







多年前写的笔记,知识相对于现在肯定比较老了
YOLOv3
Paper : YOLOv3: An Incremental Improvement
单阶段
DarkNet
BackBone
-
BasicBlock,含两层(卷积 + BN + Leaky ReLU):第一层卷积输出通道数减半(罕见,一般都是通道数倍增),第二层卷积输出通道数倍增(恢复该BasicBlock输入的通道数),然后最后直接将输入和输出做elementwise_add,无需像ResNet那样downsample。BasicBlock输入与输出的张量维度相同
-
LayerWrap,含多个BasicBlock:DarkNet53的LayerWrap个数及其Basicblock块数为[1, 2, 8, 8, 4]
-
Downsample,含一层(卷积 + BN + Leaky ReLU):由于BasicBlock不改变数据的维度,所以DarkNet专门用downsample来提取特征,降低维度。
-
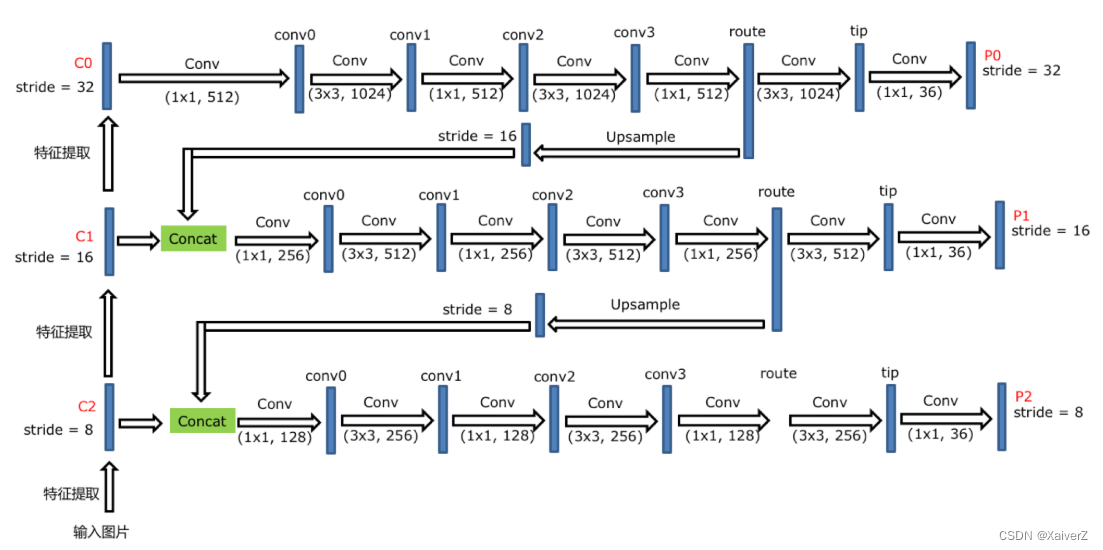
在原版YOLOv3中,DarkNet取最后三个LayerWrap输出的特征图做FPN
YoLoDetection
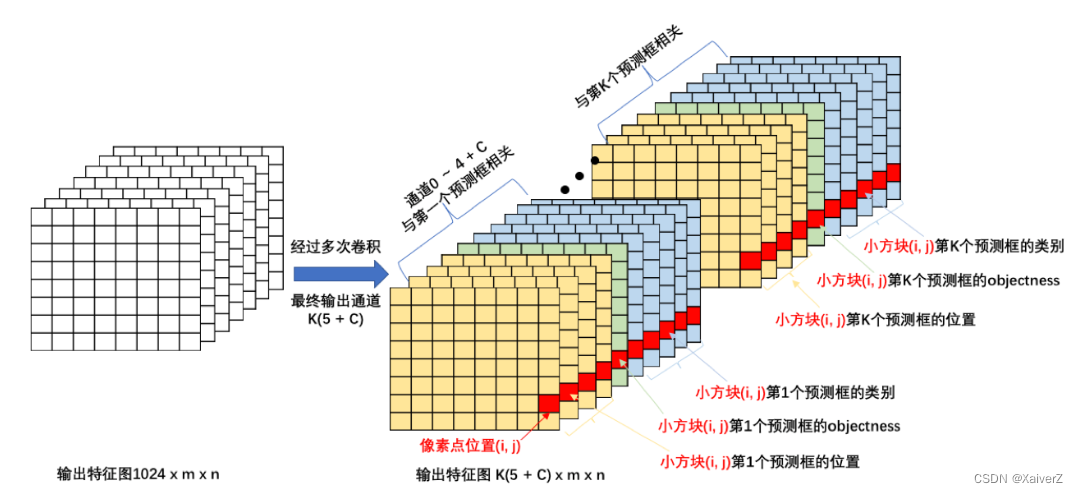
- 三个输出特征图都产生锚框与之对应,分别对应预设的三种不同大小锚框。FPN就是为了加强对小物体的检测,锚框虽然变多了3倍,但是能检出更多小物体
Faster R-CNN
Paper : Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
两阶段目标检测
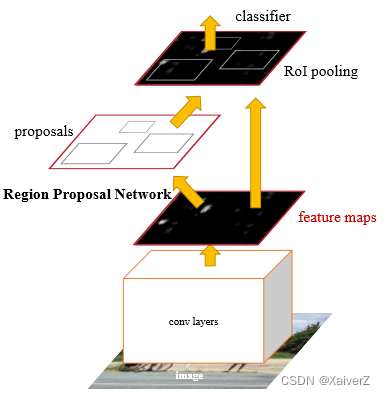
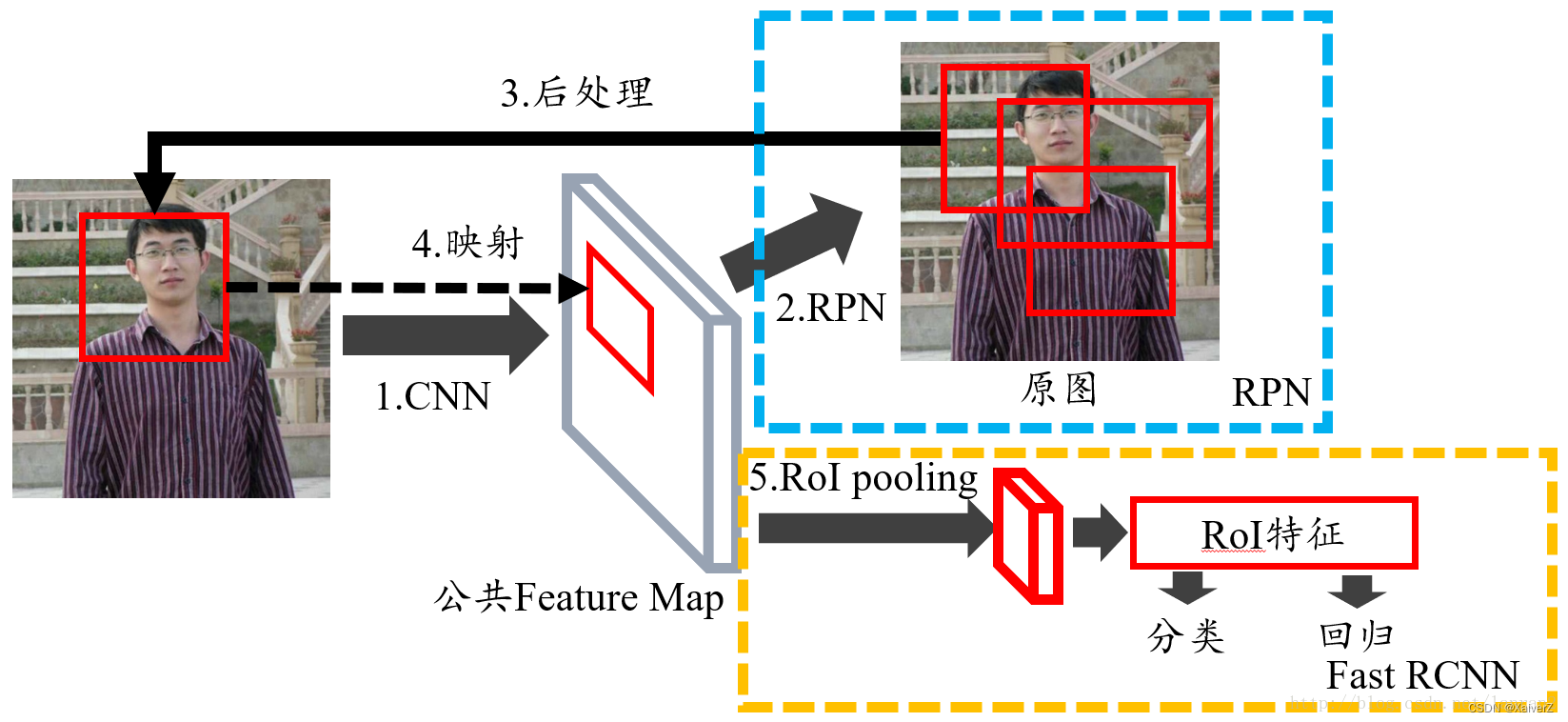
Stage One:RPN
Input Image => Shared Feature Map => RPN(Confidence Score + Coordinate) => Mapping Shared Feature Map => RoIs
-
RPN阶段大约会产生2k个候选区域,这些候选区域不会都拿去训练,而是挑选一些进行训练。例如在一些实现中,将候选区域与真实框IOU大于0.5的所有候选区域挑选出来并按前景置信度进行降序排列,选取置信度最大的k个作为正样本。然后将候选区域与真实框IOU小于0.3的所有候选区域挑出来升序排列,选取置信度最小的3k个作为负样本。(正负样本比例一般取1:3)
-
而在单阶段检测器,如YOLOv3中就没有控制正负样本的比例,从而导致正负样本数量极其不均衡,大量的负样本导致模型很难向正样本收敛。这也是为什么两阶段检测器精度比单阶段要高的原因。
Stage Two:RoI Pooling
RoIs => RoI Pooling => Classification + Regression
RetinaNet
Paper : Focal Loss for Dense Object Detection
单阶段目标检测
-
提出原因:单阶段目标检测中,生成的锚框中,前景占比肯定比背景要小的多,导致正负样本极不均衡。负样本过多,造成的loss过大,以至于把正样本的loss都淹没了,不利于目标收敛。大多数负样本都不在前景与背景的过渡区域上,分类很明确,置信度很高,称为简单样本。这些简单样本造成的损失很小,梯度更新也很小,对模型收敛作用很有限。而在两阶段目标检测中,在RPN阶段会对生成的区域按前景置信度进行排列并选出前1k~2k个置信度高的区域,这样就能把大部分简单样本给过滤掉。另外,还会根据IOU阈值来调整正负样本的比例,防止正负样本比例不均衡。本文通过改进单阶段检测器的Loss函数来达到抑制正负样本不均衡带来的影响。
-
损失函数:Focal Loss部分详见Loss Function-Focal Loss
-
网络结构:ResNet+FPN

- 其他:class subnet的最后一层卷积偏置初始化为 b i a s = − log ( ( 1 − π ) / π ) bias = -\log{((1 - π) / π)} bias=−log((1−π)/π)。目的是为了在网络训练初期正负样本分类概率差不多时,增强正样本的训练效果。
Retina U-Net
单阶段目标检测+语义分割
-
提出原因:大多数两阶段的语义分割检测器没有充分地利用语义分割监督:
- 仅在裁剪的候选区域上计算Mask Loss,也就是说,Mask Loss的梯度不会流过候选区域周围的地方
- 只有正样本的候选区域被用于继续计算Mask Loss,导致模型过拟合
- Mask Loss的梯度不会流过整个模型,只会从相应的FPN尺度特征图开始沿Top-Down结构向上流动
-
网络结构:Retina U-Net在前作Retina Net的基础上进行了改进。Retina Net的FPN是在P3-P6这几级特征图上进行分类和回归的,而Retina U-Net在P2-P5上进行分类和回归,相对来说特征图的分辨率更高,对小物体的检测效果更好。
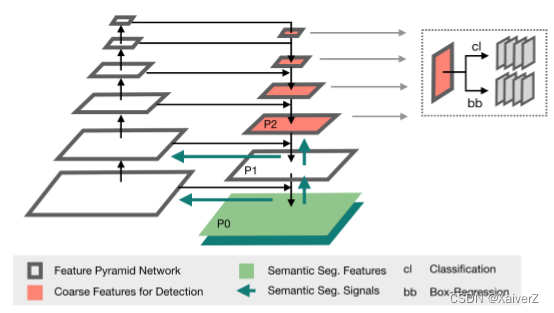
- 语义分割监督:Retina U-Net对FPN的层级进行了延伸,沿Top-Down继续往下多计算了两个层级的特征图,最后一个特征图用于语义分割任务。这样的结构使Mask Loss的产生的梯度能够沿Top-Down结构向上反向传播,而且梯度还会跳接到Bottom-Up中。这样一来Mask Loss就能流经整个模型进行反向传播了。















 2884
2884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









