






目录
一、概率图
概率图的框架
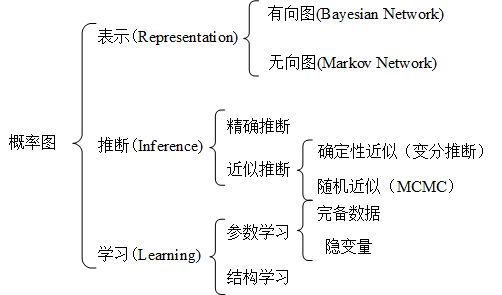
由上图可知,PGM(概率图)主要分为3个部分:
- 表示(Representation):是将实际的问题,简化成概率图的形式表达出来。
- 推断(Inference):通过上面生成的概率图模型,推断出我们在已知条件下,想要询问的变量概率。
- 学习(Learning):用真实世界数据进一步拟合我们的模型,可以通过改变模型参数或者模型结构去拟合数据。
--------------------------------------------------------------------------分割线-------------------------------------------------------------------
由于概率图模型的知识面十分的广泛,本人只研究了贝叶斯网络的图模型部分,因此,暂时只讲述贝叶斯网络部分。
二、贝叶斯网络
什么是贝叶斯网络?
贝叶斯网络是概率图模型之一,是一个有向无环图模型。一个贝叶斯网络是由变量节点和连接节点的有向边构成。

每个节点通过计算都有其条件概率表(CPT)(可能是先验概率也可能是后验概率),并且条件概率表只与先验概率和指向它的父节点有关。
贝叶斯网络结构怎么构建?
这块其实对应的是概率图模型中学习的部分,它分为结构学习和参数学习两部分。
结构学习
当我们有专家经验(说白了就是自己对数据的理解)时,我们可以自己搭建出一个贝叶斯网络。
若我们没有专家经验或者想自动搭建网络,那么我们可以通过计算机对数据的理解(代码实现)来搭建一个贝叶斯网络,因此,这里就引出了一些搭建网络的算法,常用的是评分算法(后续会更新)。
参数学习
当网络结构已知时,也就是各个变量节点之间的依赖关系已知,这时贝叶斯网络的学习过程只需要对训练样本计数,估计每个节点的条件概率表即可参数学习就是要得到条件概率表,当数据量特别大的时候,我们就需要通过算法来实现自动学习。
小结:
到这你应该知道构建一个贝叶斯网络的思路了。
在实际搭建网络的过程中,你会遇到很多问题,因此,会有一些解决的方法。
接下里,我会讲述一些概率的基础知识,然后将一个具体的计算实例。
概率图研究的是高维随机变量,因此学习概率图之前我们需要一些概率知识的储备。
三、概率知识
首先,我们要知道四大准则,这是我们最常用的工具。
加法法准则
我们以二维随机变量为例:
P
(
x
1
)
=
∫
P
(
x
1
,
x
2
)
d
x
2
P(x_1)=\int P(x_1,x_2){\rm d}x_2
P(x1)=∫P(x1,x2)dx2
乘法准则
我们以二维随机变量为例:
P
(
x
1
,
x
2
)
=
P
(
x
1
)
P
(
x
2
∣
x
1
)
=
P
(
x
2
)
P
(
x
1
∣
x
2
)
P(x_1,x_2)=P(x_1)P(x_2|x_1)=P(x_2)P(x_1|x_2)
P(x1,x2)=P(x1)P(x2∣x1)=P(x2)P(x1∣x2)
链式准则
P
(
x
1
,
x
2
,
⋯
,
x
p
)
=
∏
i
=
1
p
P
(
x
i
∣
x
1
,
x
2
,
⋯
,
x
i
−
1
)
P(x_1,x_2,\cdots,x_p)=\prod_{i=1}^p P(x_i|x_1,x_2,\cdots,x_{i-1})
P(x1,x2,⋯,xp)=i=1∏pP(xi∣x1,x2,⋯,xi−1)
贝叶斯准侧
P
(
x
2
∣
x
1
)
=
P
(
x
1
,
x
2
)
P
(
x
1
)
=
P
(
x
1
,
x
2
)
∫
P
(
x
1
,
x
2
)
d
x
2
=
p
(
x
2
)
P
(
x
1
∣
x
2
)
∫
p
(
x
2
)
P
(
x
1
∣
x
2
)
d
x
2
P(x_2|x_1)=\frac{P(x_1,x_2)}{P(x_1)}=\frac{P(x_1,x_2)}{\int P(x_1,x_2){\rm d}x_2}=\frac{p(x_2)P(x_1|x_2)}{\int p(x_2)P(x_1|x_2){\rm d}x_2}
P(x2∣x1)=P(x1)P(x1,x2)=∫P(x1,x2)dx2P(x1,x2)=∫p(x2)P(x1∣x2)dx2p(x2)P(x1∣x2)
其次,知道这四大准则,那么我们就需要了解他们在图模型中的应用。
概率分布
概率分布就是每个变量(节点)发生的概率。
比如:掷硬币,那么结果就是正/反两种情况,或者天气可能有晴天(sun)、下雨(rain)、大雾(fog)这三种情况,每一个变量的累加和一定是1。

联合概率分布
我们通过两个变量(温度和天气)之间的关系,最终可以得到一个联合概率,我们可以通过这样一个联合概率表,求得他们之间不同概率分布下的概率大小。我们这么说点抽象,通过下面P(T,W)概率来表示联合概率。

通过这个联合概率我们可以推断出这张表上我们想要的任何变量概率。假如我们想求P(T)和P(W)的概率,只需要将联合概率求边缘化就可以得到。

到这以后你可能会对这张表怎么来的有疑问?后面我们会讲到,如果没有就算了。
条件概率
条件概率在前面的四大公式中有用到,这里简单说一下,就是在B发生的条件下,A发生的概率,即P(A|B)。
P
(
A
∣
B
)
=
P
(
A
,
B
)
/
P
(
B
)
P(A|B)=P(A,B)/P(B)
P(A∣B)=P(A,B)/P(B)
从公式中也能看出,我们在计算条件概率的时候,还需要联合概率分布。
归一化技巧
我们在计算概率的时候,往往算的的结果的总概率和不为1,这个时候就要归一化。
其实这个很简单,看一个例子就知道了。

再举一个综合一点的例子(自己理解去吧):

小结:
到这,我们将之前所学的概率知识(可能你没学过,没关系)结合到条件概率表中,令你对其有了一定的了解。
四、贝叶斯网络知识
网络

这就是一个有向无环的贝叶斯网络,节点表示随机变量
{
d
,
i
,
g
,
s
,
l
}
\{d,i,g,s,l\}
{d,i,g,s,l}
它们可以是观察到的变量、隐变量、未知参数等。认为有因果关系的变量就可以用有向弧连接。
以这个网络为例,我们可以写出它的联合概率密度:
P
(
d
,
i
,
g
,
s
,
l
)
=
P
(
d
)
P
(
d
∣
i
)
P
(
g
∣
d
,
i
)
P
(
s
∣
d
,
i
,
g
)
P
(
l
∣
d
,
i
,
g
,
l
)
P(d,i,g,s,l)=P(d)P(d|i)P(g|d,i)P(s|d,i,g)P(l|d,i,g,l)
P(d,i,g,s,l)=P(d)P(d∣i)P(g∣d,i)P(s∣d,i,g)P(l∣d,i,g,l)
条件独立性
x
A
⊥
x
B
∣
x
C
x_A\bot x_B|x_C
xA⊥xB∣xC
也就是说,在给定父节点的条件下,每个节点与其非后代节点条件独立,但后代节点在被观测到的前提下,仍可作为证据影响该节点。
因此联合概率的表达式为:
P
(
x
1
,
x
2
,
⋯
,
x
p
)
=
∏
i
=
1
p
P
(
x
i
∣
P
a
x
i
)
P(x_1,x_2,\cdots,x_p)=\prod_{i=1}^p P(x_i|Pa_{x_i})
P(x1,x2,⋯,xp)=i=1∏pP(xi∣Paxi)
所以,我们可以将上述网络的联合概率写成:
P
(
d
,
i
,
g
,
s
,
l
)
=
P
(
d
)
P
(
i
)
P
(
g
∣
d
,
i
)
P
(
s
∣
i
)
P
(
l
∣
g
)
P(d,i,g,s,l)=P(d)P(i)P(g|d,i)P(s|i)P(l|g)
P(d,i,g,s,l)=P(d)P(i)P(g∣d,i)P(s∣i)P(l∣g)
结构
在一定的观测条件下,变量间的取值概率是否会相互影响。所谓的观测条件是这个系统是否有观测变量,或者观测变量的取值是否确定。当变量取值未知,通常根据观测变量取值,对隐变量的取值概率进行推理,这就是概率影响的流动性,它体现在结构上。
head to tail

结论:
若b被观测,则路径被阻塞(独立),即
c
⊥
a
∣
b
c\bot a|b
c⊥a∣b
证明:
当b被观测到时:
{
P
(
a
,
b
,
c
)
=
P
(
a
)
P
(
b
∣
a
)
P
(
c
∣
a
,
b
)
P
(
a
,
b
,
c
)
=
P
(
a
)
P
(
b
∣
a
)
P
(
c
∣
b
)
\left\{ \begin{array}{c} P(a,b,c)=P(a)P(b|a)P(c|a,b)\\ P(a,b,c)=P(a)P(b|a)P(c|b)\\ \end{array} \right.
{P(a,b,c)=P(a)P(b∣a)P(c∣a,b)P(a,b,c)=P(a)P(b∣a)P(c∣b)
联立上述两式
P
(
c
∣
a
)
=
P
(
c
∣
a
,
b
)
⇒
c
⊥
a
∣
b
P(c|a)=P(c|a,b)\\ \Rightarrow c\bot a|b
P(c∣a)=P(c∣a,b)⇒c⊥a∣b
tail to tail

同理,可以根据“head to tail”结构的推导,得出
c
⊥
b
∣
a
c\bot b|a
c⊥b∣a
head to head

这种结构比较特殊,默认情况下,a和b是独立。
证明:
当c没有被观测到时:
{
P
(
a
,
b
,
c
)
=
P
(
a
)
P
(
b
∣
a
)
P
(
c
∣
a
,
b
)
P
(
a
,
b
,
c
)
=
P
(
a
)
P
(
b
)
P
(
c
∣
a
,
b
)
\left\{ \begin{array}{c} P(a,b,c)=P(a)P(b|a)P(c|a,b)\\ P(a,b,c)=P(a)P(b)P(c|a,b)\\ \end{array} \right.
{P(a,b,c)=P(a)P(b∣a)P(c∣a,b)P(a,b,c)=P(a)P(b)P(c∣a,b)
联立上述两式
P
(
b
∣
a
)
=
P
(
b
)
⇒
a
⊥
b
P(b|a)=P(b)\\ \Rightarrow a\bot b
P(b∣a)=P(b)⇒a⊥b
六、概率推断
贝叶斯网络训练好之后就能用来回答一些问题,即通过一些属性变量的观测值来推测其他属性变量的取值。
这样通过已知变量观测值来推断查询变量的过程称为推断,已知变量观测值为证据。
最理想的是直接根据贝叶斯网定义的联合概率分布来精确计算后验概率,但是这样的精确推断是NP难的,当网络节点较多、连接稠密时难以精确推断,需要借助近似推断。

P(A)称为“先验概率”,即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为“后验概率”,即在B事件发生之后,我们对A事件概率的重新评估。
P(A|B)/P(B)称为“可能性函数”,这是一个调整因子,使得预估概率更接近真实概率。
推断又分为因果推断和证据推断。
因果推断
顺着箭头方向推断。得到贝叶斯网络之后我们就可以进行推理计算。这种因果推理是顺着箭头方向进行的推理结果的过程。
证据推断
逆着箭头推断的,即从结果逆流而上回溯原因的过程。
七、案例分析
现在我通过接下来这个案例,将这些数学知识运用到贝叶斯网络中做精确推断,解答一些前面的坑(条件概率表的应用)。
注: 此处我从此处学习的,只不过把里面具体计算结果推导了一遍,推导结果有出入,你们自己判断。
这是一个贝叶斯网络,里面的条件概率表是通过数据获得的(我猜的),我们用它解决一些计算问题。
其中,节点变量的定义:
- 试题难度(D): d 0 ( 低 ) , d 1 ( 高 ) d^0(低),d^1(高) d0(低),d1(高)
- 智力(I): i 0 ( 低 ) , i 1 ( 高 ) i^0(低),i^1(高) i0(低),i1(高)
- 考试成绩(G): g 1 ( A ) , g 2 ( B ) , g 3 ( C ) g^1(A),g^2(B),g^3(C) g1(A),g2(B),g3(C)
- 高考成绩(S): s 0 ( 低 ) , s 1 ( 高 ) s^0(低),s^1(高) s0(低),s1(高)
- 是否得到推荐信(L): l 0 ( 否 ) , l 1 ( 是 ) l^0(否),l^1(是) l0(否),l1(是)
该生能获得好的推荐信的概率?
在对该生其他信息一无所知的前提下,获得好的推荐信的概率为
P
(
l
1
)
=
∑
g
P
(
l
1
∣
g
)
P
(
g
)
=
∑
g
P
(
l
1
∣
g
)
∑
i
,
d
P
(
g
∣
i
,
d
)
P
(
i
)
P
(
d
)
P(l^1)=\sum_{g}{P(l^1|g)P(g)}=\sum_{g}{P(l^1|g)\sum_{i,d}{P(g|i,d)P(i)P(d)}}
P(l1)=g∑P(l1∣g)P(g)=g∑P(l1∣g)i,d∑P(g∣i,d)P(i)P(d)
具体计算(不一定对,有能力的自己推导一下):

如果得知该生智商不高,那么可能成绩g不太好,从而影响其推荐信的质量
P
(
l
1
∣
i
0
)
=
∑
g
P
(
l
1
∣
g
)
P
(
g
∣
i
0
)
=
∑
g
P
(
l
1
∣
g
)
∑
d
P
(
g
∣
i
0
,
d
)
P
(
d
)
P(l^1|i^0)=\sum_{g}{P(l^1|g)P(g|i^0)}=\sum_{g}{P(l^1|g)\sum_{d}{P(g|i^0,d)P(d)}}
P(l1∣i0)=g∑P(l1∣g)P(g∣i0)=g∑P(l1∣g)d∑P(g∣i0,d)P(d)

如果进一步得知课程比较简单,那么成绩可能得到提升,从而影响其推荐信的质量
P
(
l
1
∣
i
0
,
d
0
)
=
∑
g
P
(
l
1
∣
g
)
P
(
g
∣
i
0
,
d
0
)
P(l^1|i^0,d^0)=\sum_{g}{P(l^1|g)P(g|i^0,d^0)}
P(l1∣i0,d0)=g∑P(l1∣g)P(g∣i0,d0)

在对该生其他信息一无所知的前提下,其具有高智商的概率即为先验概率P(i^1)=30%,假设获知该生成绩g不太好,则可以怀疑其不具有高智商
P
(
i
1
∣
g
2
)
=
P
(
i
1
)
∑
d
P
(
g
2
∣
i
1
,
d
)
P
(
d
)
∑
i
,
d
P
(
g
2
∣
i
,
d
)
P
(
i
)
P
(
d
)
P(i^1|g^2)= \frac {P(i^1)\sum_d{P(g^2|i^1,d)P(d)}}{\sum_{i,d}{P(g^2|i,d)P(i)P(d)}}
P(i1∣g2)=∑i,dP(g2∣i,d)P(i)P(d)P(i1)∑dP(g2∣i1,d)P(d)

八、贝叶斯学习
贝叶斯学习分为结构学习和参数学习。
结构学习主要的方法四种:
- 基于评分搜索的方法
- 基于约束的方法
- 基于评分和约束相混合的方法
- 基于随机抽样的方法
参数学习的方法
- 频率派的最大似然估计(MLE)
- 贝叶斯学派的最大后验概率(MAP)
九、Netica 软件
软件介绍
这款软件能实现基本的一些功能(具体啥功能不能实现,我也不知道),是目前世界上应用最广泛的贝叶斯网络分析软件之一,总之,很牛逼,但是教程很少,谨慎选择。
软件使用
废话不多说,我们利用此软件搭建上面的贝叶斯网络。
1.启动软件后,点击左上角的"New Net"按钮,创建一个幕布。

2.点击节点按钮后,在幕布上点击,即可创建节点。
双击按钮,可在幕布上多次添加节点。
添加完节点后,你需要自己给网络布局。


3.因果关系
其实就是连线,将有因果关系的节点连在一起。
双击箭头按钮,连接节点。连接时注意,要从标题名字的位置为起点(也就是A,B,C,D,E字母的地方),不要从下面的状态连接,否则连不上。

4.双击节点,添加节点信息
- 节点的名字(Name)
- 节点的状态(State)
添加状态时要注意,先填写第一个状态(d0或d1)的名字,再点击"New"按钮,创建第二个状态,在填写它的名字。
最后,点击"Apply"按钮。

5.添加概率表
点击"Table"按钮,会出现左边的对话框,在蓝色框内填写概率表(每一行概率和为100%),再点击"Apply"按钮保存。

6. 网络的推断
你需要让节点和节点之间有关联,所以你需要点击菜单栏的闪电按钮。
点击之后,你会发现节点的概率发生了变化,这就是各节点的先验概率发生了变化。


到此,此节点的信息添加完毕。
我们可以用此网络去验证第七章节的推算。
参考
- https://zhuanlan.zhihu.com/p/573883337
- https://zhuanlan.zhihu.com/p/432917439
- https://zhuanlan.zhihu.com/p/364010781
- https://www.zhihu.com/question/21102128/answer/2716452544
- https://zhuanlan.zhihu.com/p/22802074
- https://zhuanlan.zhihu.com/p/101494234
- https://zhuanlan.zhihu.com/p/101722890
- http://www.ruanyifeng.com/blog/2011/08/bayesian_inference_part_one.html
- https://zhuanlan.zhihu.com/p/73415944















 8951
8951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









