







* Combining EfficientNet and Vision Transformers for Video Deepfake Detection
题目:结合高效网络和视觉变压器进行视频深度虚假检测(结合)
作者:Davide Coccomini, Nicola Messina, Claudio Gennaro, and Fabrizio Falchi
ISTI-CNR, via G. Moruzzi 1, 56124, Pisa, Italy(意大利国家研究委员会)
发表期刊:ICIAP(图像分析和处理国际会议)
1.概要
将各种类型的视觉变换器与卷积EfficientNet B0相结合,提取人脸特征。
不使用蒸馏法,也不使用集成法。而是一种基于简单投票的方案,用于处理同一视频镜头中的多个不同人脸。
主要创新:在视频的时空上判断各个人脸
2.总方法
-
网络输入:提取的人脸。
-
网络输出:人脸被操纵的概率。
用人脸检测器MTCNN对人脸进行预提取;
再用 the Efficient ViT and the Convolutional Cross ViT两个网络训练。
3.Efficient ViT
-
两个模块组成:卷积模块(
EfficientNet B0特征提取)+a Transformer Encoder。 -
具体步骤:
1.用
EfficientNet B0为人脸每个块生成一个视觉特征。(一个块为7*7像素);2.每个特征都由视觉变换器(
Linear Proj)进一步处理;3.用CLS生成二分类的分数;
4.Transformer encoder编码器,把特征编码为机器容易学习的向量;
5.MLP Head将图片分为real/fake。
-

-
缺陷:只能用小补丁。而伪影可能在全局出现。
4.Convolutional Cross ViT
-
两分支组成:
the Efficient ViT and the multi-scale Transformer architecture即 S分支处理较小的斑块,L分支处理较大的斑块,以获得更宽的感受野。
-
使用两个不同的CNN主干作为特征提取器。
(只使用其一)
1.EfficientNet B0,它为S分支处理7×7图像补丁,为L分支处理54×54图像补丁。
2.Wodajo等人的CNN,它为S分支处理7×7图像补丁,为L分支处理64×64图像补丁。
-
Linear Proj:视觉变换器处理特征。 -
Transformer Encoder:解码器解码。
-
Cross-Attention:两条分支交互,生成独立的S-CLS,L-CLS。
-
MLP Head:分类图片。
-

5.推论
-
优化器:使用 SGD optimizer with a learning rate of 0.01进行端到端训练。
-
真假阀值设置:0.55.
-
投票机制:针对同一个视频里有多个不同人脸的视频。
根据人脸特征分类人脸,并平均得分,判断是否是假脸。
一个视频里有一张假脸就判定该视频是假的。
-

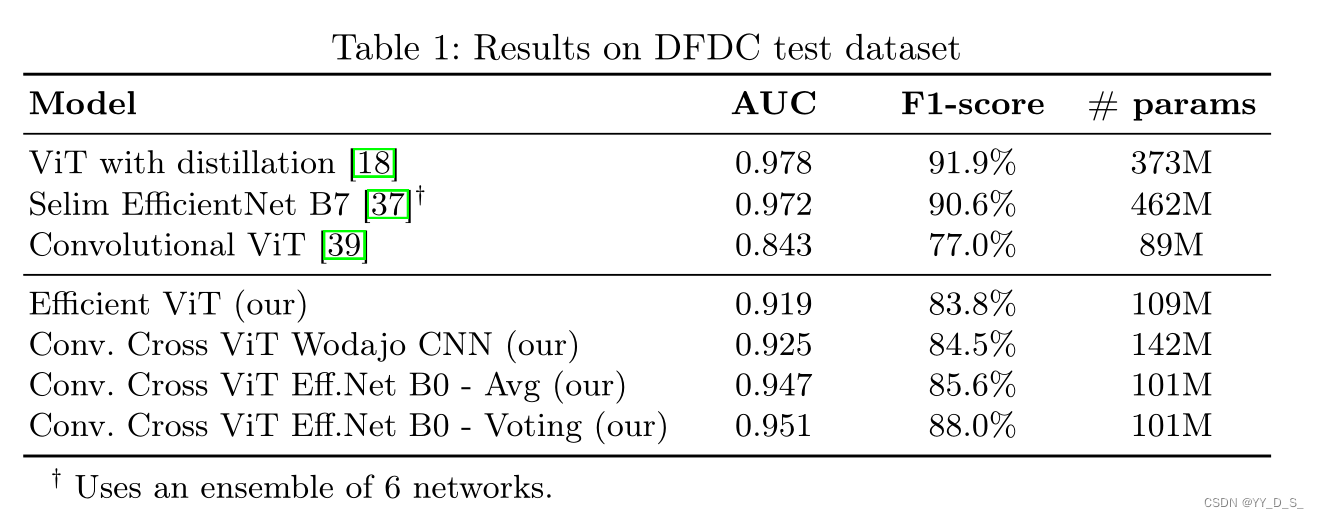
6.结论
-
性能指标:AUC(准确率)+F1-score(伪造人脸的平均分数)
-
数据集:
FaceForensics++,DFDC















 4533
4533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









