






目录
1.NRM-Generalized and NRM-Generalized-Distributed
2.Model Settings and Evaluation
本文主要贡献:通过训练单一模型可以获得的水文深度学习模型的时空泛化能力。
补充基本知识:
2.前置时间:从流程开始到结束所经过的时间量
3.集中时间(Tc):径流从流域中水力最远的点留到出口所需的时间。
广义模型的局限性:1.需要大量数据;2.一些分水岭特征(即基岩的深度)在数据中无法得到;3.大流域和小流域的水流行为在变化的时间尺度上是不同的
1.NRM-Generalized and NRM-Generalized-Distributed
NRM-广义模型是一种集总模型,它利用排水量尺度的时间序列数据和物理特征作为输入,同时预测所有流域的河流流量。该区域广义模型包括流域面积、土壤类型、坡度等物理特征,而原始NRM中没有考虑这些特征,因为每个模型都是独立训练的,因此每个NRM的流域特征都是恒定的
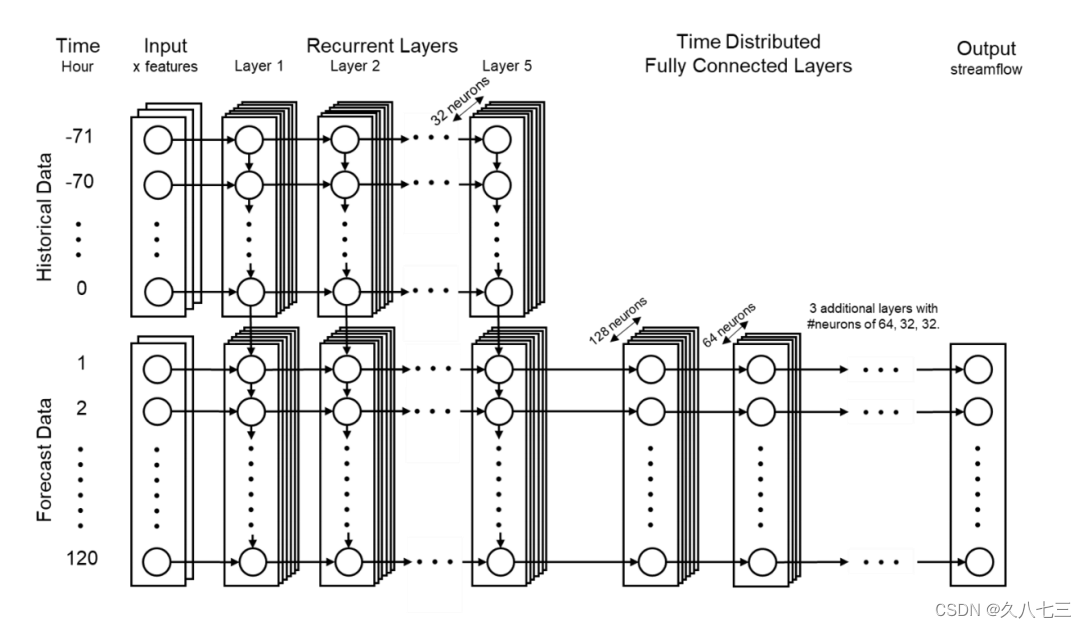
NRM-广义模型考虑了每个流域的4个物理特征:基于最长路径的平均坡度、面积、集中时间(Tc),以及12种土壤类型在流域中的比例。(假设这些物理特征是随着时间变化的)。这些数据,结合小时降水量(Seoetal.,2019)、小时流量和月蒸散量,作为本研究的输入(18个特征)(这些数据都要经过预处理)
-
watershed-level NRM model
损失函数:

-
the NRM-Generalized
损失函数:
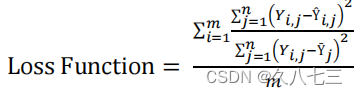
它是基于不同的时间步长计算出来的,在一个训练实例中,然后计算出流域平均值。所设计的损失函数保证了在优化过程中考虑了所有不同的流域大小和流量。
-
NRM-Generalized-Distributed
nrm广义分布是一种半分布模型,将每个测量的流域视为大流域的子流域,所有的时间序列数据和物理特征都仅基于子流域。(不理解这句话)
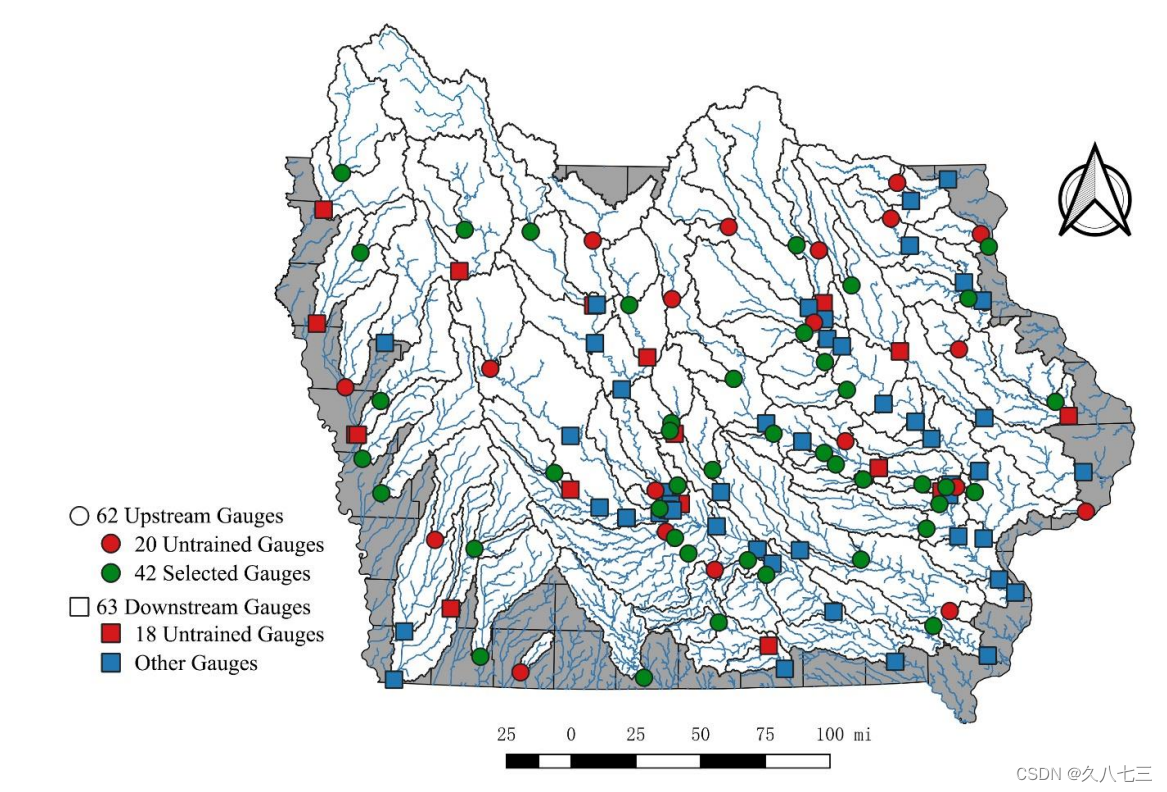
2.Model Settings and Evaluation
- 利用上下游关系,创建了两个独立的数据集,分别包含18和19个输入特征
- 输入来自125个USGS测量的NRM广义模型和NRM广义分布模型
- 从2014-2017年、2012-2013年和2018年水务年的数据中,分别创建了三个不同的子集(训练、验证和测试数据集)
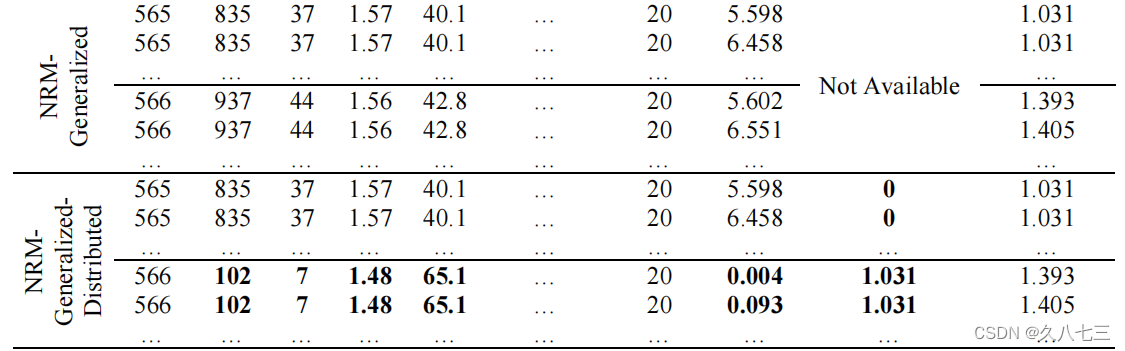
- 性能指标:
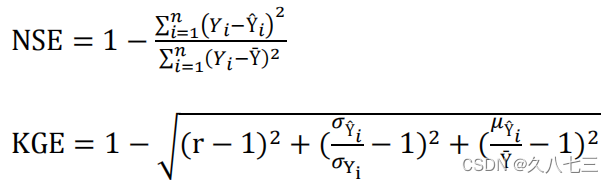
- 不同流域的浓度变化时间差异很大,因此在同一前置时间内比较不同流域的预测结果是不公平的。因此,采用无量纲时间轴来进行模型在时间序列中的性能的纵向比较。在本研究中,无量纲时间轴被定义为前置时间与浓度-时间的比值。
3.Case Studies
本文进行了四次实验:
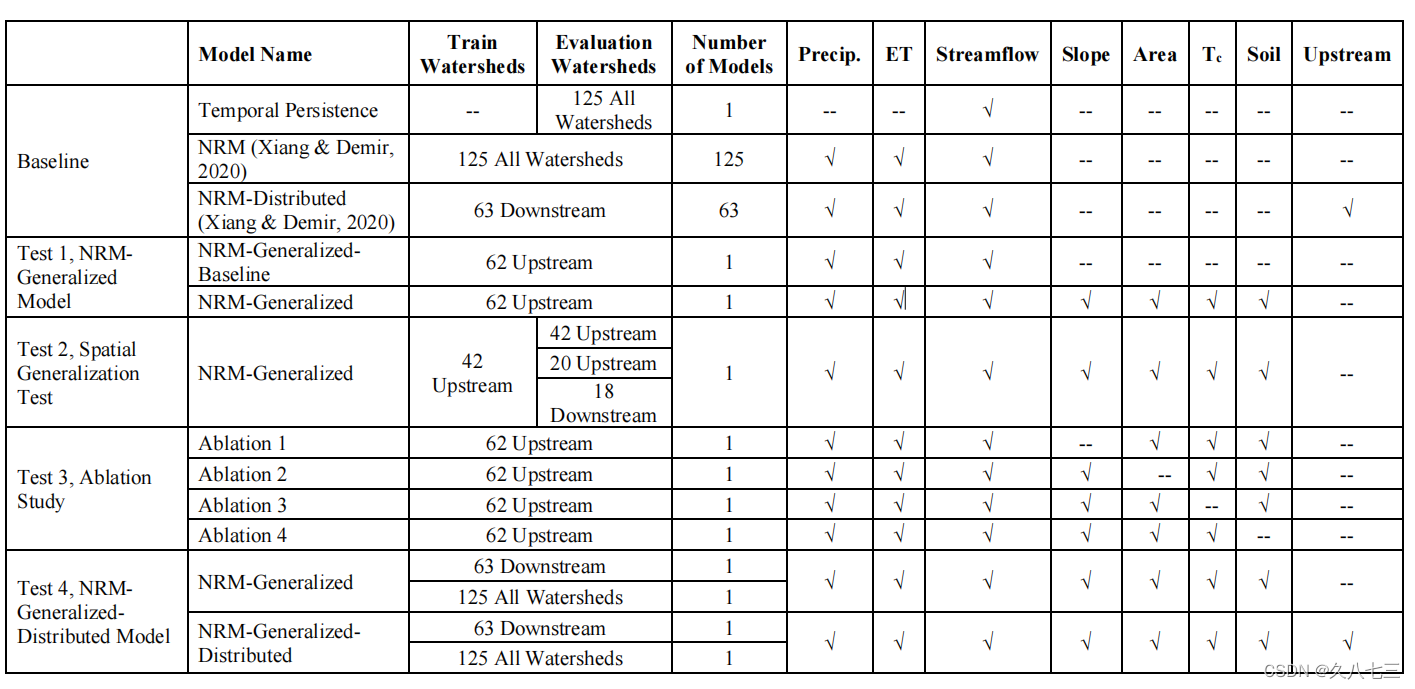
1.第一个测试使用了62个独立的上游仪表,应用所提出的NRM-广义模型在独立的上游测量来评估模型的有效性。
2.在第二个测试中,我们评估了该模型在未经训练的流域上的空间泛化能力。具体来说,我们从62个上游流域中随机选择42个上游流域,训练了一个新的NRM-广义模型。我们将该模型应用于42个经过训练的量规以及20个未经训练的上游量规。我们按面积对62个独立的上游流域进行了分类。每对第三个流域进行标记(即流域No.3、6、9等),并对42个未标记的上游流域进行训练。因此,20个未经训练的上游指标被使用来评估模型,验证一个完全不同的分水岭集的通用性。我们还将训练后的模型应用于位于42个训练后的流域下游的18个额外流域,以评估扩展的通用性。在本次测试中,我们只使用带有绿色标记的仪表来开发模型,它们被应用于绿色的上游仪表和红色的下游仪表上。
3.第三个测试,消融研究,研究所有四个物理特征是否有必要加入到广义模型中。在这个测试中只训练和评估62个上游仪表。
4.第四次测试中,我们对爱荷华州63个下游流域和所有125个下游流域的两个新的区域模型采用了NRM-广义分布式方法。如表4所示,我们在这个测试中训练了四个模型。下游模型在63个仪表上进行训练;整个模型在125个仪表上进行训练。此外,我们将分布式结构应用到广义模型中。在分布式模型中,使用未来观察到的上游流量进行训练,并使用上游仪表的模型输出进行测试和评价。最后,我们在这个测试中评估了125个流域的最佳模型,以进行最终的评估和可视化。
4.性能基准
- 第一个基准是自相关(时间上的时间持久性):可以作为评估未来中短期河流流量估计的替代方案
- 由于本研究旨在探索潜在的泛化能力,其主要基准是基于分水岭的模型NRM(NRM广义模型)和NRM-分布。NRM和NRM-分布模型是基于流域的模型,分别在每个仪表上进行训练和测试。因此,将NRM广义模型与NRM进行比较就像将一个模型与125个不同的模型进行比较
- 第三个基线是NRM-广义基线,它考虑了时间序列特征,包括来自所有流域的降水、ET和水流,但不考虑流域水平特征。该模型的特征见表4测试1。
5.结论
1.test1结果表明坡度、面积、集中时间换个土壤类型等其特征有助于有效的表征不同流域之间的降雨径流行为
2.test2结果表明,该模型提供了与以前的模型可比较的结果,可以适用于外部独立流域和扩展的下游流域,但精度下降有限。这进一步证明了本研究中提出的模型的普遍性和可转移性。在未来的实验中,更多的数据可能会提高精度
3.test3结果表明包含这四个分水岭特征有助于减少这些特征之间的偏差。
4.test4结果表明只有当所有特征都经过有效的预处理和具有合理的方差时,区域广义模型才能提供更好的结果。
5.局限性:
我们的广义模型在小流域和低流量流域上也可能表现不佳;
我们的研究结果还强调了准确的降水预报输入对于操作实时应用的深度学习模型的重要性。这些都是使用深度学习的广义模型的一些局限性
6.展望:物理特征和过程的考虑有限。如本研究所述,考虑流域尺度物理特征和半分布结构的深度学习模型可以使用区域模型在多个流域上工作,而牺牲的精度有限。我们呼吁水文学深度学习研究,在未来包括更多的领域知识和物理特征。















 5875
5875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









