







 本文详细介绍了图书数据清洗的概念,包括数据清洗的必要性、理论基础以及实际操作步骤,如去除价格符号、提取数值、处理出版信息和用户隐私等。通过实例展示了清洗过程,以确保数据质量和隐私安全,为后续数据分析和可视化做准备。
本文详细介绍了图书数据清洗的概念,包括数据清洗的必要性、理论基础以及实际操作步骤,如去除价格符号、提取数值、处理出版信息和用户隐私等。通过实例展示了清洗过程,以确保数据质量和隐私安全,为后续数据分析和可视化做准备。
目录
图书数据清洗
1.图书数据清洗的概念
图书数据清洗是指对图书相关的数据进行预处理和整理,以确保数据的质量和准确性。清洗过程包括去除重复数据、处理缺失值、纠正错误数据、标准化数据格式等,以便后续的数据分析和可视化工作。
2.图书数据清洗及可视化的理论基础
数据清洗是指对收集到的原始数据进行预处理、规范化和整理,以便于后续的分析和可视化。常见的数据清洗技术包括数据去重、填充缺失值、处理异常值、处理重复值等。数据清洗的理论基础包括数据预处理方法、数据质量评估标准和数据清洗算法等。
3.图书数据清洗的现状及问题
数据质量问题:原始图书数据往往存在缺失值、错误值、重复值等质量问题,这就需要进行数据清洗。然而,清洗过程中可能会遇到一些困难,例如如何确定缺失值的填充方式、如何处理异常值等。
数据整合问题:图书数据来自不同渠道和来源,可能存在格式不统一、命名不一致等问题,这给数据的整合带来了困难。特别是在进行图书分类和标注时,需要解决不同分类系统之间的映射问题。
用户隐私问题:图书数据往往涉及用户的阅读行为和个人偏好等敏感信息。在进行数据可视化时,需要注意保护用户隐私,不能泄露个人身份和具体阅读内容。
4.图书数据清洗实验报告
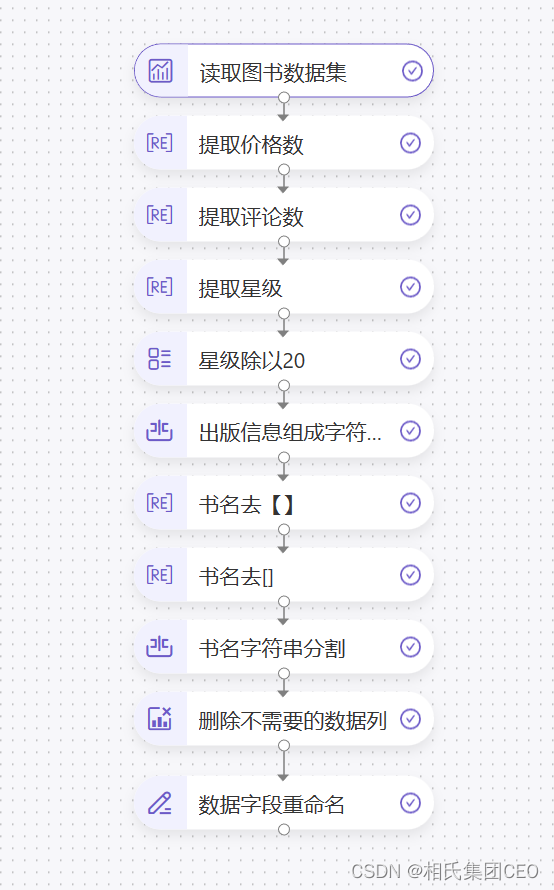
1 读数据表
首先,我们读取原始数据。可以看出原始数据中有许多问题,例如当前价格带有人民币符号'¥&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









