







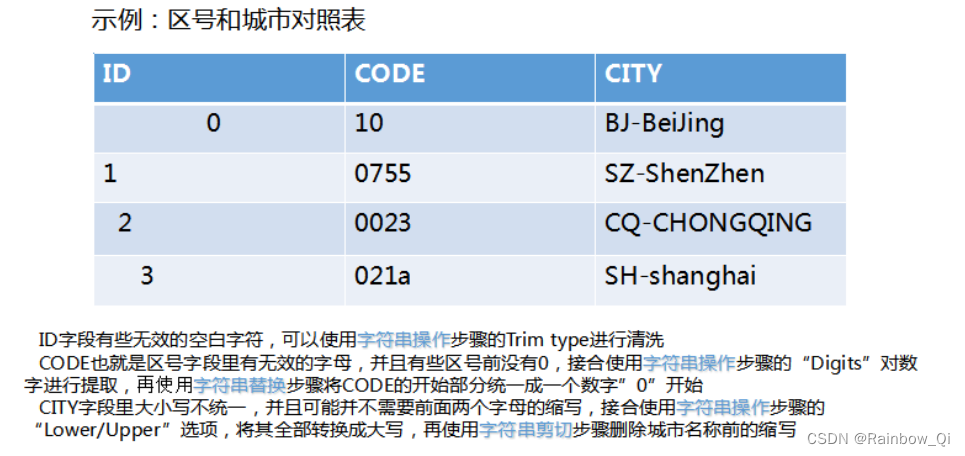
Part 1 字符串清洗
实验背景:
主要介绍转换目录下的三个字符串清洗步骤:

实验步骤:
-
转换图

2.步骤的配置
输入。新建一个转换,取名为string_op,
使用“输入自定义常量数据(Data Grid)”步骤作为输入:在“元数据(Meta)”选项页,创建三个字段,类型都设为“String”
在“数据(Data)”选项页输入前面的示例数据

添加“字符串操作”步骤,从“Data Grid”步骤创建一个跳到该步骤,对“字符串操作”步骤做如下设置:
输入字段里添加ID字段,设置“Trim Type”为“both”状态,以去除首尾的空白字符;输入字段添加CITY字段,设置“Lower/Upper”为“upper”状态,将其全部转换成大写状态 ;输入字段添加CODE字段,设置“Digits”为“only”状态以过滤掉无效的字母。

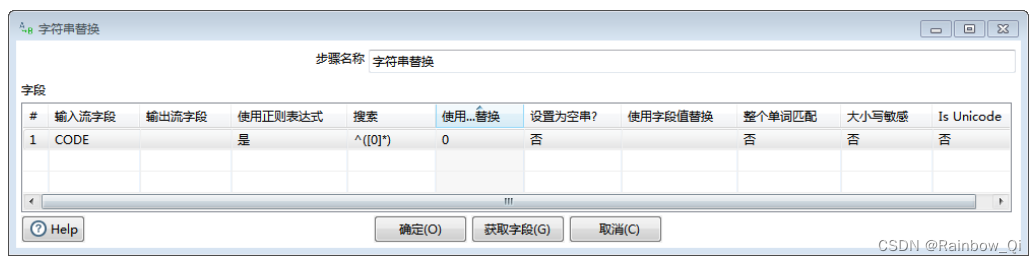
添加“字符串替换
”步骤,从“String operations”步骤创建一个跳到该步骤。
这时我们需要一个正则表达式来匹配CODE字段的开始部分,可以写成 “^([0]*)” 形式。
该正则表达式表示一个字符串的开始部分,该部分由任意个数字0组成。
另外 ,需要使用到正则表达式做替换的时候,需要将“use RegEx”设置成“Y”状态,以表示我们查找的是一个正则匹配。
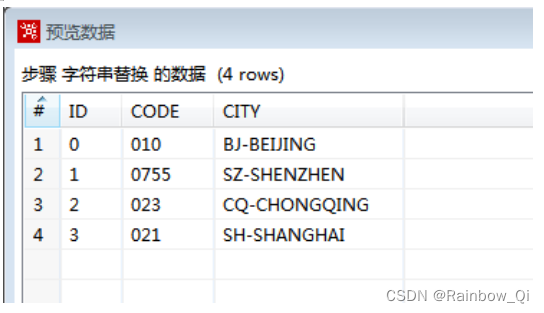
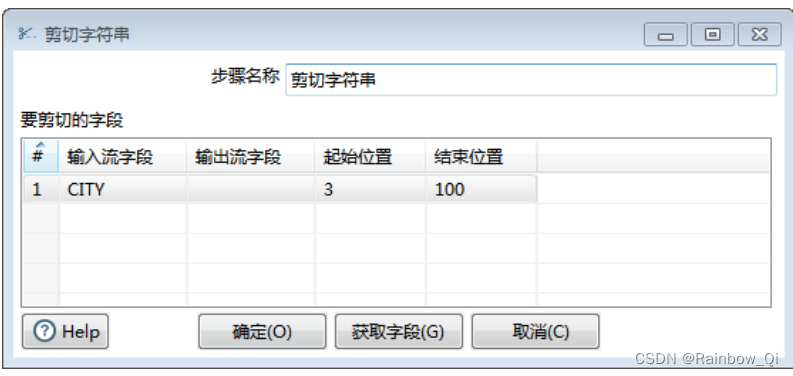
在使用该步骤进行清理时,这里有个假设,那就是城市名前面的缩写以及连接符刚好为3个字符,并且城市名长度不会超过100
”Cut from”设为”3“,表示从第3个字符开始剪切,
”Cut from”设为”100“,表示最多剪切至第99个字符。
这里注意,这里描述的第几个字符是以0开始计数的。
3.转换结果

Part 2 字段清洗
实验背景:


实验步骤:
- 步骤的配置和转换图
转换1:用拆分字段成多行步骤将城市字段拆分成多行
新建一个转换field_op,添加一个输入步骤Data Grid,输入如下数据:为该步骤添加三个字段:编号、省份、城市,类型都选择为”String“,并添加如图所示的示例数据。
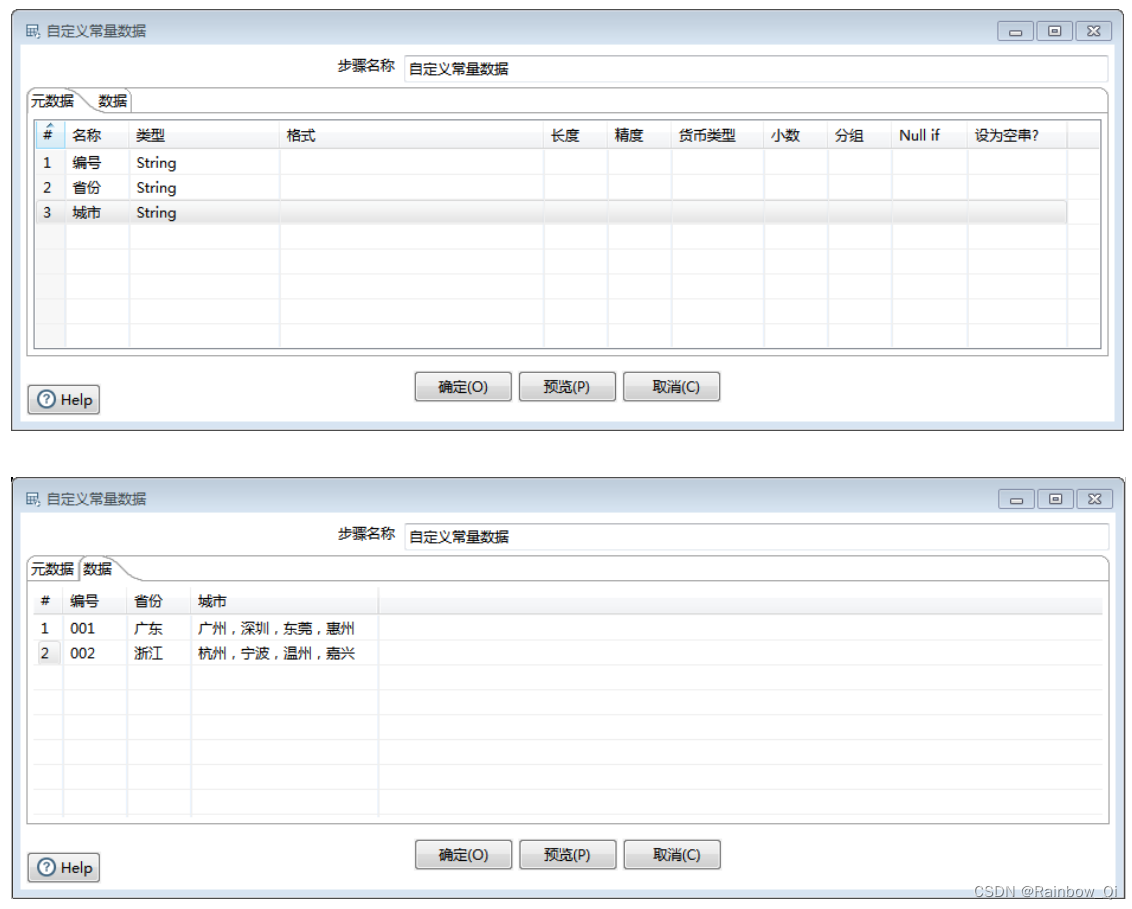
新字段设置成“城市NEW”
示例中的数据以“,”分隔,这是一个中文逗号,分隔符可以设置成“,”
但是如果既有中文逗号,又有英文逗号, 甚至还有中英文分号,或者顿号,这时怎么办?由于该步骤的分隔符支持正则表达式,不妨将分隔符设成正则形式[,,;;、],将可能的分隔符用一个方括号括起来,同时选中”Dlimiter is a Regular Expression“这个选项就可以了。

转换2:用拆分字段步骤和合并字段步骤进行数据的拆分和合并
新建一个转换field_op_1,该步骤的输入可以复制前面的Data Grid步骤。
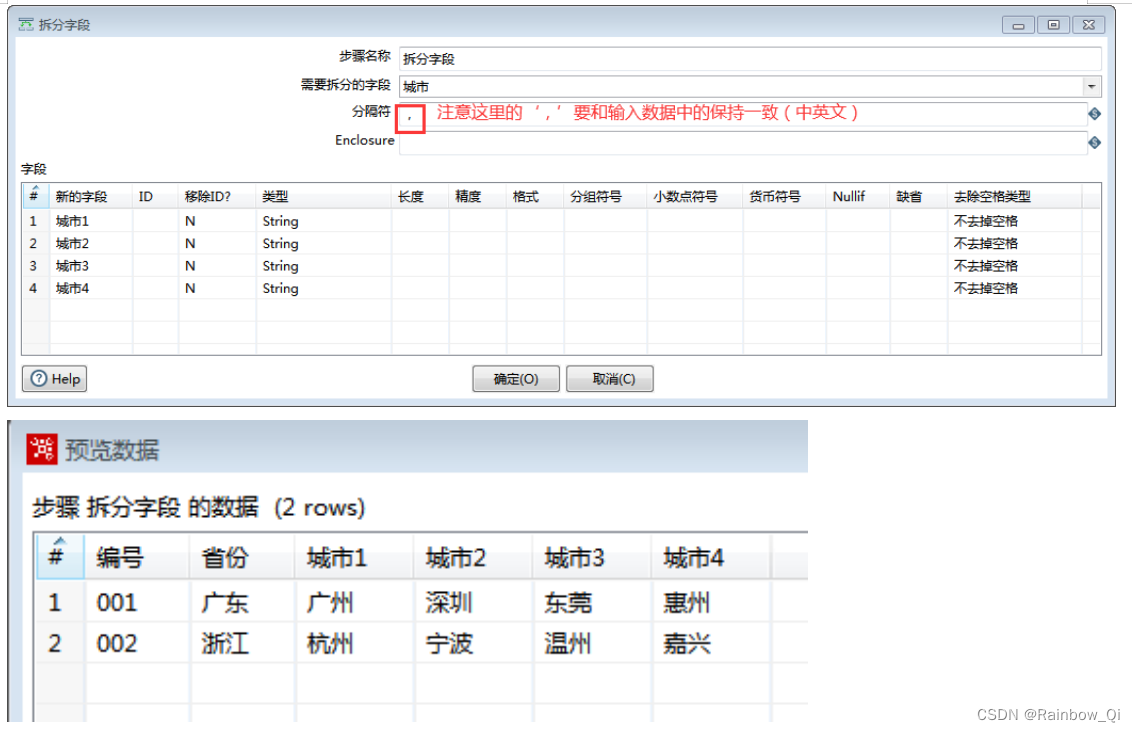
添加一个”拆分字段(Split Fields)“步骤,拆分字段步骤设置:
拆分字段设为城市,分隔符设为“,”
设置四个新的字段,分别为城市1、城市2、城市3、城市4,类型都为String
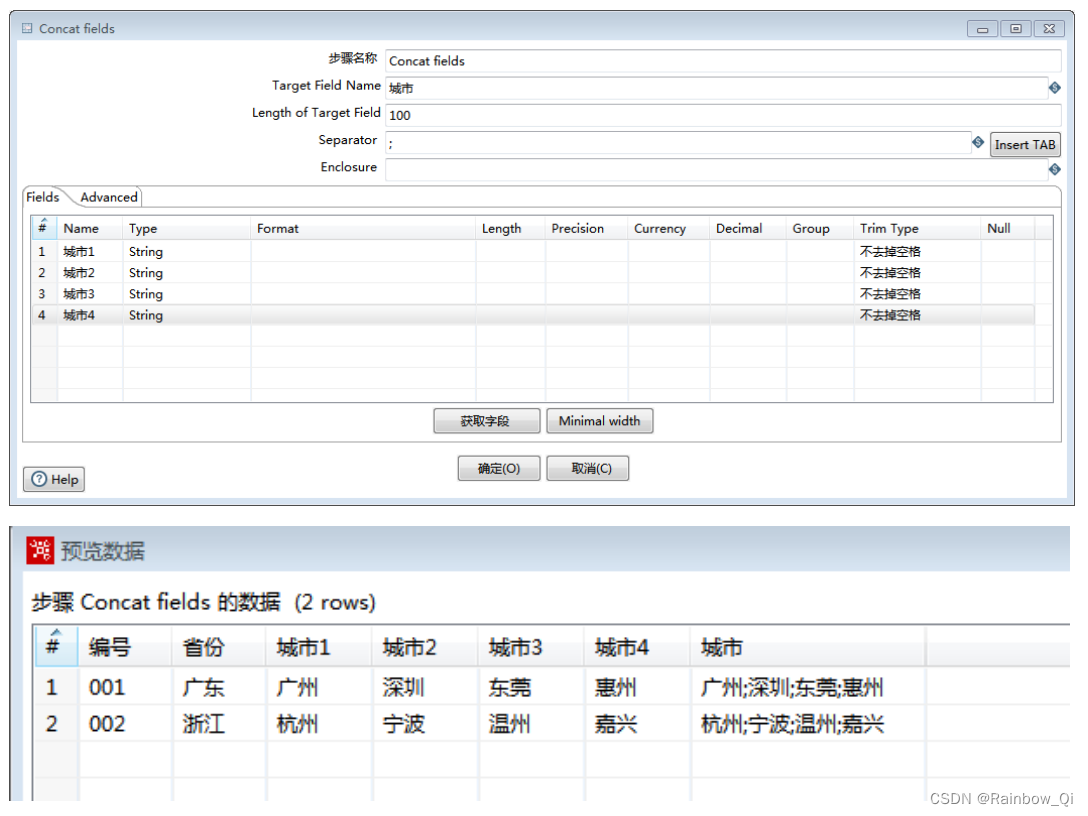
合并字段选择这四个字段:城市1、城市2、城市3、城市4
输出字段设为城市, 将其长度设为100
分隔符设为”;”

转换3:使用字段选择步骤清洗数据
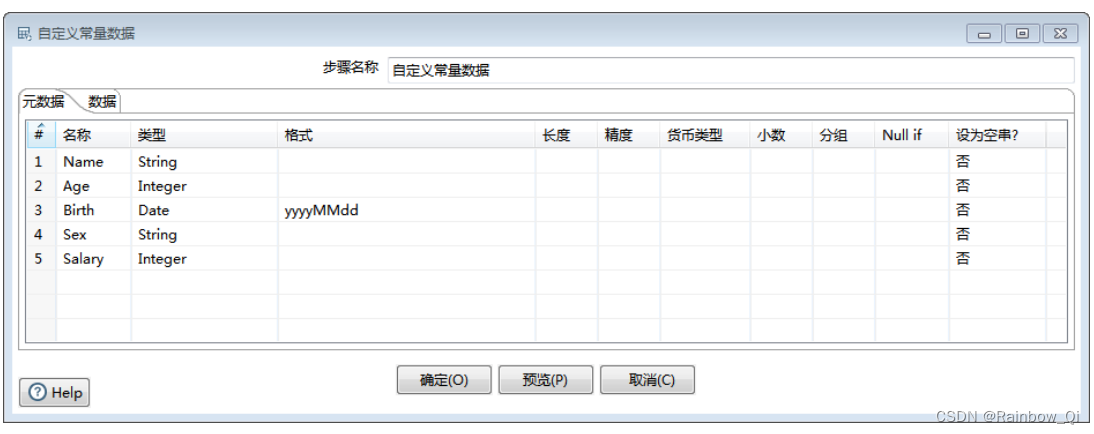
新建一个转换field_op_2,添加一个输入步骤Data Grid,输入如下数据:为该输入步骤添加五个字段, 并设置好相应的数据类型。
然后输入一组数据用于示例演示。
添加一个”字段选择(Select Values)“步骤,命名为”Select Values-remove“。
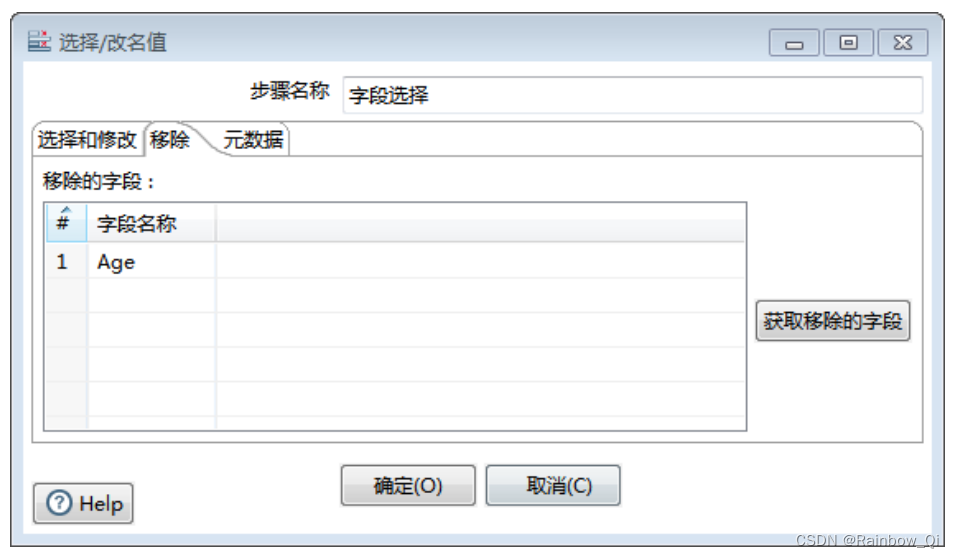
第一步,删除“Age”字段。
在“移除”选项页里添加“Age”字段,将“Age”字段删除。此时可以预览一下该步骤,会发现输出记录已经没有”Age“字段。
第二步,添加一个”字段选择(Select Values)“步骤,命名为”Select Values-meta“。
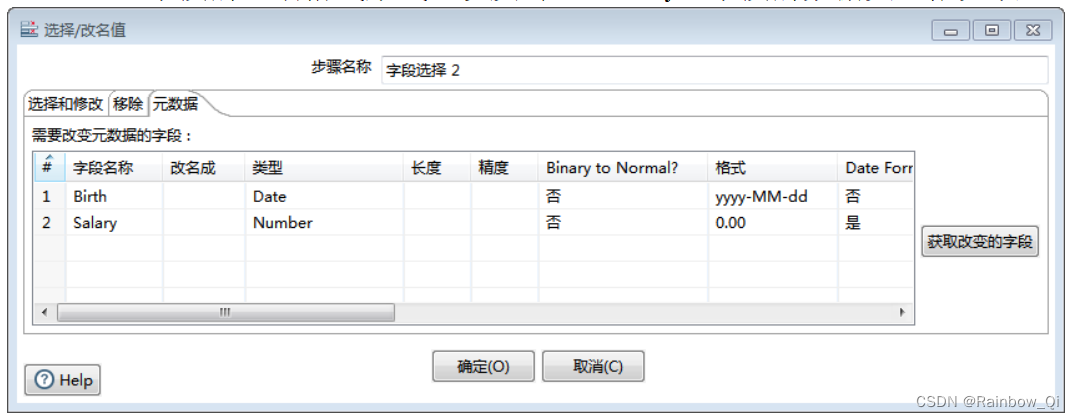
这一步主要针对修改元数据做设置,只需要在“元数据”选项页中修改“Birth”字段的日期格式形式,以及对“Salary”字段的数据类型做更改。
第三步,添加一个”字段选择(Select Values)“步骤,命名为”Select Values-alter“。
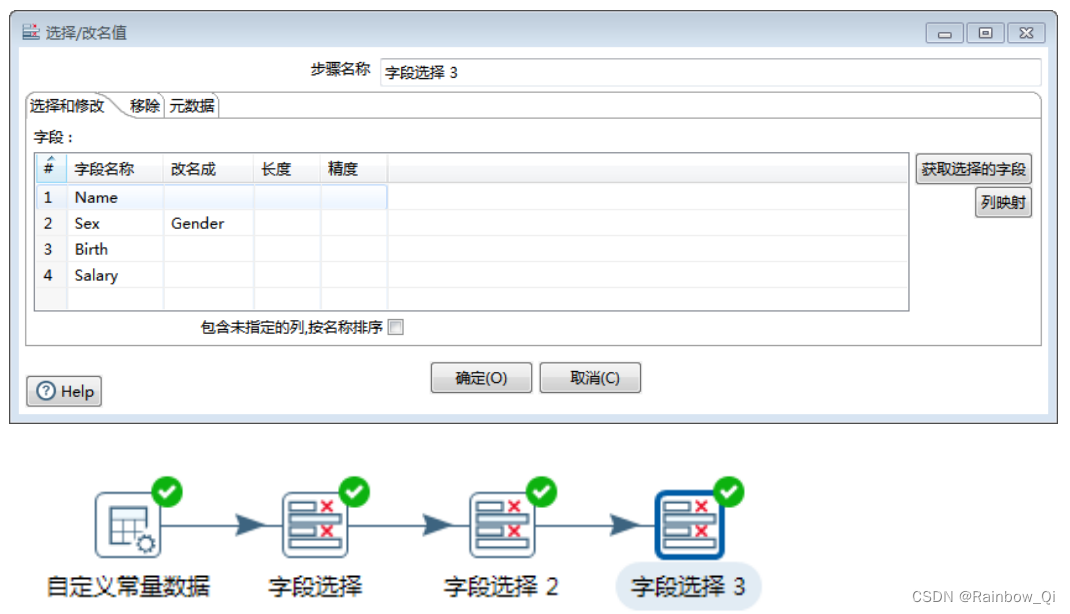
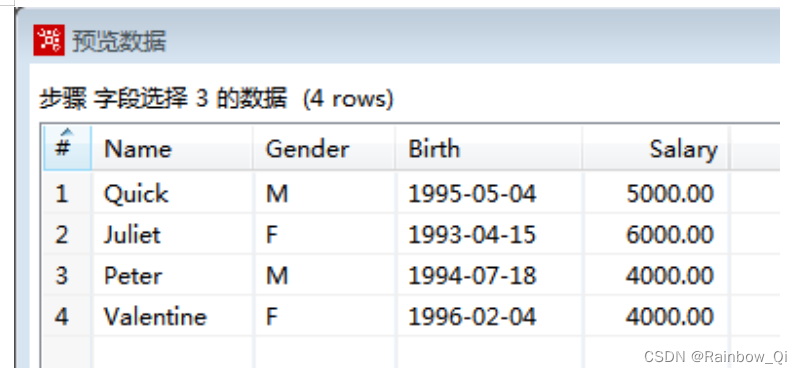
在“选择和修改”选项页中将“Sex”字段重命名为“Gender”,并调整“Gender”字段到“Name”字段后面。

实验总结:
一切的美好都是建立在庞大而整洁的数据之上,然而,现实中的数据却是:杂!脏!乱!“错进!错出!”数据的质量可能非常的差,充斥着各种问题,比如数据有重复记录、数据是不完整有缺失的、各个来源的数据不一致,更有甚者,有些数据是错误的。要想利用这些数据,我们必须要对这些数据做数据清理。
数据清理,就是试图检测和去除数据集中的噪声数据和无关数据,处理遗漏数据,去除空白数据域和知识背景下的白噪声,解决数据的一致性、唯一性问题,从而达到提高数据质量的目的。
Kettle 没有单一的清洗步骤清洗工作,需要结合多个步骤来完成。通过本次实验,对字符串和字段的清洗有了一些了解,熟悉了kettle中的一些转换步骤和配置。















 3386
3386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









