






存在问题:降雨径流建模是一个复杂的非线性时间序列问题,故本文重点是处理时间序列问题
提出方法:本研究提出了一个基于LSTM和seq2seq结构的预测模型来估算每小时降雨径流
详细方法:本文提出了一个连续的未来24小时的每小时降雨径流模型,该模型使用了新的深度学习技术,包括LSTM、seq2seq学习、ReLU激活函数、辍学正则化、小批量训练和GPU加速
数据集:河流流量(美国地质调查局,2016年)、降水(Lin,2011年)、每月ET数据集(Krajewski等人,2017年);虽然输入包含降雨、径流和每月的ET数据,但土壤水分等因素可能已经被这种深度学习模型间接地表示出来。
对比试验:多元线性回归、支持向量机、高斯过程回归(GPR)和常规LSTM
缺点:比起物理模型(NWSDE7天河流预测),预测时间较短,而且操作设置中不足以进行洪水警报
主要内容:
1.使用LSTM(存在局限性:LSTM要求输入和输出有相同的时间步长)
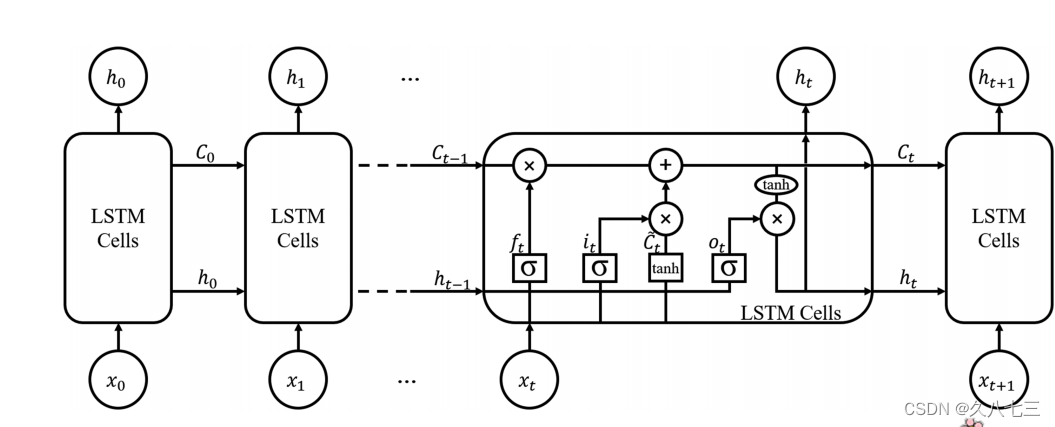
2.提出LSTM‐based seq2seq mode可以允许在不同的输入和输出时间步长上建立模型,用来预测未来24小时的径流预测
目标函数:
![]()
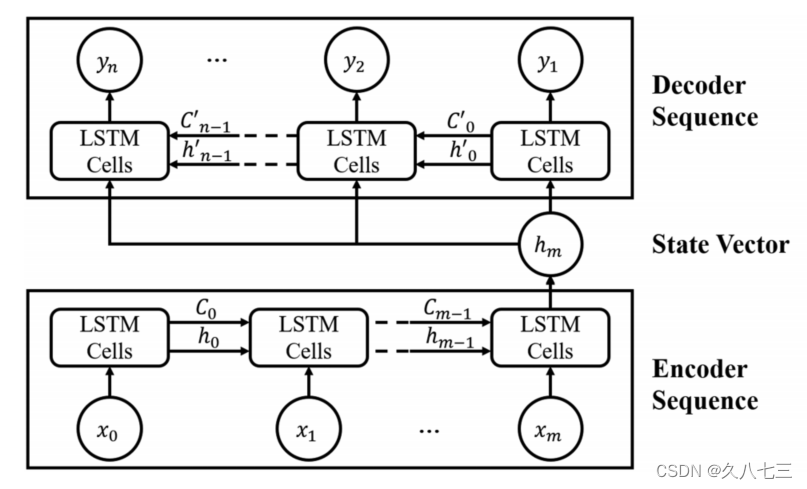

目的:建立一个适用于不同流域的模型,而不是追求最高的准确性
- 为了避免过拟合,得到稀疏结构,在密集层训练过程中,采用0.2的退出率随机删除20%的节点间神经连接
实验过程
该案例研究的现有数据包括来自美国地质调查局(2016年)的径流数据、15分钟雷达第四期降水数据(Lin,2011年)和来自爱荷华洪水中心的每月ET数据(Krajewskietal.,2017年)。采用2012-2017年水年(WYs)数据进行建模。这些年份包括每个流域的正常、极端干燥和潮湿的条件。选择干年份和湿年份进行训练,并使用正常年份进行测试。
对数据和模型设置进行了几个预处理步骤。首先,将降雨数据汇总为小时,径流数据平均汇总为小时。当间隙小于12小时时,对缺失数据采用线性插值法。在所有输入数据上使用最小最大缩放,以标准化输入,更好地初始化参数,并加快收敛速度。从雷达第四阶段获得的降雨数据的高分辨率为0.05°。因此,为了减少输入维度和建模噪声,对于每一小时,地下流域的总降雨量被用作输入降雨量。
注意点
- 在牛津站对从12小时到96小时的历史降雨和径流的观测时间步长m进行了测试
- 降雨预处理:在应用最小最大尺度之前,将SMA方法应用于牛津站的降雨数据,窗口大小n从2到10。降雨移动平均线是建模的重要组成部分,降雨的SMA有助于降低噪声,提高模型效率
- 虽然ET数据不是每小时的时间序列输入,但它们仍然显著影响了3小时以上预测的模型效率。这表明,流域大小、高程信息、土地覆盖等非序列信息可以包含在seq2seq模型中,从而在未来为多个流域开发一个更广义的模型
水文模型常用评价标准:NSE(NSE的范围从负无穷到1,其值越接近1,模型性能越好)

其他性能统计数据包括皮尔逊相关系数(r)、百分比偏差(BIAS)和归一化均方根误差(NRMSE)用于模型评估
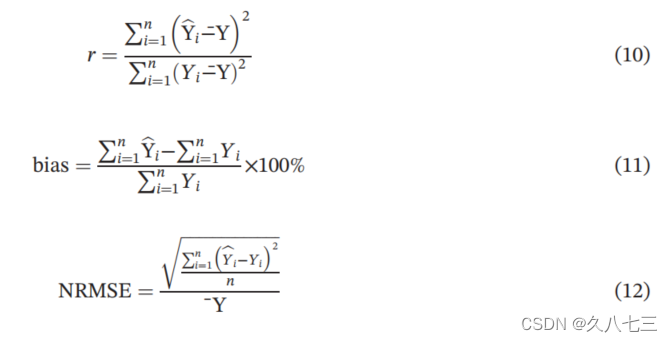















 8212
8212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









