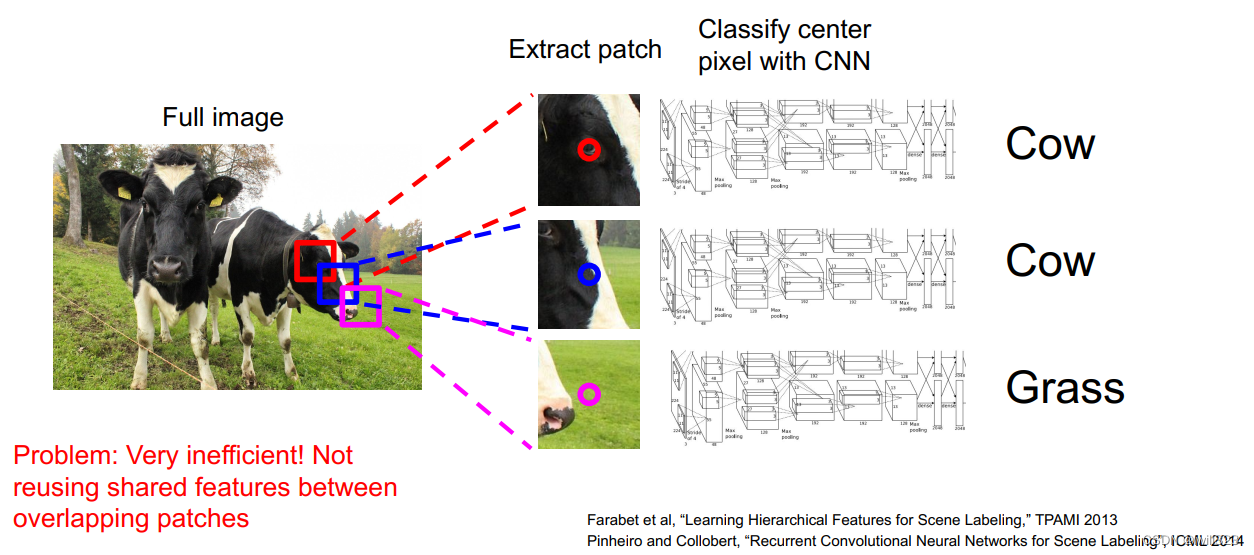
方法推演
1.Sliding Window:如果仅仅盯着一个像素进行分类,则会缺乏附近像素的信息,难以操作;将图像分成不同的像素块送入卷积网络,则这样的像素块太多,计算复杂;各小块之间的计算(提取到的特征)不能共享,效率低
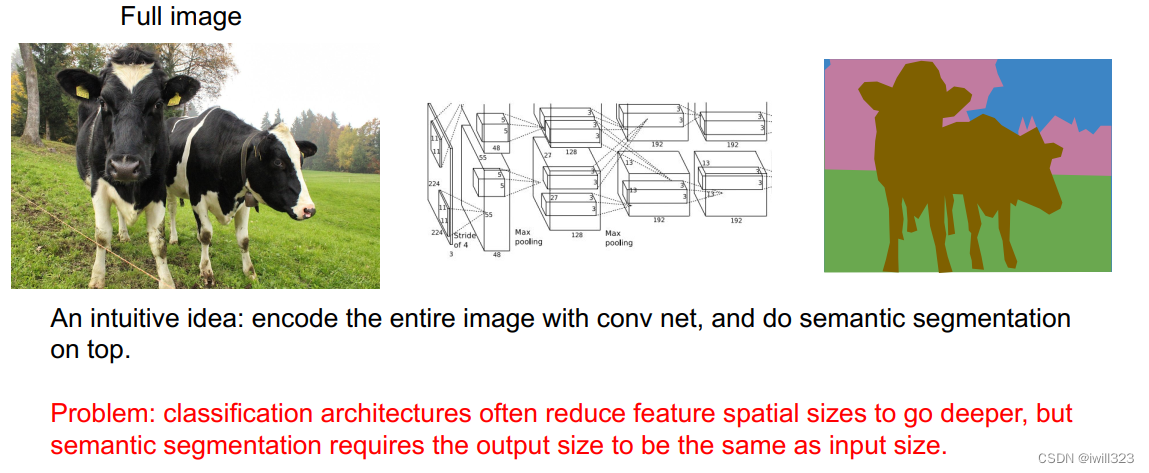
2 Convolution:将整个图片送入卷积网络,问题是卷积网络在计算中会丢弃图片像素,输出和输入尺寸不一样。
3 Fully Convolutional: 不用下采样。问题是计算昂贵。
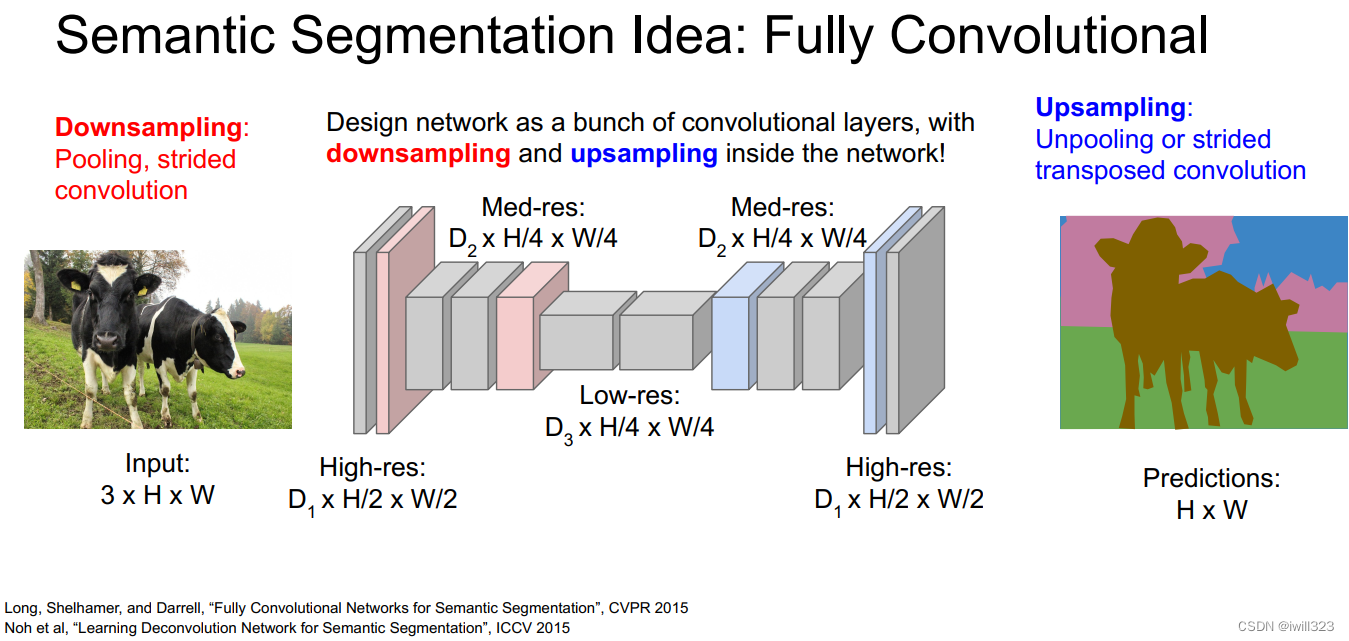
4 Fully Convolutional Network(FCN):过一次 forward 处理,对所有像素进行分类。相对于一般的 CNN 包含全连接层,FCN 将全连接层替换成发挥相同作用的卷积层。在物体识别中使用的网络的全连接层中,中间数据的空间容量被作为排成一列的节点进行处理,而只由卷积层构成的网络中,空间容量可以保持原样直到最后的输出。
仅仅很少的层数在图像原尺寸上做处理,然后下采样。FCN 的特征在于最后导入了扩大空间大小的处理。基于这个处理,变小了的中间数据可以一下子扩大到和输入图像一样的大小。FCN 最后进行的扩大处理是基于双线性插值法的扩大(双线性插值扩大)。FCN 中,这个双线性插值扩大是通过去卷积(逆卷积运算)来实现的
全连接层中,输出和全部的输入相连。使用卷积层也可以实现与此结构完全相同的连接。比如,针对输入大小是 32×10×10(通道数 32、高 10、长 10)的数据的全连接层可以替换成滤波器大小为 32×10×10 的卷积层。如果全连接层的输出节点数是 100,那么在卷积层准备 100 个 32×10×10 的滤波器就可以实现完全相同的处理。像这样,全连接层可以替换成进行相同处理的卷积层
上采样
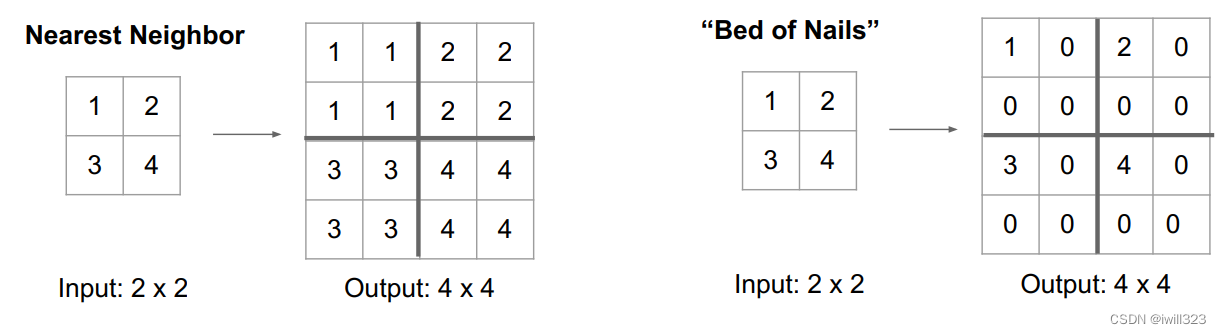
nearest neighbor: 复制数据
bed of nails: 将数据放在左上角,其他位置补0
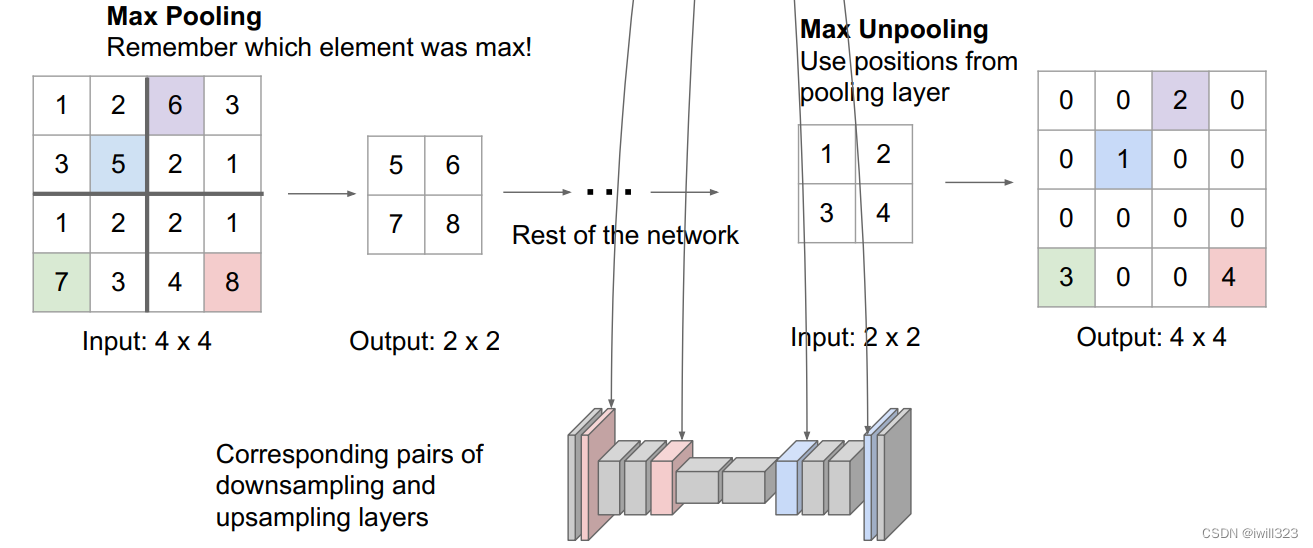
max unpooling: 记住池化过程中取得元素的位置,unpooling的时候把元素放在该位置,其他位置补0
转置卷积
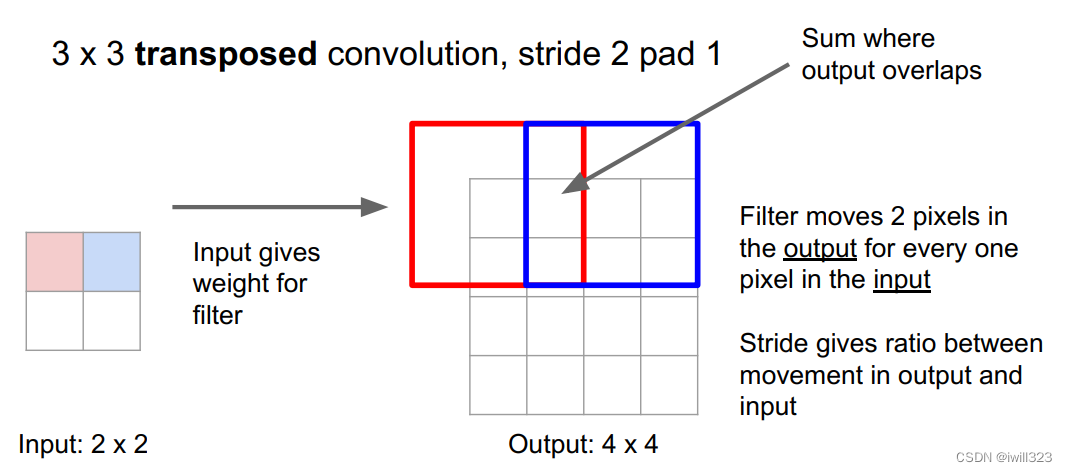
另一种上采样方式。用一个权重矩阵与输入相乘(输入可能需要经过填充处理),得到尺寸更大的输出。在感受野叠加的地方需要求和。
我是这样理解的:每一个输入元素和权重矩阵都要相乘,比如红色的元素和权重矩阵相乘后得到的是右侧红色的框,蓝色的元素和权重矩阵相乘得到了右侧蓝色的框。由于步长设置为2,所以蓝色的框要向右移两位,重叠的地方求和(视频中Justion说也可以不求和)。但是我觉得输出结果似乎应该是3乘3,即右图最右边那一列应该被pad掉
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3146
3146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









