






项目链接: https://github.com/davide-coccomini/
Combining-EfficientNet-and-Vision-Transformers-for-Video-Deepfake-Detection.
论文的整体架构和思路:
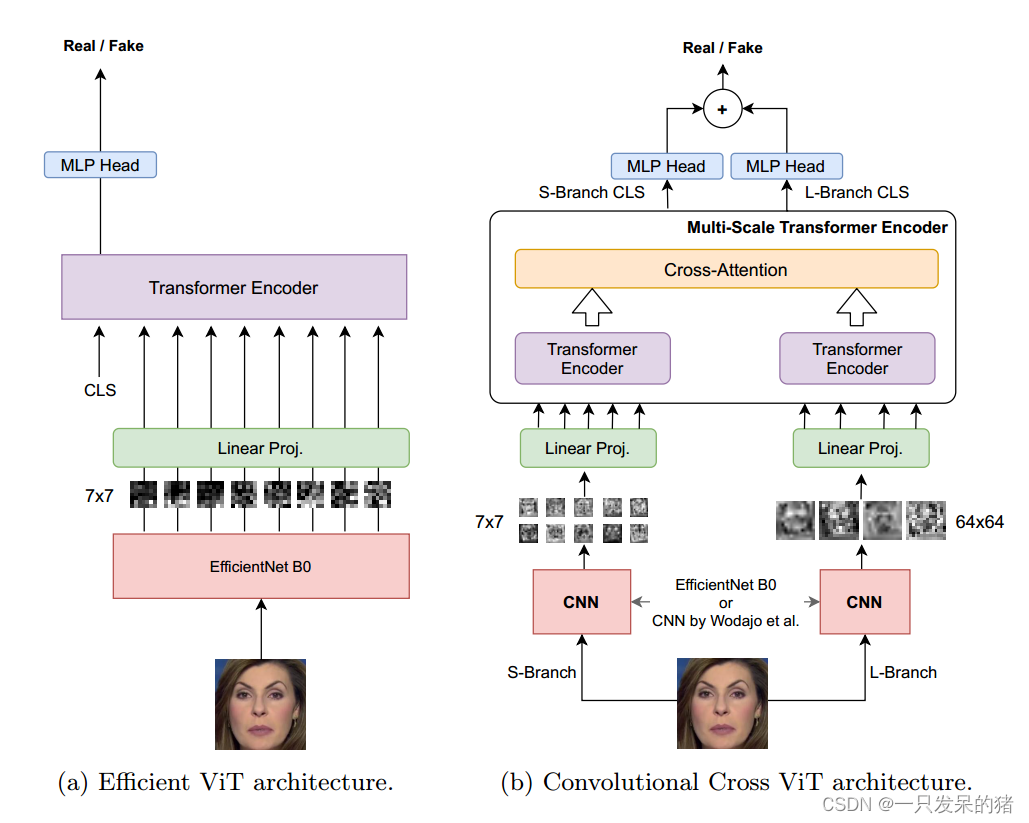
将cnn与vit相结合的思路,使用DFDC数据集进行训练和测试
作者提出了cnn与vit结合的两种思路
(a)第一种是使用预训练好的efficientnet b0进行特征提取,然后将图像切分成7*7的patch块经过线性映射,输入到vit中进行下一步处理
efficientnet为输入面部的每个块生成一个视觉特征。每个块是7 × 7像素。在线性投影之后,每个空间位置的每个特征都被视觉转换器进一步处理。添加到线性映射序列后的头部,CLS令牌用于生成二进制分类分数。
(b)将预训练好的模型提取后的特征图,分为两个分支,一个是s分支,将图像划分为7*7的patch块,另一个是L分支,将图像划分为64*64的patch块,这样做的目的是以捕获更丰富的信息和上下文。最后,使用与两个分支的输出相对应的CLS令牌生成两个独立的日志。这些对数被求和,产生最终的概率。
-------------------------------------------------------------------------------
S分支将图像划分为较小的7x7的patch块,以便对图像的局部细节进行分析。这种细粒度的划分可以帮助模型捕获图像中的细微变化、纹理和局部特征。
L分支将图像划分为较大的64x64的patch块,以便对图像的全局特征进行分析。这种粗粒度的划分可以帮助模型捕获图像的整体结构、布局和上下文信息。

与传统的直接得出分类结果不同的是,作者使用投票法得出分类结果














 1078
1078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









