






Abstract
Having access to multi-modal cues (e.g. vision and audio) empowers some cognitive tasks to be done faster compared to learning from a single modality. In this work, we propose to transfer knowledge across heterogeneous modalities, even though these data modalities may not be semantically correlated. Rather than directly aligning the representations of different modalities, we compose audio, image, and video representations across modalities to uncover richer multi-modal knowledge. Our main idea is to learn a compositional embedding that closes the cross-modal semantic gap and captures the task-relevant semantics, which facilitates pulling together representations across modalities by compositional contrastive learning. We establish a new, comprehensive multi-modal distillation benchmark on three video datasets: UCF101, ActivityNet, and VGGSound. Moreover, we demonstrate that our model significantly outperforms a variety of existing knowledge distillation methods in transferring audio-visual knowledge to improve video representation learning. Code is released here: https://github.com/yanbeic/CCL.
翻译:
与从单一模态学习相比,获得多模态线索(例如视觉和音频)可以使一些认知任务更快地完成。在这项工作中,我们建议跨异构模态转移知识,即使这些数据模态可能在语义上不相关。我们不是直接对齐不同模态的表示,而是跨模态组合音频、图像和视频表示,以发现更丰富的多模态知识。我们的主要想法是学习一种组合嵌入,它可以缩小跨模态语义差距并捕获与任务相关的语义,这有助于通过组合对比学习将跨模态的表示组合在一起。我们在三个视频数据集:UCF101、ActivityNet 和 VG GSound 上建立了一个新的、全面的多模态蒸馏基准。此外,我们证明我们的模型在传输视听知识以改进视频表示学习方面显着优于各种现有的知识蒸馏方法。
总结:
将语义不相关的跨模态信息通过对比学习组合起来
Introduction
我们的目标是提炼在空间图像数据和时间听觉数据上预先训练的网络中可用的丰富的多模态知识,以学习更具表现力的视频表示。
尽管之前的工作已经考虑了跨模态蒸馏 [24,6,3,34,2],但它们通常假设两个模态之间存在成对语义对应关系。然而,在不受约束的场景中,跨模式内容可能并不总是语义相关或时间对齐,例如涂口红的视频,可能伴有与动作不直接相关的音频,例如音乐或语音。另一方面,类似的音频提示(例如音乐)可以伴随显示不同视觉内容(例如涂口红和演奏大提琴)的视频。
在这项工作中,我们解决了一种现实的多模式蒸馏范例,可以蒸馏异构音频和视觉知识以进行视频表示学习。这需要弥合跨模态语义差距、领域差距,以及处理跨模态不一致的网络架构。为了以统一的形式应对这些挑战,我们提出了组合对比学习——一种新颖的通用框架,通过灵活地插入在不同数据模态上预先训练的教师网络来提炼多模态知识。具体来说,学习组合嵌入来缩小教师和学生网络之间的跨模态差距并捕获与任务相关的语义。通过组合对比学习,将教师、学生及其组合嵌入联合起来,将多模态知识转移到视频学生网络中,以学习更强大的视频表示。
我们的贡献如下。 (1)我们提出了一种新颖的组合对比学习(CCL)模型,其特点是可学习的组合嵌入,可以缩小跨模态语义差距,以及在共享潜在空间中联合对比不同模态的蒸馏目标,其中引入类标签以信息丰富的方式提炼多模态知识。 (2) 我们建立了多模态蒸馏的新基准,在视频识别和视频检索这两个任务中,在三个视频数据集:UCF101、ActivityNet、VGGSound 上将 CCL 与七种最先进的蒸馏方法进行了广泛比较。 (3) 与之前最先进的方法相比,我们展示了我们的模型的优势,并提供了富有洞察力的定量和定性消融分析。
Related Work
Audio-Visual Learning. Audio has been used to assist visual learning or vice versa, e.g. to separate or localise sound in videos [40, 56, 5, 21], for audio recovery [70], lip reading [2], speech recognition [1], or audio-driven image synthesis [67, 31]. Several self-supervised methods have recently been explored for audio-visual learning [41, 42, 4, 47]. By training the audio and video networks jointly, these works leverage the semantic correspondence between audio and video for unsupervised learning on a large video dataset. To further scale audio-visual learning to unconstrained audiovideo data with possible semantic mismatch, we propose to distill the audio-visual knowledge from pre-trained teacher networks to regularise the student network.
翻译:
音频-视觉学习。音频已被用于辅助视觉学习,反之亦然,例如在视频中分离或定位声音[40,56,5,21],用于音频恢复[70],唇读[2],语音识别[1]或音频驱动的图像合成[67,31]。最近,已经探索了多种用于音频-视觉学习的自监督方法[41,42,4,47]。通过共同训练音频和视频网络,这些研究利用音频和视频之间的语义对应关系在大型视频数据集上进行无监督学习。为了将音频-视觉学习扩展到具有可能的语义不匹配的非限制性音频视频数据,我们建议从预训练的教师网络中提炼音频-视觉知识,以规范学生网络。
Compositional Contrastive Learning (CCL)
Compositional Multi-Modal Representations
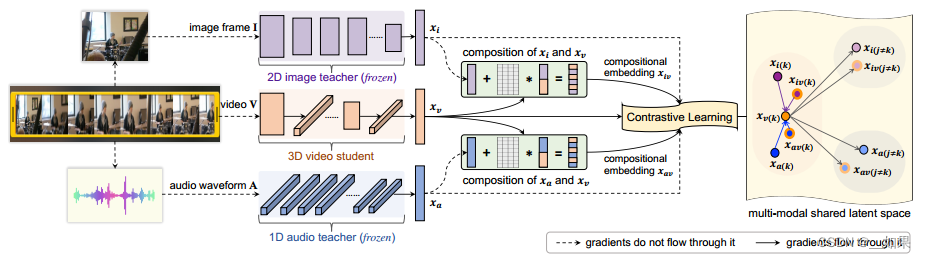
音频的时间上下文提供了丰富的语义信息,用预训练的1D-CNN获得音频嵌入
对每个视频片段只随机选择一个图像帧表示视觉内容,用2D-ResNet获得图像嵌入
视频网络包含一堆(2+1)D卷积的残差块,在二维空间卷积和一维时间卷积之间交替,对时空视觉内容进行编码,由3D-CNN参数化
Compositional Multi-Modal Representations
学生和教师嵌入可能在语义上不对齐——图像帧可能只捕获与视频事件没有直接关系的部分视觉线索,而动作视频的伴随音频可能是无关的音乐或语音
由于网络结构在不同模态上是不均匀的,因此在倒数第二层推导出跨模态组成
教师嵌入xa、xi与学生嵌入xv通过在教师嵌入上学习残差组成:
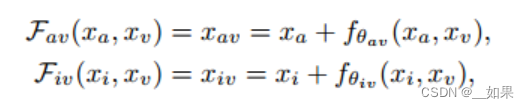
F为组合函数,f为学习残差,f通过规范化、拼接和一个线性投影来融合两个模态
我们的目标是用可学习残差转移教师嵌入
组合嵌入被强制与xv共享相同的类标签k,以保证语义的融合
分类损失函数:
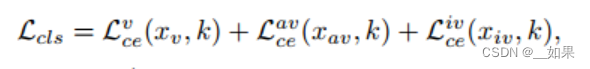
Distilling Audio-Visual Knowledge
在潜在特征空间中进行对比学习,然后在预测空间中对比类分布
正样本对可以包括来自同一视频类k的图像、音频和视频
对于从视频Vi中提取的音频、视频及其组合嵌入的三元组,可以在它们之间的每对中形成对比损失,例如一对音频和视频嵌入之间的对比损失Lct:
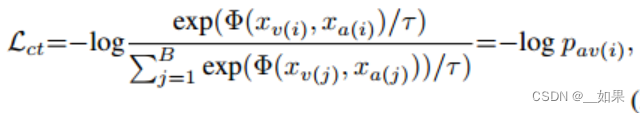
其中Φ是余弦相似度评分函数,τ是温度,pav(i)是将视频嵌入xv(i)分配给配对的音频嵌入xa(i)的概率
但每批可能存在从相同视频类k中采样的多个正视频音频对,因此上式会导致忽略类水平的区分,盲目地将一些阳性视为假阴性
用NCELoss改写一下:
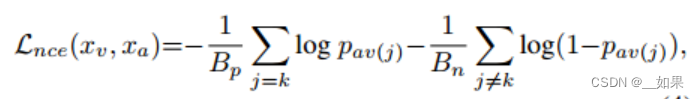
还可以在单模态嵌入和组合嵌入之间做NCELoss:
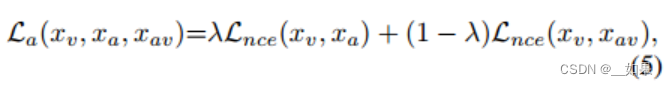
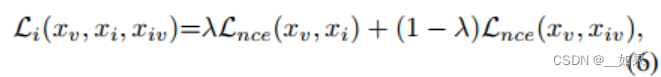
由于组合嵌入受到视频分类器的约束,因此还可以施加相似性约束以进一步对齐预测空间中的类分布,用JSD:
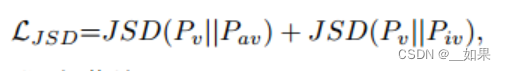
Learning Objective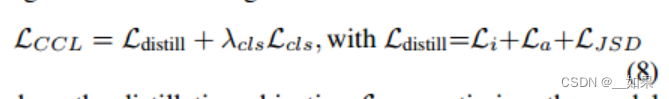
Experiments
与FitNet相比,对于音频与视频中的事件关联度不强时,FitNet的效果远不如CCL,因为它太hard了,教师强制影响了学生
Discussion and Conclusion
We present a novel compositional contrastive learning (CCL) framework, a generic and effective approach to distill knowledge learned from heterogeneous data modalities for video representation learning. As there may exist a cross-modal semantic gap, we introduce the learnable compositional embeddings to close the gap and capture the taskrelated semantics. Our approach uniquely brings the unimodal knowledge (from teacher networks) and multi-modal knowledge (from composition functions) collectively to facilitate effective knowledge distillation. We compare our approach to a variety of state-of-the-art distillation methods, and demonstrate its performance advantages for both video recognition and video retrieval in different setups. Our empirical results also provide a realistic benchmark for future research in multi-modal distillation. As a future extension, our approach also opens up the possibility to bridge multiple modalities for multi-modal recognition and retrieval tasks.
我们提出了一种新颖的组合对比学习(CCL)框架,这是一种通用且有效的方法,可以从异构数据模态中提取知识以进行视频表示学习。由于可能存在跨模态语义差距,我们引入可学习的组合嵌入来缩小差距并捕获任务相关的语义。我们的方法独特地将单模态知识(来自教师网络)和多模态知识(来自组合函数)结合在一起,以促进有效的知识蒸馏。我们将我们的方法与各种最先进的蒸馏方法进行比较,并展示其在不同设置下的视频识别和视频检索的性能优势。我们的实验结果也为多模式蒸馏的未来研究提供了现实的基准。作为未来的扩展,我们的方法还为跨模式识别和检索任务的多种模式提供了可能性。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









