









#为了方便以后自己查询和复习,写了一个简短的总结;代码部分是参考其他博主
1. 固定优先级
假设request低bit优先级更高,那么低位到高位,最先出现1的那一位被对应的request被grant,那问题就变成了如何从一个01串中寻找最先出现bit 为1的那一位,这里最经典的方法就是:equest和它的2的补码按位与。可以用增值表举例子看看
代码如下:
module prior_arb #(
parameter REQ_WIDTH = 16
) (
input [REQ_WIDTH-1:0] req,
output [REQ_WIDTH-1:0] gnt
);
assign gnt = req & (~(req-1));
endmodule
2. 轮询仲裁器
先考虑固定优先级的仲裁器,基于以下结论:A & ~(A- base) 的结果就是保留base对应位的A的左边的第一个1,其他的设为0,例如A= 0100100 , base= 0001000,结果为010000,base为onehot,base的[3] bit为1,那么结果就是找到A的第3 bit的左边的第一个1 ;
在没有仲裁前,base对应的位的权重最高,左边位权重次之,右边位权重最低,仲裁后,base对应的权重最低,左边位权重最高,右边为权重倒数第二低,也就是权重最高位左移,所以每次仲裁后我们需要左移一位。
代码如下:
wire[2*NUM_REQ-1:0] double_req = {req,req};
wire[2*NUM_REQ-1:0]double_gnt = double_req & ~(double_req - base);
assign gnt = double_gnt[NUM_REQ-1:0] | double_gnt[2*NUM_REQ-1:NUM_REQ];
logic [NUM_REQ-1:0] hist_q, hist_d;
assign base = hist_q ;
always_ff@(posedge clk) begin
if(!rstn)
hist_q <= {{NUM_REQ-1{1'b0}}, 1'b1};
else
if(|req)
hist_q <= {gnt[NUM_REQ-2:0, gnt[NUM_REQ-1]};
上述实现方式很容易理解,但是在硬件实现上减法器,如果request位宽比较大,整体的时序和面积不是很理想。
另外一种算法就是:如果某一路request被grant,那我们就把该路mask掉,再仲裁剩下的路,剩下路的权重不变;如果所有的request都被仲裁完了,那我们重新做载入新的mask。根据request,从最低位开始判断,如果第i 位为1,那么mask的第i+1位到最高位都是1,第0位到第i位为0, mask and request的结果作为简单优先级仲裁器的输入请求。然后再找到为1的最低位。
原理图如下:
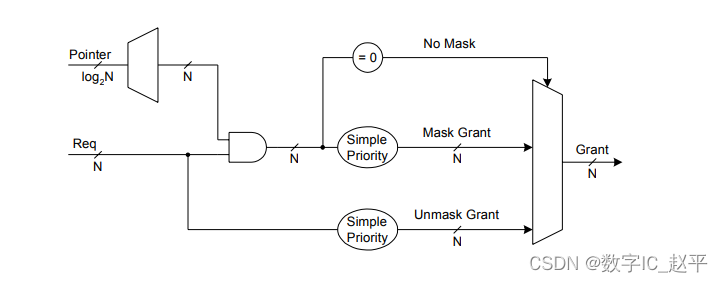
这里转载下代码:
module round_robin_arbiter #(
parameter N = 16
)(
input clk,
input rst,
input [N-1:0] req,
output[N-1:0] grant
);
logic [N-1:0] req_masked;
logic [N-1:0] mask_higher_pri_reqs;
logic [N-1:0] grant_masked;
logic [N-1:0] unmask_higher_pri_reqs;
logic [N-1:0] grant_unmasked;
logic no_req_masked;
logic [N-1:0] pointer_reg;
// Simple priority arbitration for masked portion
assign req_masked = req & pointer_reg;
assign mask_higher_pri_reqs[N-1:1] = mask_higher_pri_reqs[N-2: 0] | req_masked[N-2:0];
assign mask_higher_pri_reqs[0] = 1'b0;
assign grant_masked[N-1:0] = req_masked[N-1:0] & ~mask_higher_pri_reqs[N-1:0];
// Simple priority arbitration for unmasked portion
assign unmask_higher_pri_reqs[N-1:1] = unmask_higher_pri_reqs[N-2:0] | req[N-2:0];
assign unmask_higher_pri_reqs[0] = 1'b0;
assign grant_unmasked[N-1:0] = req[N-1:0] & ~unmask_higher_pri_reqs[N-1:0];
// Use grant_masked if there is any there, otherwise use grant_unmasked.
assign no_req_masked = ~(|req_masked);
assign grant = ({N{no_req_masked}} & grant_unmasked) | grant_masked;
// Pointer update
always @ (posedge clk) begin
if (rst) begin
pointer_reg <= {N{1'b1}};
end else begin
if (|req_masked) begin // Which arbiter was used?
pointer_reg <= mask_higher_pri_reqs;
end else begin
if (|req) begin // Only update if there's a req
pointer_reg <= unmask_higher_pri_reqs;
end else begin
pointer_reg <= pointer_reg ;
end
end
end
end
endmodule3 权重循环仲裁器
所谓的权重,就是当某个请求过来,能够累计grant的过程,这样能够轮询的同时,又能可以设定公平系数。
“ 和Round robin不同的是对于mask的调整。回想一下,round robin里的mask是,只要第i路被许可,那么从0到第i路的req都会被mask掉,只允许更高位的request 通过,去往上面的那个Masked Priority Arbiter。但是对于Weighted Round Robin,一次grant不足以立刻让这一路request被mask掉,而是要看这一路的counter值,如果counter值还没有减为0,那么就认为这一路依然有credit,mask值就和之前保持不变,下次仲裁的时候依然可以选择这一路grant。”
由于基于request的时序和面积更加友好,所以这里只转载request代码
module weight_rr_arbiter(
clk,
rst_n,
req,
weight,
grant,
grant_vld,
grant_ff,
grant_ff_vld,
switch_to_next
);
parameter REQ_CNT = 4;
parameter GRANT_WIDTH = 5;
parameter INIT_GRANT = {{REQ_CNT-1{1'b0}}, 1'b1};
parameter WEIGHT_WIDTH = GRANT_WIDTH * REQ_CNT;
input clk;
input rst_n;
input [REQ_CNT-1:0] req;
input [WEIGHT_WIDTH-1:0] weight;
input switch_to_next;
output [REQ_CNT-1:0] grant;
output grant_vld;
output [REQ_CNT-1:0] grant_ff;
output grant_ff_vld;
wire [REQ_CNT-1:0] grant;
wire grant_vld;
reg [REQ_CNT-1:0] grant_ff;
reg grant_ff_vld;
wire no_req;
wire no_grant;
wire first_grant;
wire arb_trig;
reg [GRANT_WIDTH-1:0] priority_cnt [REQ_CNT-1:0];
wire [REQ_CNT-1:0] cnt_over;
wire round_en;
assign no_req = ~(|req);
assign no_grant = ~(|grant_ff);
assign first_grant = ~no_req && no_grant;
assign arb_trig = first_grant || switch_to_next;
assign round_en = |cnt_over[REQ_CNT-1:0];
wire [REQ_CNT-1:0] req_masked;
wire [REQ_CNT-1:0] mask_higher_pri_reqs;
wire [REQ_CNT-1:0] grant_masked;
wire [REQ_CNT-1:0] unmask_higher_pri_reqs;
wire [REQ_CNT-1:0] grant_unmasked;
wire no_req_masked;
reg [REQ_CNT-1:0] mask_next;
//Simple priority arbitration for masked portion
assign req_masked[REQ_CNT-1:0] = req & mask_next;
assign mask_higher_pri_reqs[0] = 1'b0;
assign mask_higher_pri_reqs[REQ_CNT-1:1] = req_masked[REQ_CNT-2:0] | mask_higher_pri_reqs[REQ_CNT-2:0];
assign grant_masked[REQ_CNT-1:0] = req_masked[REQ_CNT-1:0] & ~mask_higher_pri_reqs[REQ_CNT-1:0];
//Simple priority arbitration for unmasked portion
assign unmask_higher_pri_reqs[0] = 1'b0;
assign unmask_higher_pri_reqs[REQ_CNT-1:1] = req[REQ_CNT-2:0] | unmask_higher_pri_reqs[REQ_CNT-2:0];
assign grant_unmasked[REQ_CNT-1:0] = req[REQ_CNT-1:0] & ~unmask_higher_pri_reqs[REQ_CNT-1:0];
//Use grant_masked if there is any there, otherwise use grant_unmasked
assign no_req_masked = ~(|req_masked);
assign grant = ({REQ_CNT{no_req_masked}} & grant_unmasked) | grant_masked;
assign grant_vld = (arb_trig && |req)? 1'b1 : 1'b0;
//round cnt
generate
genvar i;
for(i=0;i<REQ_CNT;i=i+1)begin
assign cnt_over[i] = (priority_cnt[i] == weight[GRANT_WIDTH*(i+1)-1-:GRANT_WIDTH]-1'b1);
always @(posedge clk or negedge rst_n)begin
if(!rst_n)
priority_cnt[i] <= {GRANT_WIDTH{1'b0}};
else if(cnt_over[i])
priority_cnt[i] <= {GRANT_WIDTH{1'b0}};
else if(grant[i] && grant_vld)
priority_cnt[i] <= priority_cnt[i] + 1'b1;
end
end
endgenerate
//pointer update
always @(posedge clk or negedge rst_n)begin
if(!rst_n)
mask_next <= {REQ_CNT{1'b1}};
else begin
case({first_grant,round_en})
2'b10:begin
if(|req_masked)
mask_next <= req_masked | mask_higher_pri_reqs;
else
mask_next <= req | unmask_higher_pri_reqs;
end
2'b01,2'b11:begin
if(|req_masked)
mask_next <= mask_higher_pri_reqs;
else begin
if(|req)
mask_next <= unmask_higher_pri_reqs;
else
mask_next <= mask_next;
end
end
default:mask_next <= mask_next;
endcase
end
end
always @(posedge clk or negedge rst_n)begin
if(!rst_n)begin
grant_ff <= {REQ_CNT{1'b0}};
grant_ff_vld <= 1'b0;
end
else if(arb_trig)begin
grant_ff <= grant;
grant_ff_vld <= no_req? 1'b0 : 1'b1;
end
else begin
grant_ff <= grant_ff;
grant_ff_vld <= grant_ff_vld;
end
end
endmodule















 2122
2122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









