







人脸识别技术原理:人脸识别的五大技术流程,包括人脸图像的采集与预处理、人脸检测、人脸特征提取、人脸识别和活体鉴别;目前人脸识别的主要方法,包括基于特征脸的方法、基于几何特征的方法、基于深度学习的方法、基于支持向量机的方法和其他综合方法。

1. 人脸图像采集
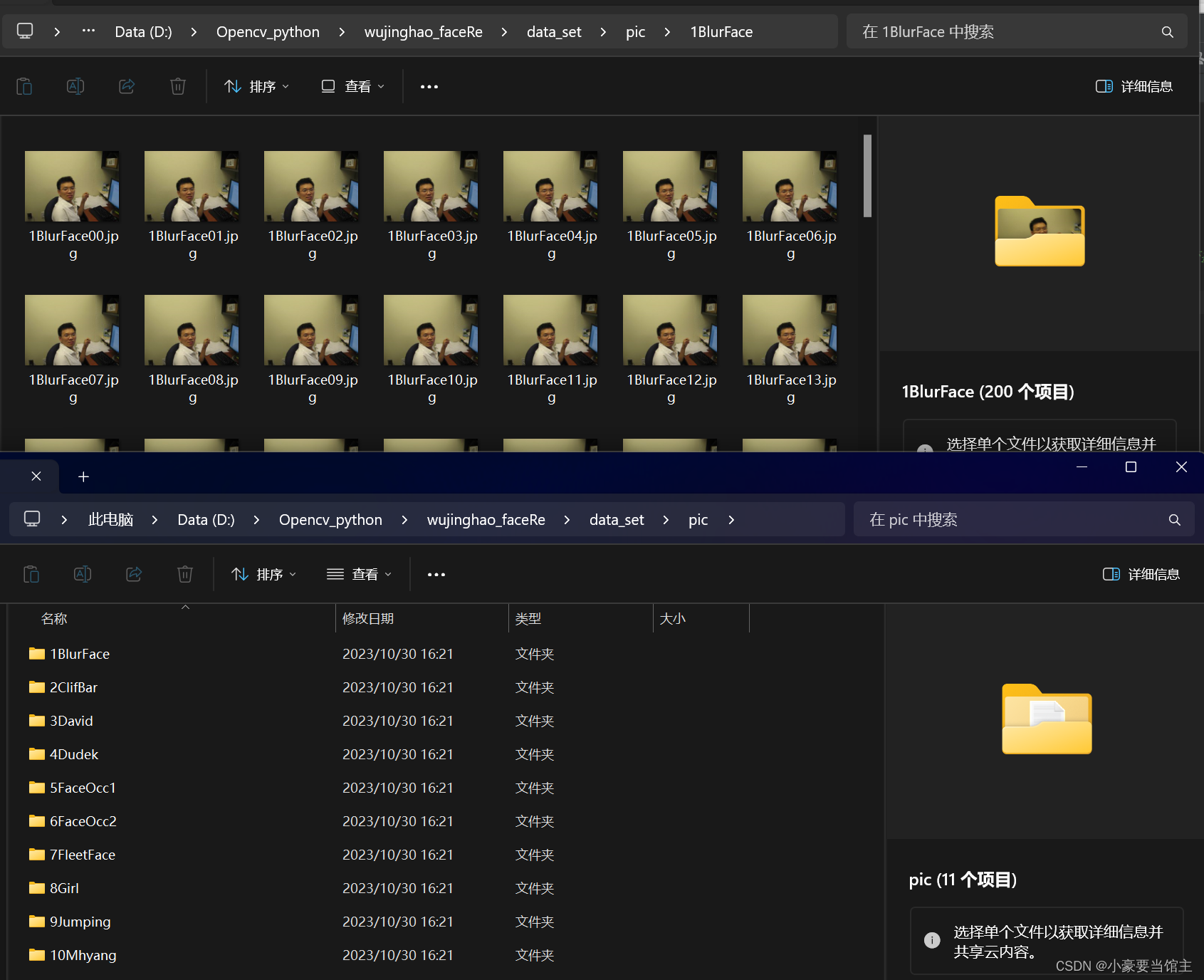
1.1 数据集准备
首先为训练神经网络准备数据集,这里是使用了课件给出的10个人脸图像train文件夹,每个文件夹大概都有200张训练集左右,如下图:
1.2 数据增强
200张左右的数据集还是比较单薄,训练出来的模型可能不会太准确,所以我在这里采用了多种数据增强,大概有亮度对比度调整、增加噪声、随机变形、随机变换颜色等方法。具体实现:augmented_pic.py代码
具体方法如下:
镜像翻转 (horizontal_flip 方法):
这个方法接受一张图像作为输入,然后使用OpenCV的 cv2.flip 函数对图像进行水平翻转,创建图像的镜像版本。
随机裁剪 (random_crop 方法):
这个方法接受一张图像和裁剪尺寸作为输入,然后根据裁剪尺寸在图像中随机选择一个矩形区域进行裁剪。如果图像尺寸小于裁剪尺寸,不进行裁剪。
随机旋转 (random_rotate 方法):
这个方法接受一张图像和最大旋转角度作为输入,然后随机选择一个角度在指定范围内进行旋转,使用 cv2.getRotationMatrix2D 和 cv2.warpAffine 函数来实现旋转操作。
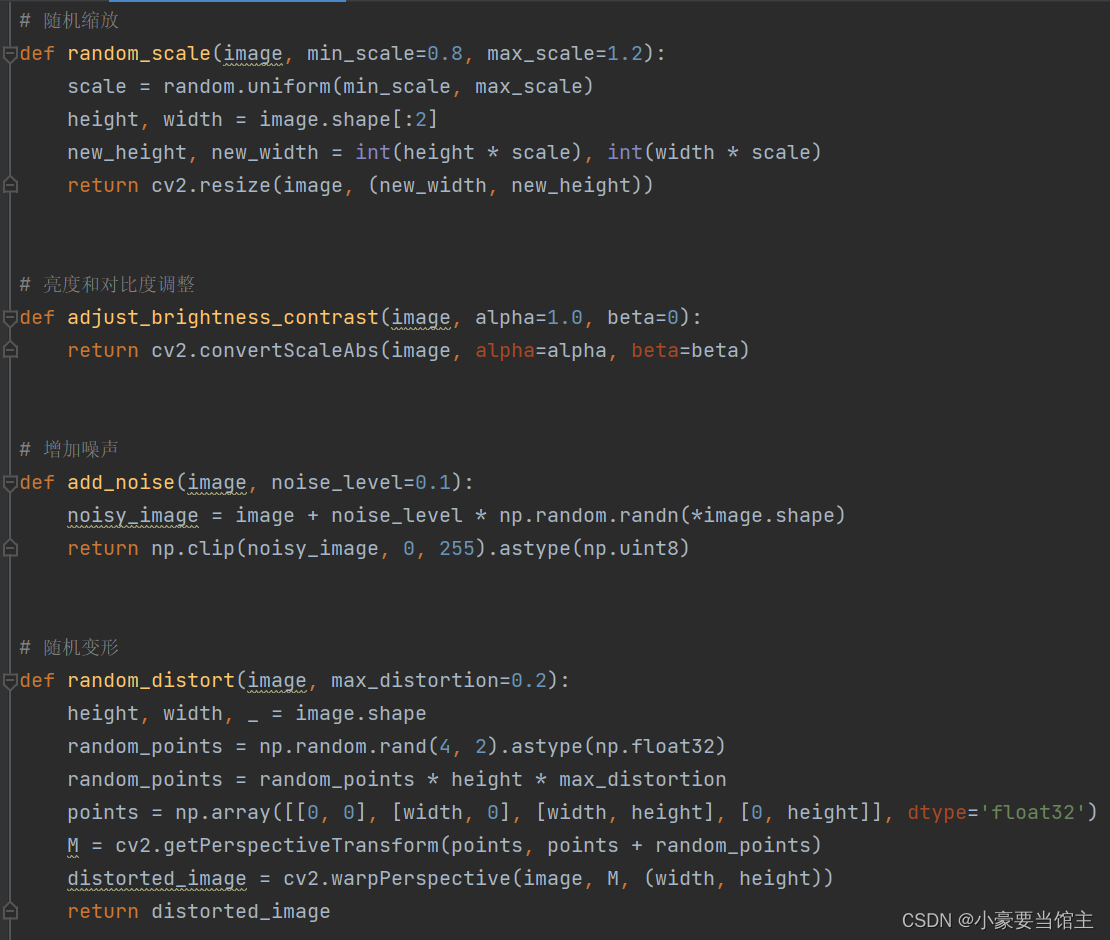
亮度和对比度调整 (adjust_brightness_contrast 方法):
这个方法接受一张图像以及亮度和对比度参数作为输入,使用 cv2.convertScaleAbs 函数来对图像的亮度和对比度进行调整。
随机变换颜色 (random_color_change 方法):
这个方法接受一张图像和最大颜色变化值作为输入,然后分离图像的颜色通道(蓝色、绿色、红色),然后随机选择每个通道的颜色变化值,并使用 np.clip 函数来限制颜色通道的像素值在0到255之间,最后合并通道生成一个新的彩色图像。
这里给出部分代码:
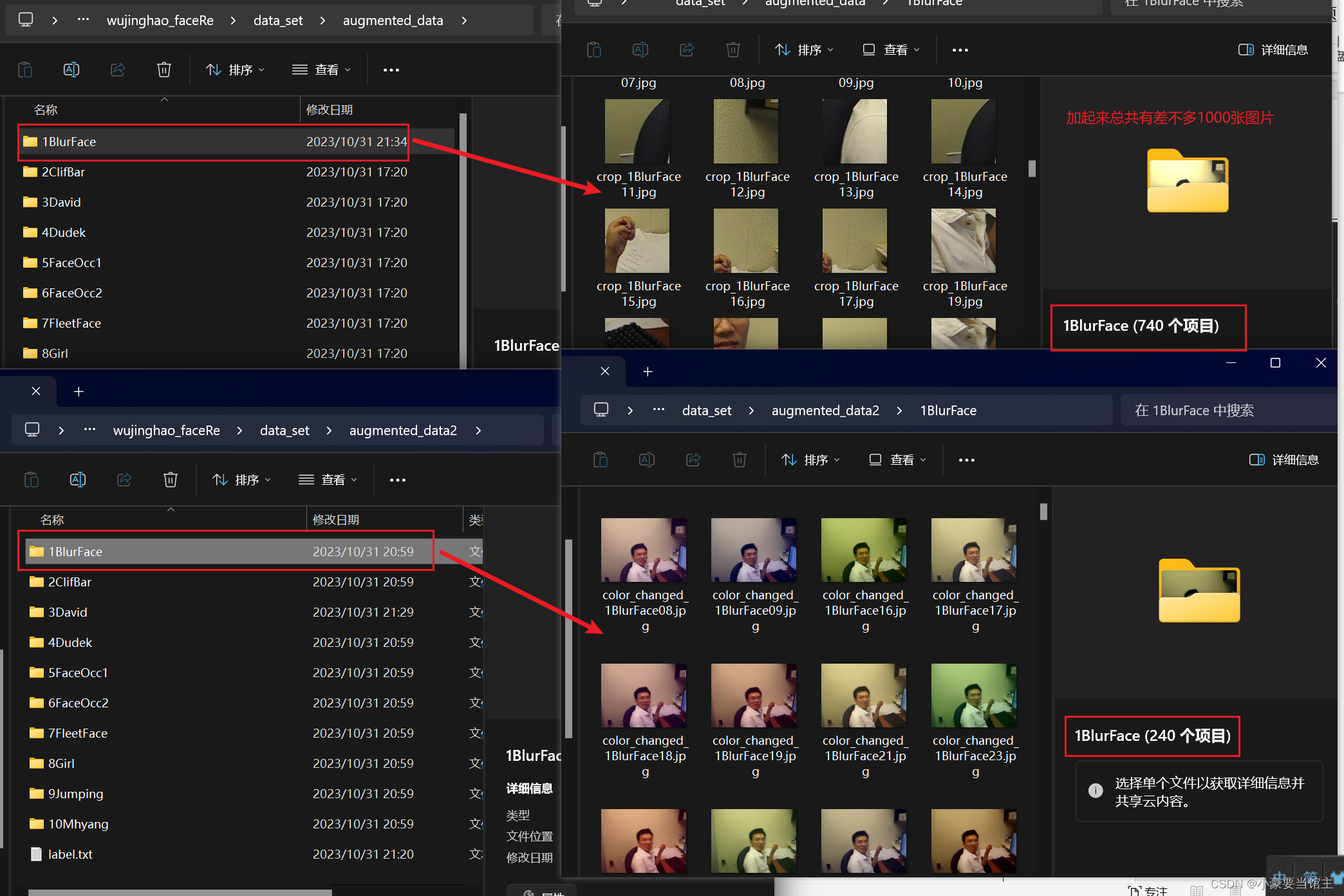
然后输出的数据增强图片放在augmented_data和augmented_data2文件夹下,平均每个人脸创造出1000张数据增强图片,用来准备训练模型,效果如下:
2. 图像预处理
2.1 人脸对齐
进行模型训练之前非常重要的一步,就是对图像进行人脸对齐,有助于减小图像中的变化,使人脸更容易被识别,提高了模型的鲁棒性。
主要有以下任务:
调整角度:校正人脸的旋转角度,使人脸保持水平。
调整位置:将人脸移动到图像中的特定位置,通常是中心位置。
调整尺寸:调整人脸的尺寸,以使其具有一致的尺寸,适应模型的输入要求。
保持比例:保持人脸的比例,以避免拉伸或压缩。
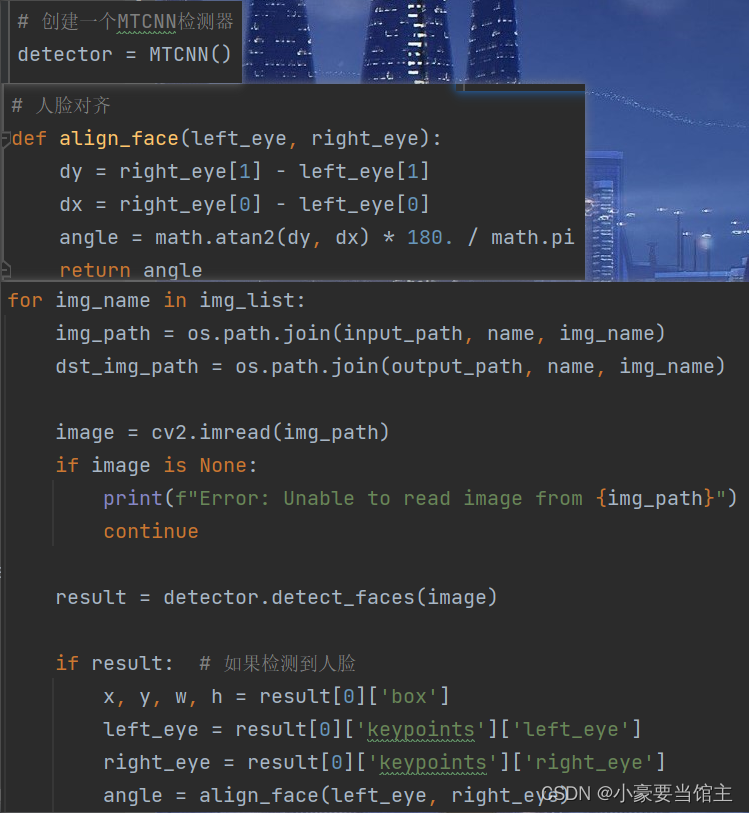
这里我主要使用了MTCNN进行人脸和特征点的检测,然后再进行人脸对齐,主要代码如下:
2.2 图像裁剪
对感兴趣区域进行裁剪。图像裁剪有助于减小输入数据的维度,减少模型的计算复杂性,加快训练速度。裁剪可以提高模型的鲁棒性,减少不相关信息的干扰。对于特定任务,如对象检测或分类,确保输入图像尺寸一致有助于模型的稳定性和性能。具体代码如下:
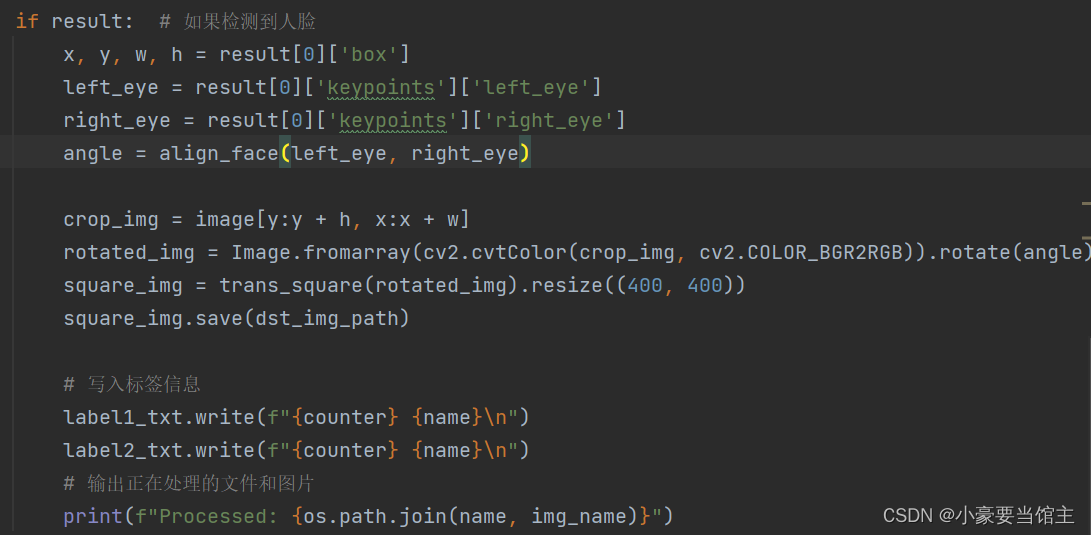
2.3 数据集加载和输出路径
然后是加载数据增强的图像路径和本来的图像路径
输出的图像效果如下:
大概每个人脸序列能有800张识别和裁剪好的图片,这些接下来就是用来进行训练模型
3. 数据标签和图片路径的处理
3.1 数据集
加载数据集:代码从指定路径 dataset_path 中加载图像数据集,该数据集包含了不同人的脸部图像。这些图像将用于训练模型。
![]()
3.2 调整图像大小
通过 resize_image 函数,将加载的图像调整为指定的大小(IMAGE_SIZE),通常是400x400像素。这是为了确保所有图像具有相同的尺寸,以便进行模型训练。

3.3 标注数据
为每个加载的图像分配标签,标签通常表示图像所属的类别或人物。不同人物的图像可以分为不同的类别,标签通过数字表示(0, 1, 2, ...)。在代码中,不同人物的图像被分为10个类别。代码如下:
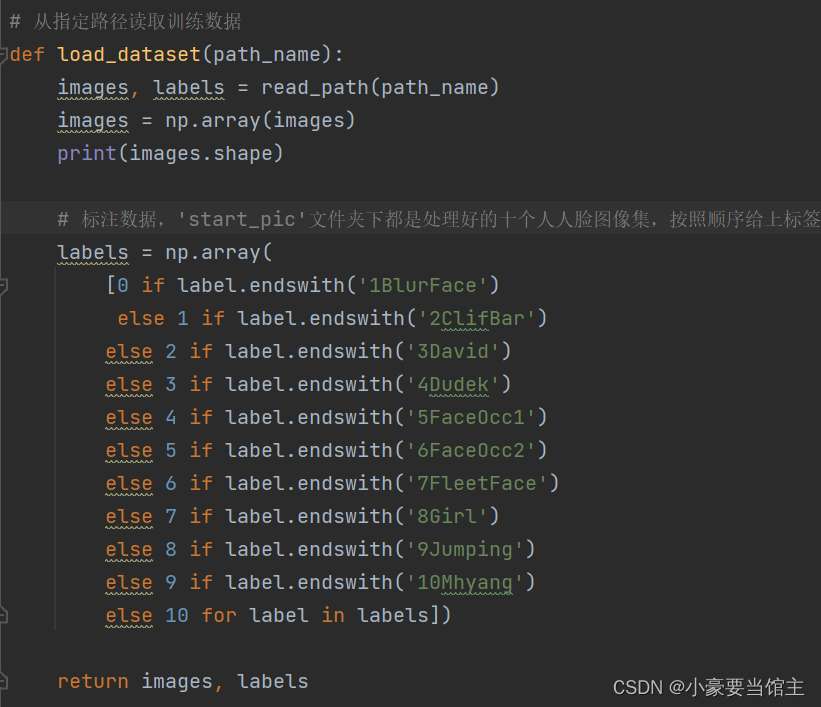
3.4 检查标签和图像
代码中的 check_labels_and_images 函数用于检查加载的图像和它们的标签是否正确匹配。它逐个加载图像,并在终端显示图像的实际标签和形状。这可以用来验证数据集的准确性和一致性。
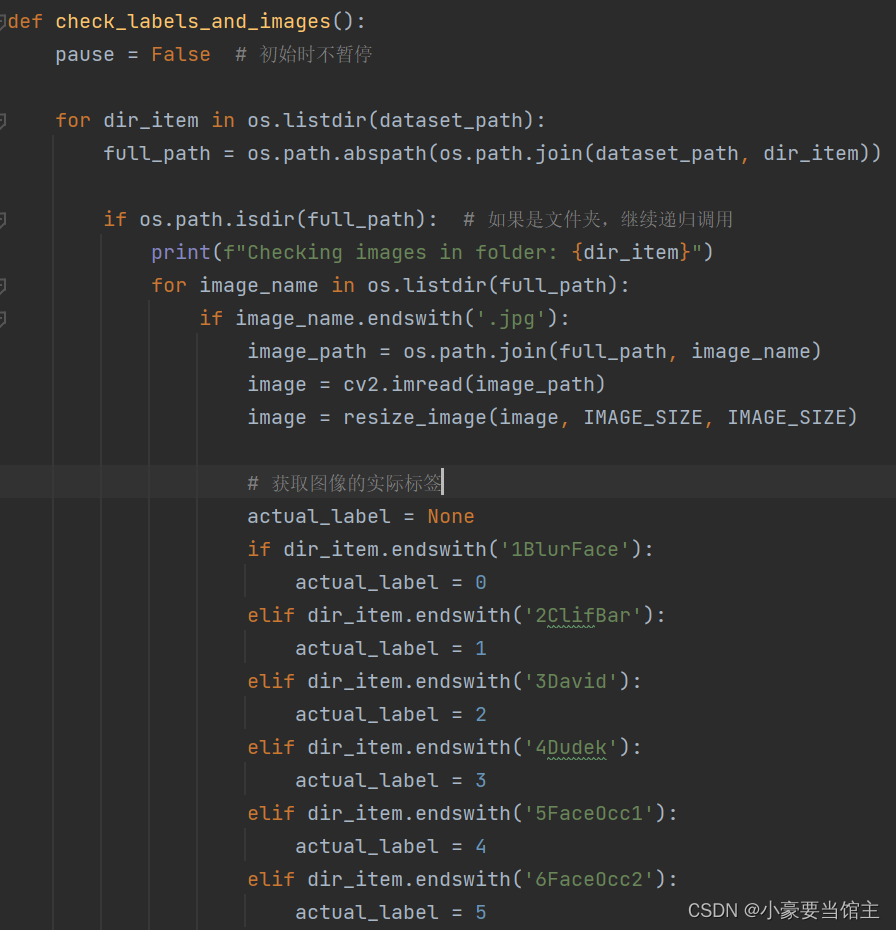
可以通过输出的信息和显示图像检查图像有没有正确加载,效果如下: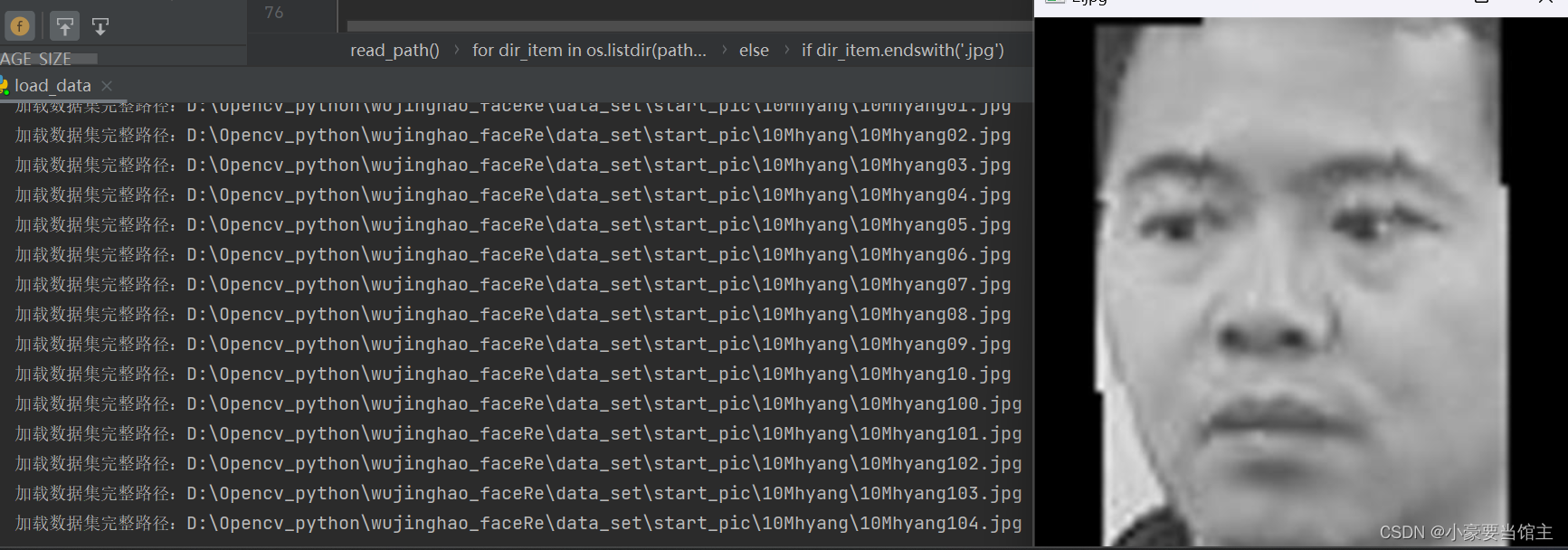
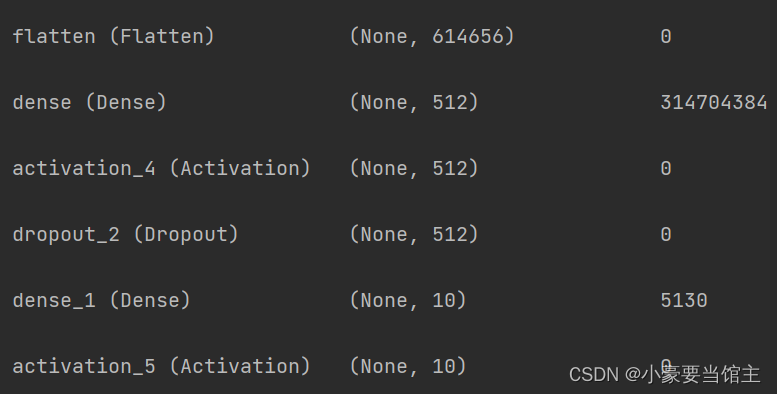
4. 人脸识别模型构建和训练(CNN)
4.1 CNN神经网络
CNN 是一种特殊类型的神经网络,专用于处理图像数据。CNN 主要包括卷积层、池化层和全连接层。它在图像处理任务中非常有效,因为它能够自动学习和提取图像中的特征。

4.2 人脸识别方面最常用的度量学习方法
是三元组损失函数 ,最早在被用于人脸识别任务。三元组损失的目标是以一定余量分开正例对之间的距离和负例对之间的距离。从数学形式上讲,对于每个三元组 i,需要满足以下条件:
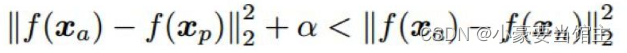
【其中 x_a 是锚图像,x_p 是同一主体的图像,x_n 是另一个不同主体的图像,f 是模型学习到的映射关系,α 施加在正例对和负例对距离之间的余量。在实践中,使用三元组损失训练的 CNN 的收敛速度比使用 softmax 的慢,这是因为需要大量三元组(或对比损失中的配对)才能覆盖整个训练集】
4.3 模型使用
我的模型构建主要原理涉及神经网络和卷积网络神经网络,其中使用Keras库构建卷积神经网络(CNN)模型,主要通过学习权重和偏差来建立输入和输出之间的复杂关系。

该模型包括:
卷积层: CNN 的核心部分。它使用卷积核(也称为滤波器)来滑动在输入图像上,提取局部特征。卷积操作可以捕捉到图像中的边缘、纹理等低级特征。
激活函数:引入非线性性质,使神经网络能够学习更复杂的函数关系。在这段代码中,使用了 ReLU(Rectified Linear Unit)作为激活函数。
池化层:用于降低图像尺寸,减少计算复杂性,并提取图像中的主要特征。最大池化是常见的池化操作,它选择每个区域中的最大值作为输出。
丢弃层和全连接层:用于将卷积层提取的特征图展平成一维向量,然后通过一系列全连接层进行分类或回归。具体代码如下:
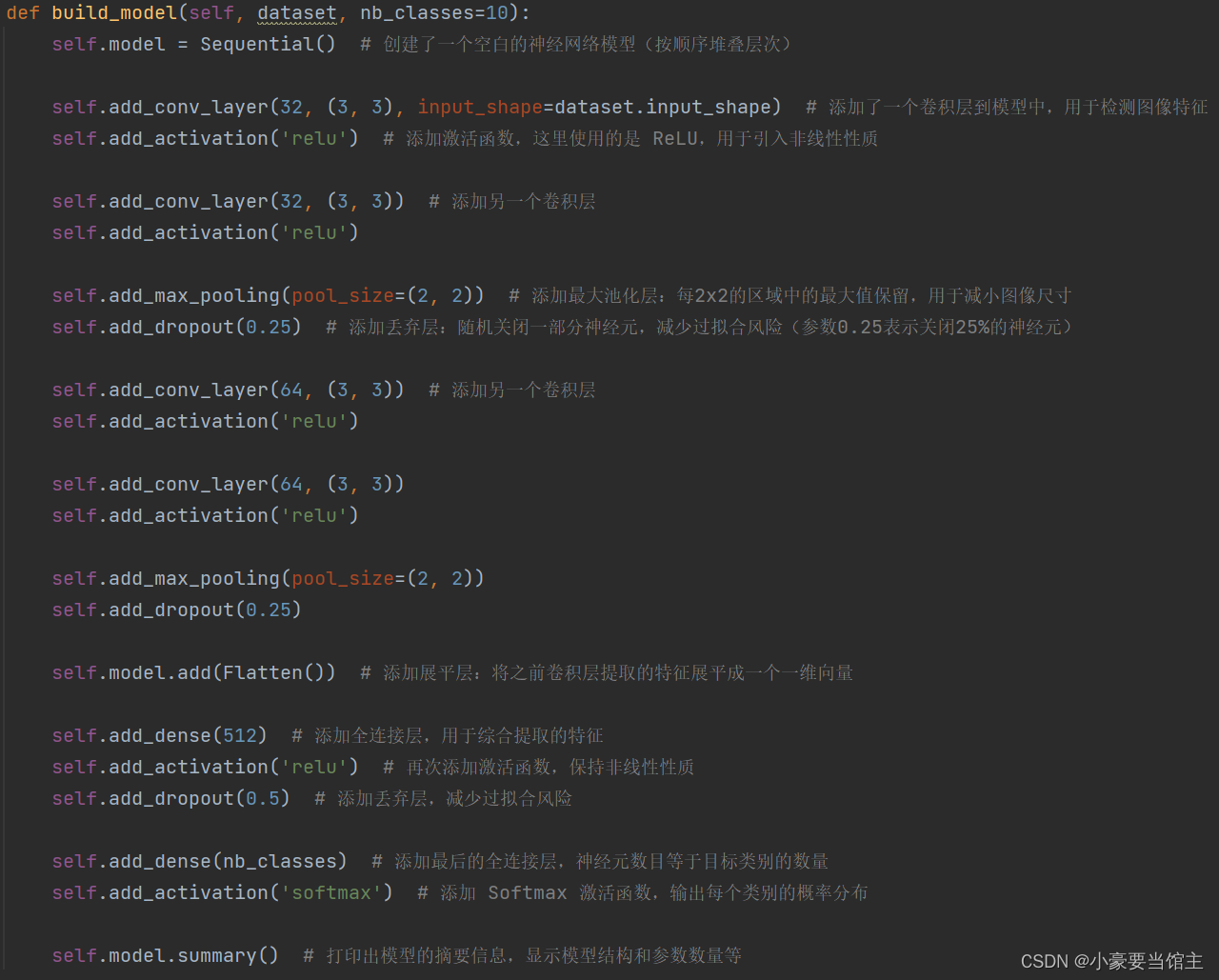
下面的函数用于构建深度学习模型的不同类型层次,它们被定义在Model类中,并用于添加相应类型的层到模型中,具体代码如下:
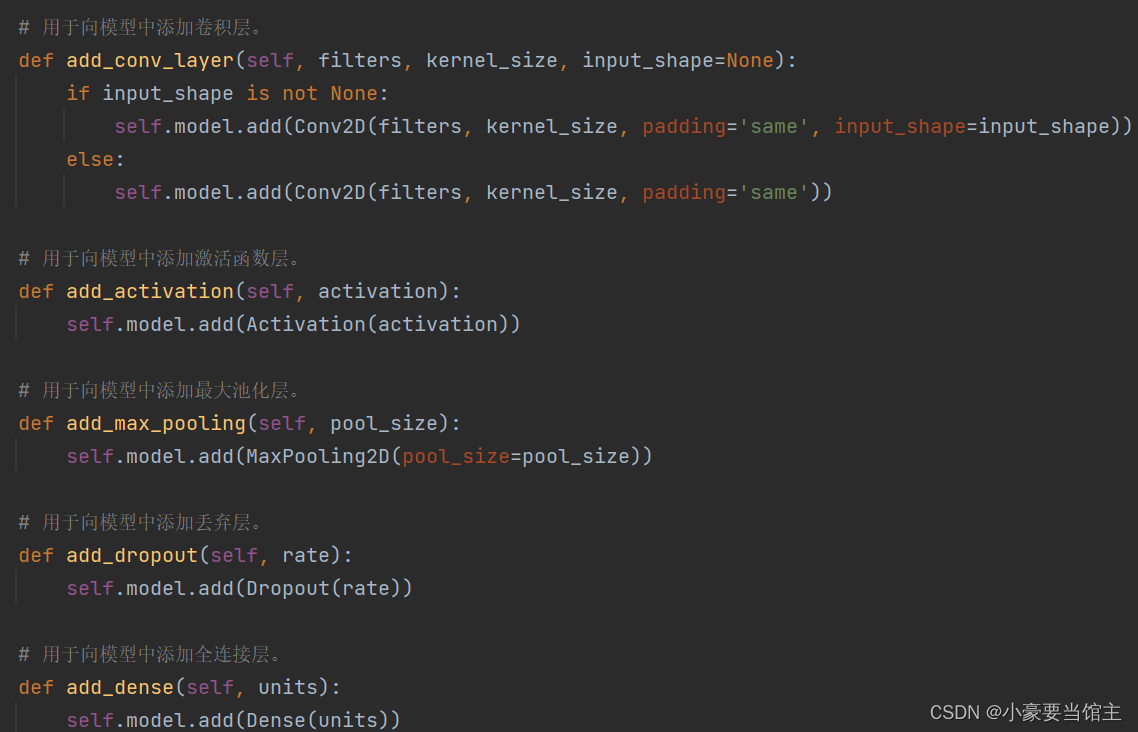
4.4 主要训练过程:
创建随机梯度下降(Stochastic Gradient Descent,SGD)优化器:
通过SGD类创建一个SGD优化器,指定学习率、学习率衰减、动量和Nesterov动量的参数。
编译模型:
使用self.model.compile方法编译模型,指定损失函数(categorical cross-entropy)、优化器(SGD)和评估指标(准确度)。
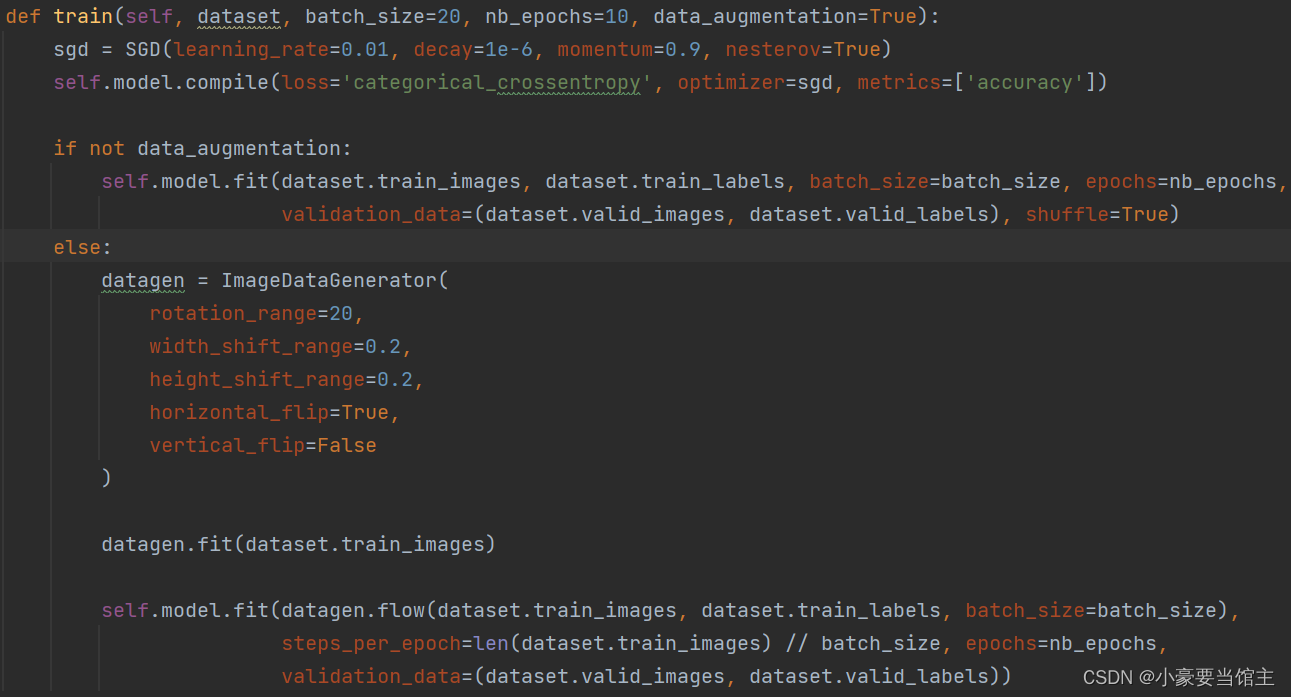
训练模型:
如果data_augmentation为False,模型将使用原始的训练数据进行训练。使用self.model.fit方法,传递训练图像(dataset.train_images)、训练标签(dataset.train_labels)、批次大小、迭代次数、验证数据(dataset.valid_images和dataset.valid_labels)以及shuffle=True表示在每轮训练前随机打乱数据。
如果data_augmentation为True,模型将使用数据增强技术进行训练。创建一个ImageDataGenerator对象(datagen),用于对训练数据进行数据增强,包括旋转、平移和水平翻转等操作。
调用datagen.fit(dataset.train_images)以适应训练数据的统计信息。
使用self.model.fit方法,传递通过datagen.flow生成的数据流(包括增强后的图像和对应的标签),以及steps_per_epoch参数,该参数表示每个迭代(轮)的步数,通常为总训练样本数除以批次大小。
具体代码如下:
4.5 数据预处理
首先加载具体的数据集路径,十个人的数据集加起来总共差不多8675张,平均每个人800张左右进行训练

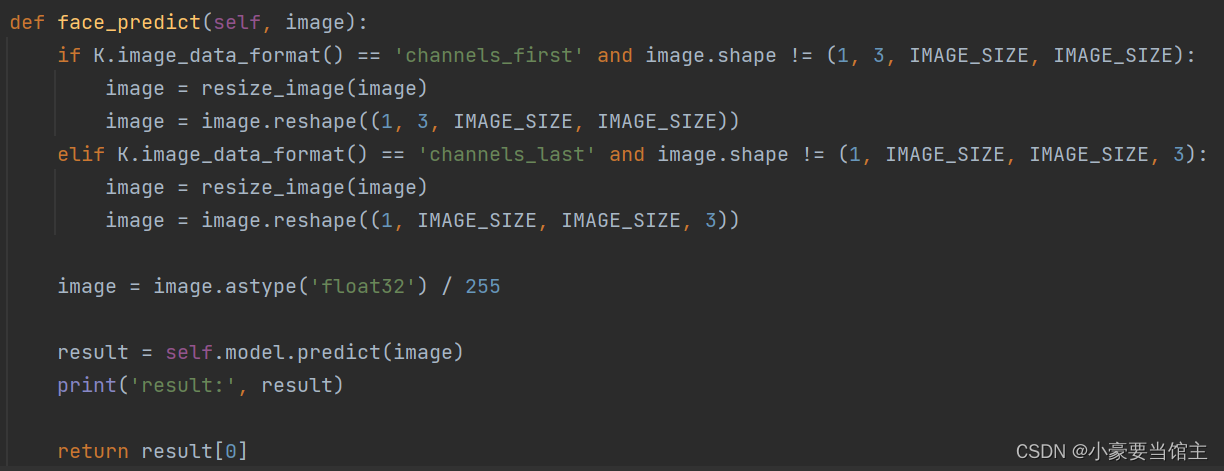
4.5.1 神经网络预测函数
主要实现根据图像数据的格式('channels_first'或'channels_last')来检查图像的形状,并根据需要调整大小和重塑。将图像的像素值转换为浮点数并进行归一化(范围缩放到 [0, 1])具体代码如下:
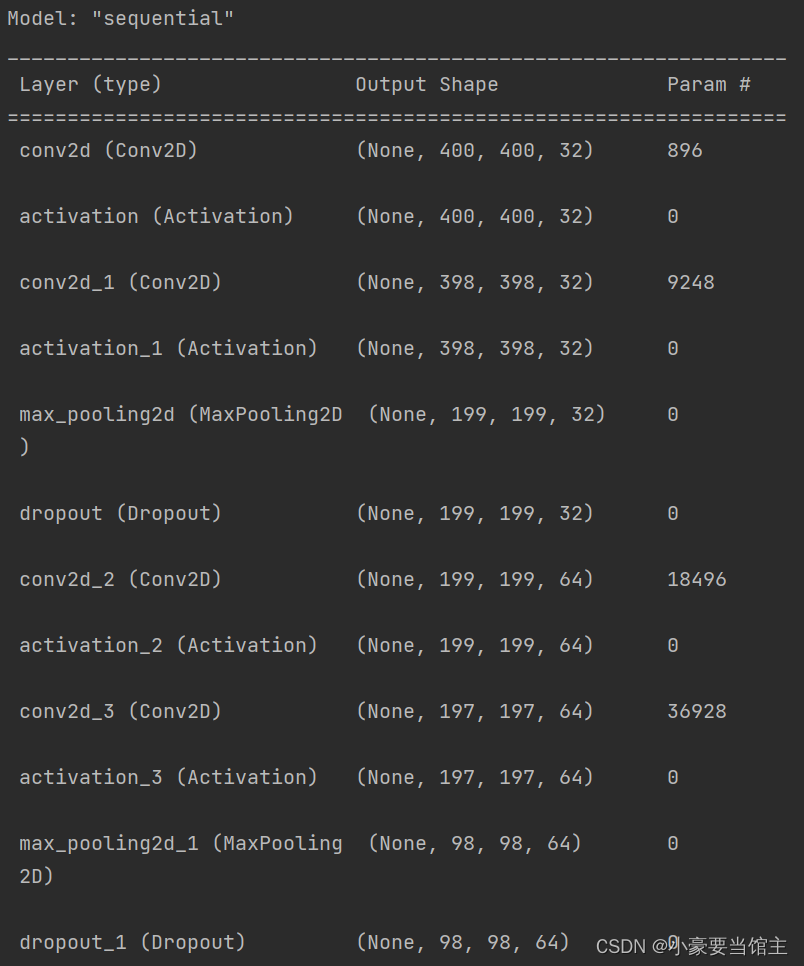
这里的具体输出参数如下:
因为使用了TensorFlow,最终经过深度学习模型训练生成一个h5模型文件,如下图:
5. 人脸识别
5.1 MTCNN人脸检测
这里我使用了MTCNN检测器检测输入图像帧中的人脸,对于每个检测到的人脸,提取其位置和尺寸,并裁剪出人脸图像,然后使用预训练的人脸识别模型对裁剪出的人脸进行识别,得出每个类别的概率。确定最可能的人脸属于哪个类别,并计算其置信度(识别率),再根据load_data的标签处理,如果置信度大于等于50%,则在图像上绘制绿色矩形框,显示预测的标签和置信度。具体代码实现:
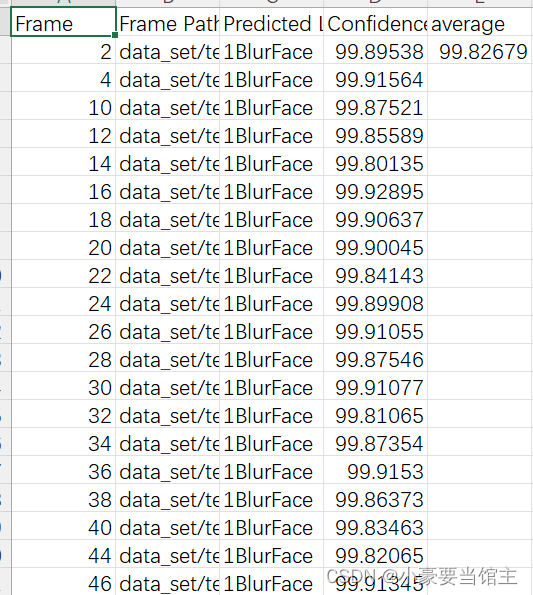
5.2 逐帧分析
然后每个类别对应的每一帧和识别率输出在一个csv文件上,后面作为一个数据分析和对比,如下图:
5.3 命令行加载数据集
相关的人脸识别过程,这里使用了argparse库的命令行参数去读取测试数据集的路径,然后进行识别。这里初始化了模型加载路径和对应标签列表,具体代码如下:
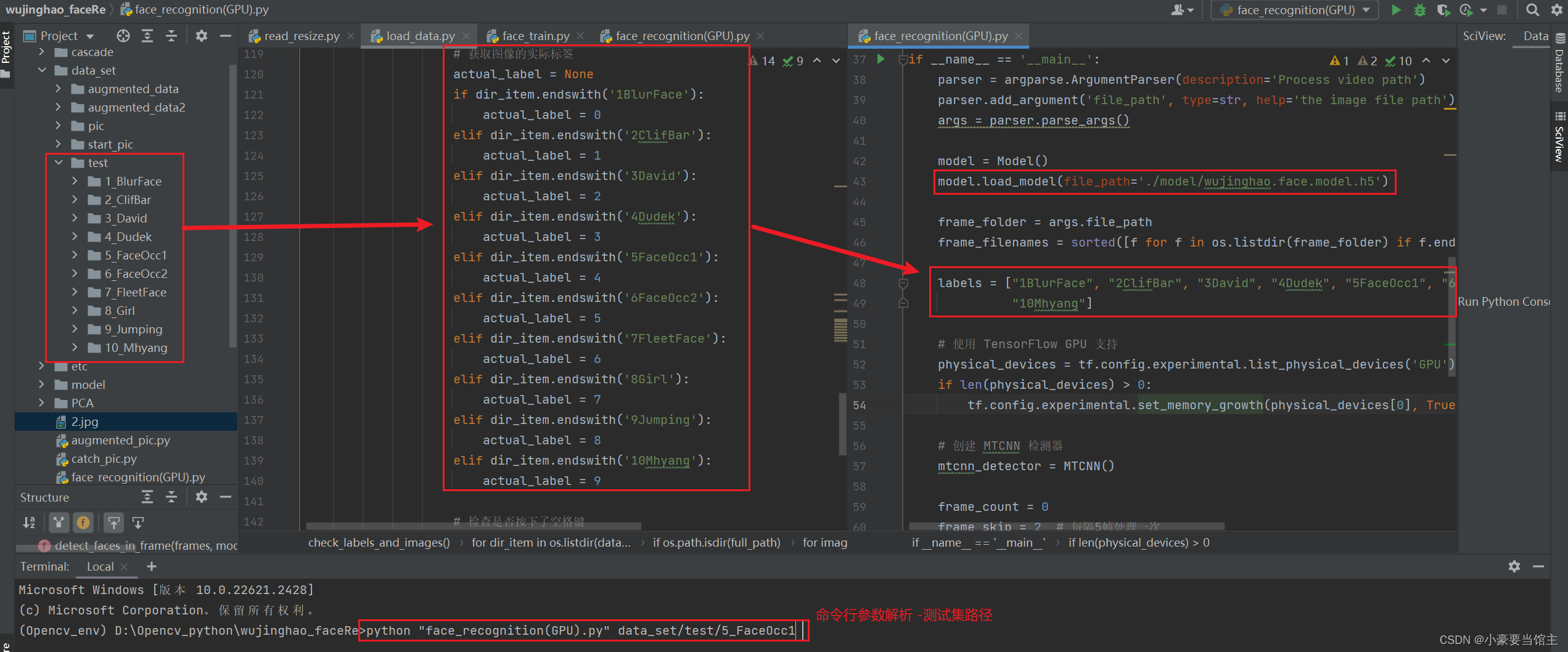
5.4 人脸识别实现效果
这个人脸识别分类主要是使用了MTCNN检测器,效果精度很不错,因为此前图像处理和人脸检测的时候同样是使用了MTCNN。这是一种用于人脸检测的神经网络架构。它是一种级联的多任务学习网络,由三个级联的子网络组成,分别是:
P-Net(Proposal Network):负责生成候选框(bounding boxes)以及对这些框进行初步筛选。
R-Net(Refine Network):对 P-Net 生成的候选框进行进一步的筛选,同时生成更准确的边界框。
O-Net(Output Network):最终的网络,对边界框进行进一步的筛选和人脸特征点的预测。
MTCNN 的主要优势在于其能够在单个模型中完成多个任务,包括人脸检测、人脸边界框回归(bounding box regression)和人脸关键点(landmark points)定位。该模型通过级联的方式,逐步提高对人脸的检测精度。
具体效果如下:
可以看到训练出来的模型,有遮挡脸和运动模糊的数据集,识别的精确度也非常高
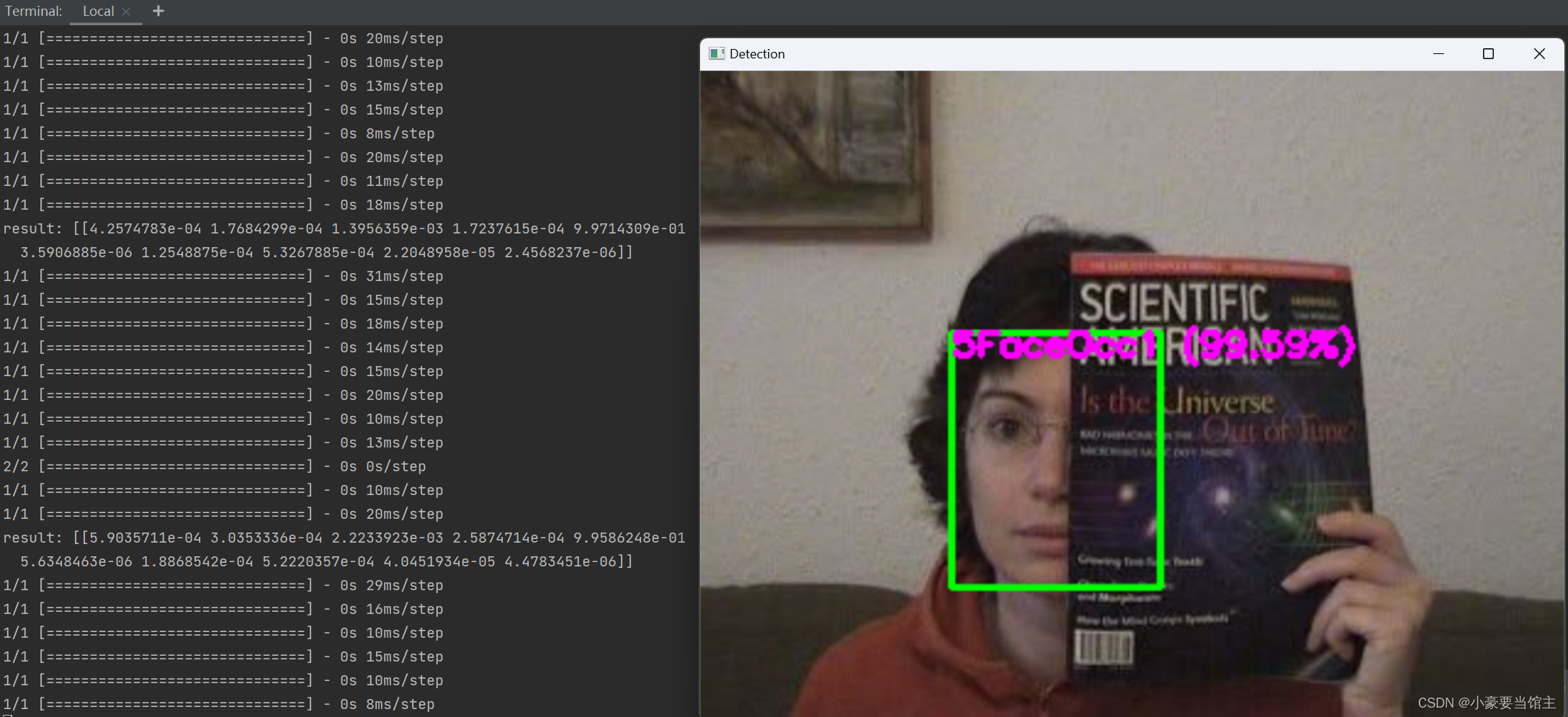
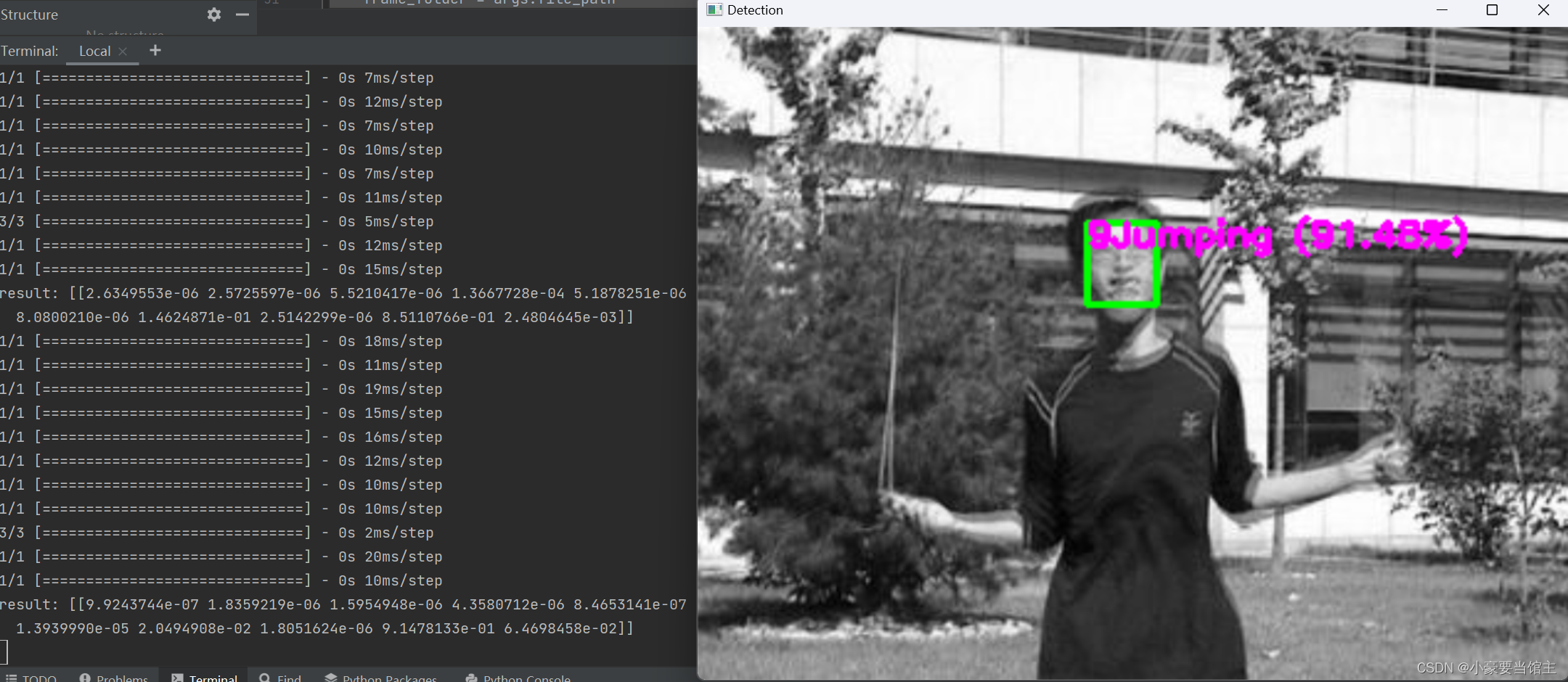
5.5 Haar级联分类器
在这里我还用haar级联分类器去识别人脸,发现精确度远远不如MTCNN高,但是运行速度却高了很多,代价确实每一帧的图像很难被识别到,对于遮挡和运动模糊等数据集,如下图:
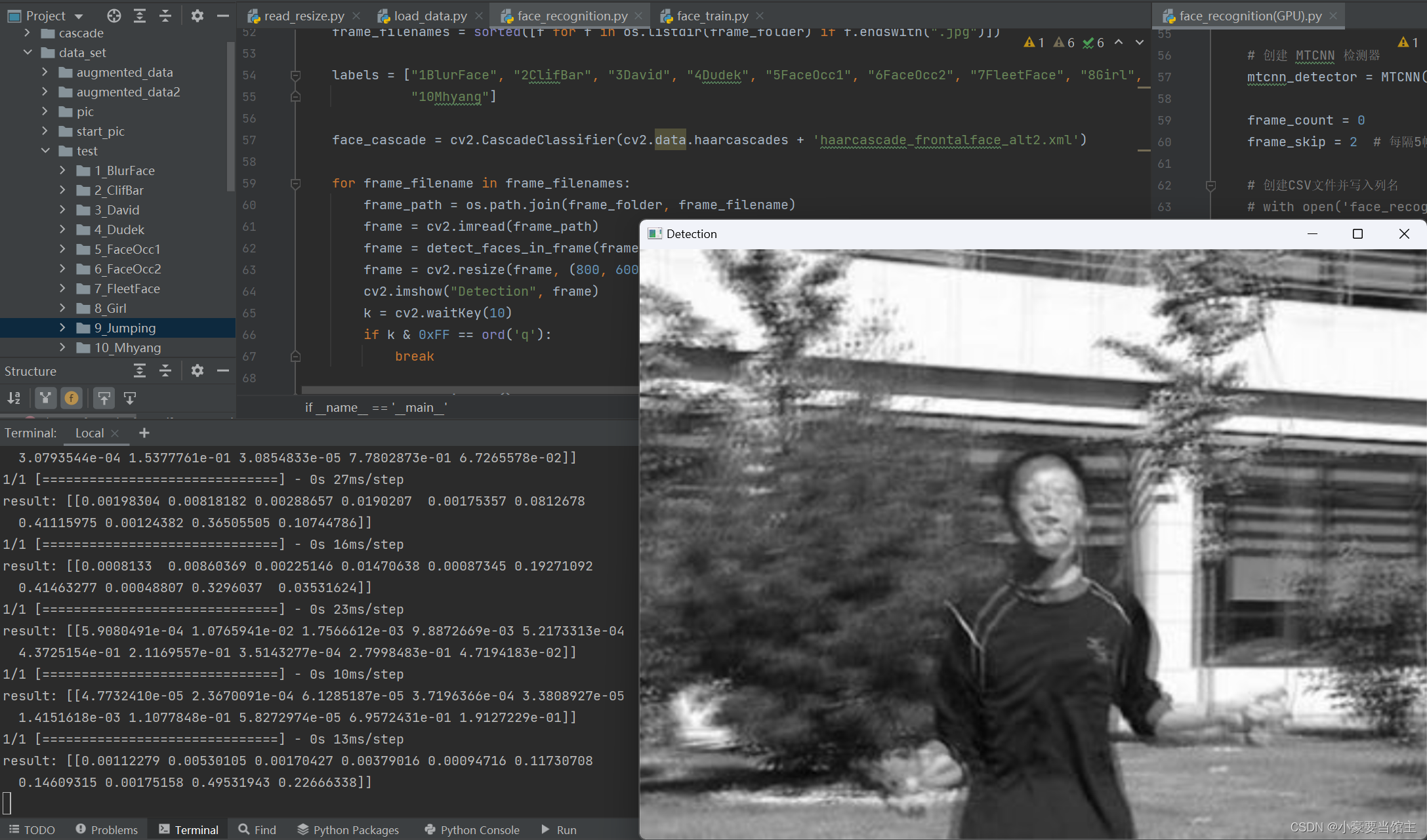
5.6 数据结果分析
通过识别每个人脸,得到了每一帧的人脸识别率,输出到一个csv文件上,得出图表如下:
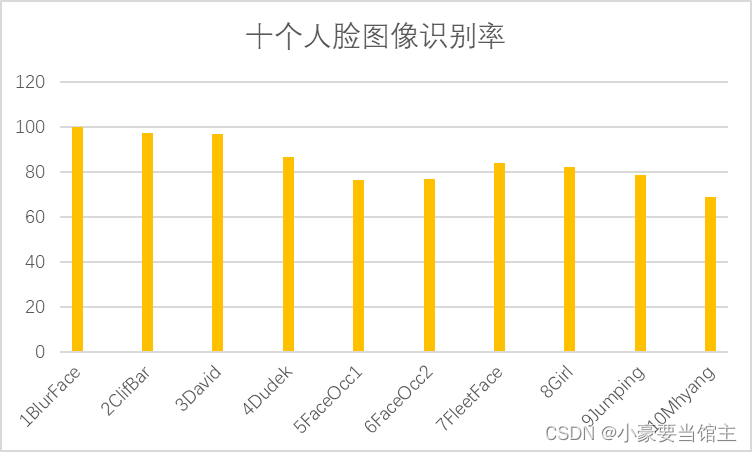
结果分析:
下面就具体分析一下识别率没达到90%的人脸图像是因为什么原因造成的
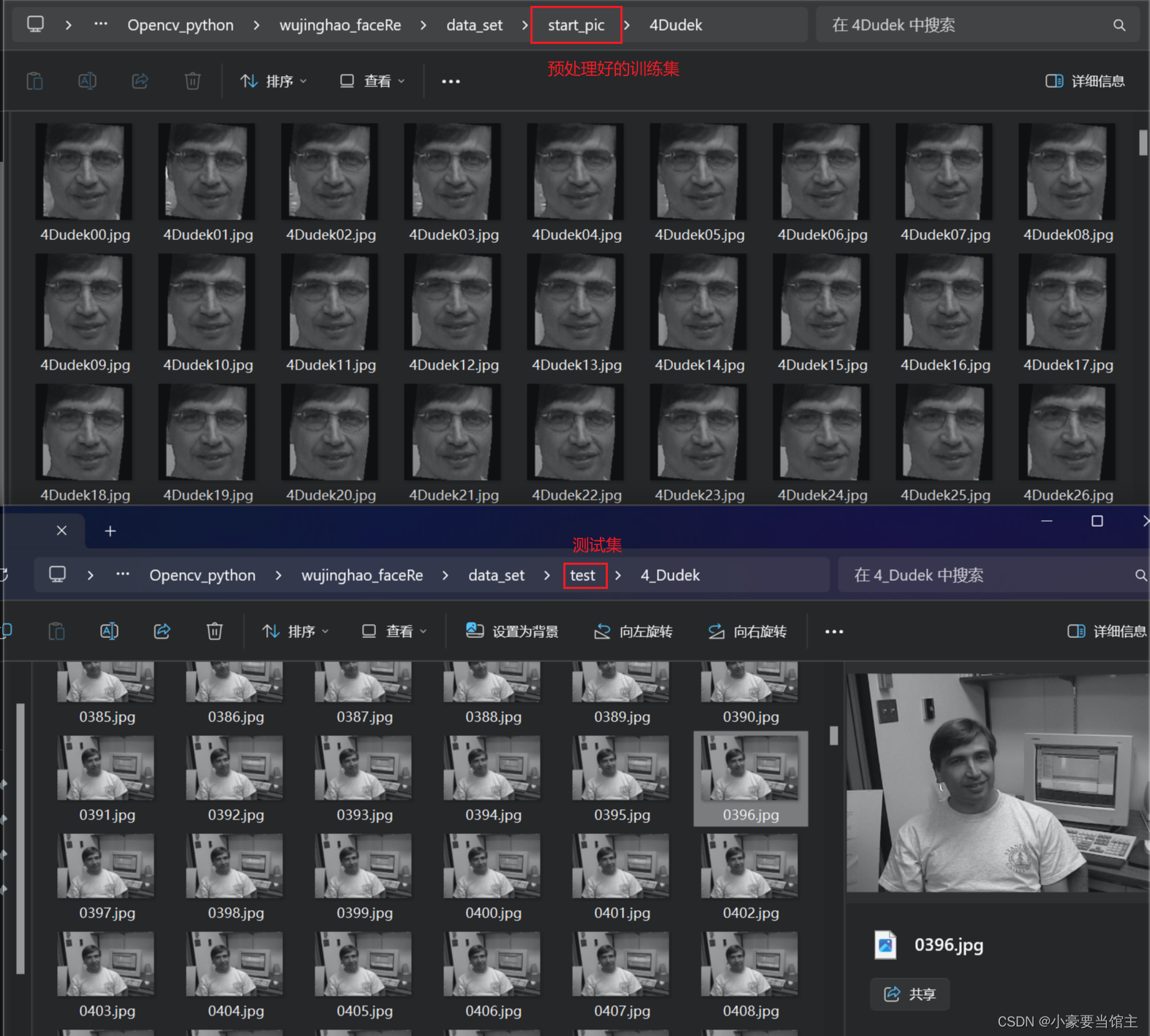
5.6.1 通过查看预处理好的图片,同时跟测试集(test)比较,可以看到4Dudek这个测试集有一半是没戴眼镜,而他的训练集(train)全部都是戴着眼镜的,所以这可能导致模型在未见过的情况下性能下降。如下图:
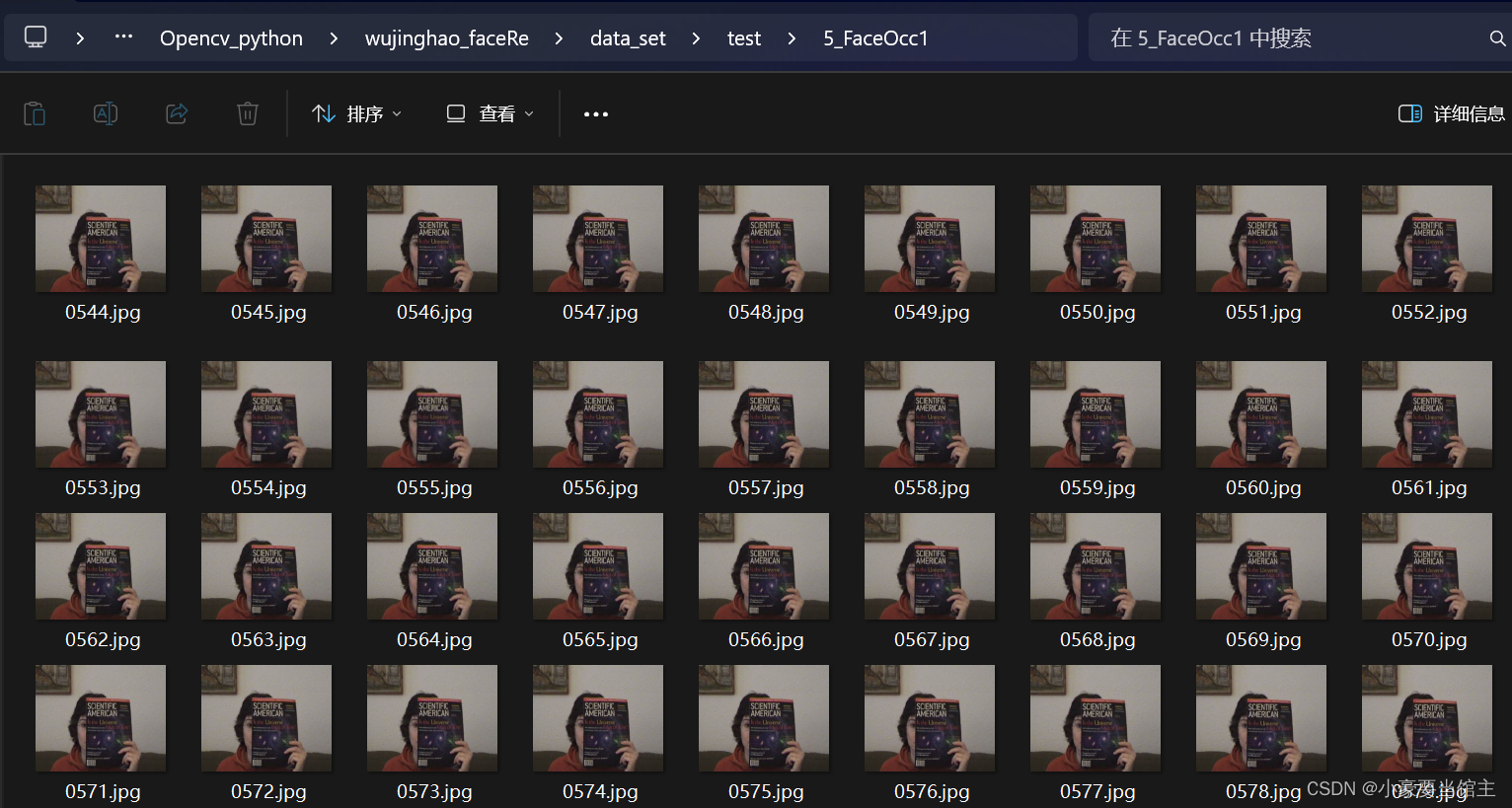
然后同样查看测试集,可以发现5FaceOcc1和6FaceOcc2,一个是很多图像集完全遮挡住了脸,导致分类器完全检测不了人脸,如下图:
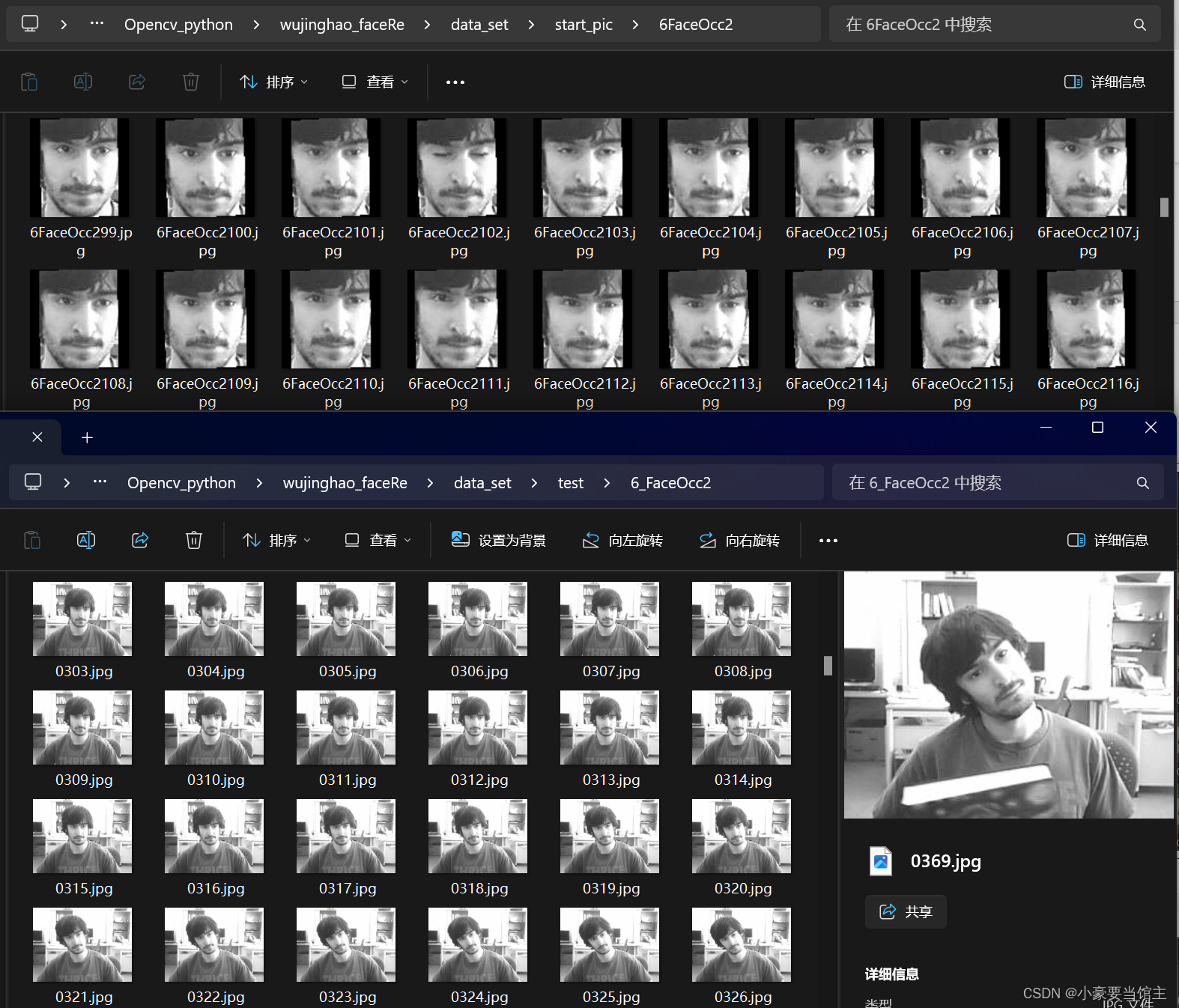
而6FaceOcc的测试集是因为很多都是侧脸,导致很多识别不出来,如下图:















 873
873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









