






Hadoop-HDFS(分布式文件存储系统)
大数据思想思维
分而治之
把一个复杂的问题分解成若干的小问题来解决
查重
有一个1G的内存,需要对1T的数据进行去重

解决方案:
1.将所有数据读入内存,从第一行开始依次比较,找到重复的两行去重
2.1T分为多个1G数据,分别对1G的数据进行处理。怎么分才能确保相同两行在同一个1G文件中?(使用Hash取余,只有数据相同的两行哈希值相同),再利用HashSet去重即可
在java中只有"重地"和"通话"的哈希值一致。
分而治之:将海量数据按照服务器性能进行拆分,解决问题的核心方法不变,将这个方法映射到多份数据上。
排序
有一个1G的内存,需要对1T的数据进行排序

在每个文件内使用快排,完了以后成为一个一个的文件,文件内部有序,如何使文件之间有序,可以使用归并排序,把每个文件的每一行拿出来进行比较。
HDFS的架构模型
客户端:
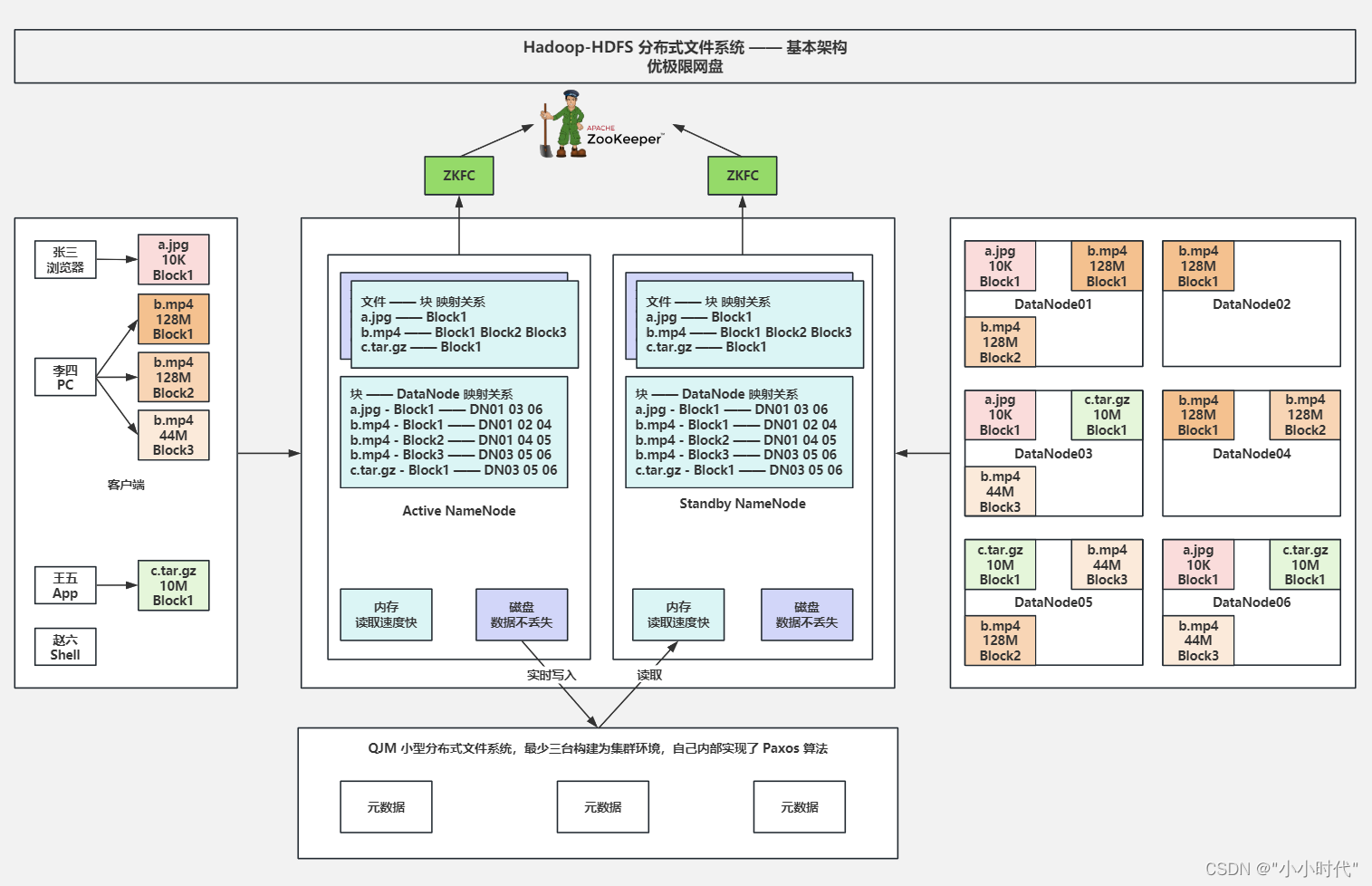
1.发起文件的上传下载的请求到NameNode,NameNode会根据DataNode的资源情况以及机架感知策略返回可用节点。
2.直接和DataNode建立连接完成文件的上传下载。
3.客户端设置一个文件分割阈值,当文件超过阈值是,对文件进行切分,切分为多个块上传。
NomeNode
1.NameNode负责存储文件的元数据(映射关系)。
2.为了元数据不丢失,肯定需要持久化落盘存储,为了快速响应客户端元数据还需放入内存。
3.将文件与块的映射关系存入内存与磁盘,但是块与DataNode的映射关系只存入内存,因为DataNode可能会宕机,这层关系持久化无意义。
4.Client发起文件上传下载的请求到ActiveNameNode,ActiveNameNode会根据DataNode的资源情况以及机架感知策略返回可用节点。
5.为了保证NameNode的高可用,Hadoop2.x版本中引入了ZooKeeper解决单点故障问题,使用ZooKeeper完成Hadoop集群的选主以及主备切换。主被称为Active,备被称为standby。
Standby
1.为了保证NameNode的高可用,Hadoop2.x版本中引入了ZooKeeper解决单点故障问题,使用ZooKeeper完成Hadoop集群的选主以及主备切换。主被称为Active,备被称为standby。
2.Standby NameNode 的内存元数据和Active NameNode的内存元数据一模一样,当Active宕机时可以随时顶替成为新的Active.
3.Standby NameNode的磁盘元数据和Active NameNode的磁盘元数据是不一样的,因为谁是Active谁才会在磁盘中写入元数据,并实时写入QJM。
4.DataNode 需要同时向所有的NameNode汇报自己的心跳,主要包含资源情况和文件块与DataNode的映射。
5.Standby NameNode需要对元数据进行压缩合并,为了方便快速的恢复元数据,具体如下:
a.时间维度:默认一小时合并一次
b.操作维度:默认100W合并一次
c.维度检查:默认1分钟执行一次(检查到了1小时没,有没有到100W次)
6.合并后的文件叫做fsimage,例如fsimage_00000000034,合并后Standby会通知Active拷贝走合并文件
QJM(小型分布式文件系统,最少三台构建为集群环境,自己内部实现了PaxOS算法)
1.元数据得到命名为edits,分为正在进行中的和已生成的,具体如下。
a.正在进行中的文件叫做edits_inprogress_00000000071
b.已完成的文件叫做edits_00000000000_ 00000000019 edits_00000000020_00000000034
edits_00000000035_00000000070
(序号表示的是正整数的递增,一个数代表一次操作)
2.元数据默认2分钟生成一次,当客户上传文件时,元数据实时写入内存与inprogress文件,2分钟时inprogress文件会被分割为已完成的文件,新的inprogress文件继续写入。
如果整个集群宕机,重启集群后,恢复数据如下:
1.先将本地fsimage文件读入内存
2.再将QJM中大于fsimage编号的edits文件读入内存
3.再将QJM中最大编号的edits_inprogress文件读入内存
4.等待所有DataNode心跳
即可对外服务
DataNode
1.NameNode和DataNode时主从关系,Client直接和DataNode建立连接完成文件的上传下载
2.默认每3s发送一次心跳至所有NameNode,心跳中包含了节点剩余资源情况以及当前节点的所有文件块信息
3.当DataNode宕机时,(NameNode根据未收到心跳的时间统计,默认是10分30秒),部分文件块已无法满足集群默认3份副本数,NameNode会让其他资源充足的节点进行拷贝
10分是 2*5min
30秒是 3s*10
ZooKeeper
1.解决Hadoop集群单点故障的问题,帮助选主,以及主备切换(Active和 Standby主备关系)
2.NameNode向ZooKeeper注册临时Znode,谁先注册成功谁就是主,Standby监听Active
3.当Active宕机时,Standby通过监听机制得知重新注册为Active,Active重启后降级为Standby
4.当集群发生脑裂现象时(Active是假宕机,比如网络波动),Zookeeper先通过ZKFC调用转换为Standby 的方法,调用失败(转换失败)时,Zookeeper会根据配置文草中配置的解决方案,例如ssh登录至当前机器将其进程杀死。
Federation(联邦机制)

1.联邦机制是为了解压NaemNode 压力问题,防止NaemNode出现 OOM(内存溢出异常)
2.底层 DataNode公用,上层 NameNode是联邦的,解决了NameNode的请求压力问题
3.DataNode底层磁盘存储格式是按照NameNode的BlockPoollD构建目录分别存储的,心跳也是只汇报对应的块池文件块信息
HDFS的读取流程
琐碎零散信息
1.HDFS不要上传小文件信息,假如小文件上传的太多,会造成NameNode的元数据都比都比文件内容多,造成元数据爆炸,NameNode OOM,可以将小文件打包成一份上传。
2.HDFS可以把元数据存到客户端,或者是遍历服务器,或者存放在专门存放元数据的服务器(映射的服务器),前两者不好。
3.文件经过传输很有可能会丢失,可以使用MD5加密来验证文件是否丢失。
4.文件的底层是字节,分割后放入一个一个数组中,分别上传,然后根据索引合并。
5.当NameNode的元数据过多时,可以使用联邦机制,搭建多套主备模式,但这无法从根本上解决。















 5362
5362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









