






在机器学习中,Transformer是一种强大的神经网络模型,特别适用于处理序列数据,如自然语言处理任务。Transformer模型由编码器(Encoder)和解码器(Decoder)组成,我将首先详细解释编码器的工作原理。
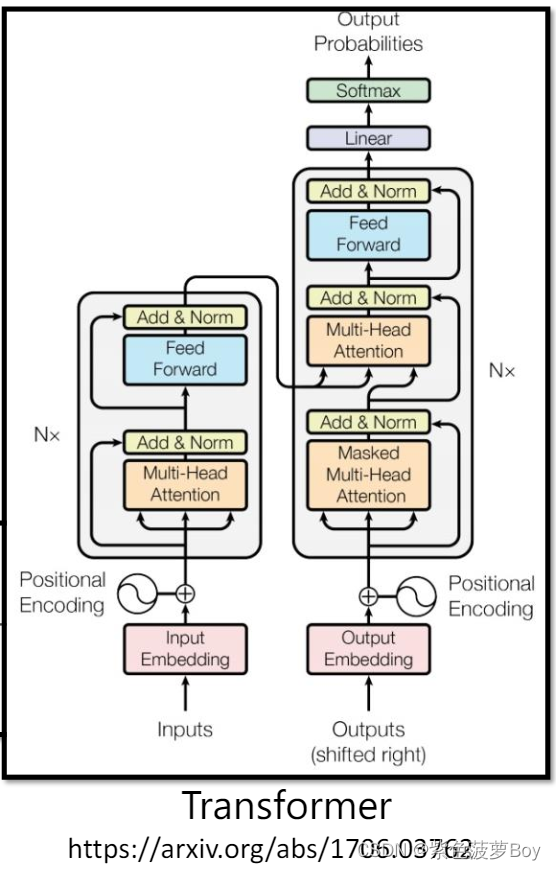
编码器是Transformer模型的核心组件之一,它负责将输入序列转换为一系列高级表示,以捕捉输入序列中的语义和上下文信息。
编码器由多个相同的层堆叠而成,每个层都由两个子层组成:多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Neural Network)。
-
多头自注意力机制:这是编码器中的关键部分。它通过计算输入序列中各个位置之间的依赖关系,为每个位置生成一个上下文相关的表示。多头自注意力机制包括以下步骤:
- 输入序列的每个位置通过三个线性变换(Q、K、V)映射到查询(Query)、键(Key)和值(Value)空间。
- 计算查询与键之间的相似度得分,并将其进行缩放和softmax操作,以获得每个查询与所有键的权重分布。
- 使用权重分布对值进行加权求和,得到每个查询的上下文向量。
- 通过拼接多个注意力头的结果,并通过线性变换得到最终的自注意力机制的输出。
-
前馈神经网络:这是编码器中的另一个重要组件。它对每个位置的表示进行独立的全连接层操作,以进行非线性变换和特征提取。前馈神经网络通常由两个线性变换和激活函数组成,例如ReLU。
在编码器中,每个子层都包含一个残差连接(Residual Connection)和层归一化(Layer Normalization)。残差连接允许原始输入直接流经子层,并与子层的输出相加,从而帮助信息传递和梯度流动。层归一化用于规范子层的输入,以避免训练过程中的梯度问题。
编码器通过堆叠多个相同的自注意力机制和前馈神经网络层,逐步提取输入序列的信息并生成更高级的表示。这些表示可以在许多下游任务中使用,如机器翻译、文本生成和语言理解等。
NOTE:编码器是Transformer模型的一个组件,它的输出可以被解码器使用,进一步生成目标序列或进行其他任务。
解码器是Transformer模型的另一个核心组件,它负责将编码器生成的高级表示转换为目标序列。解码器通过自注意力机制和编码器-解码器注意力机制来实现这一转换过程。
解码器由多个相同的层堆叠而成,每个层也由两个子层组成:多头自注意力机制和编码器-解码器注意力机制。
多头自注意力机制:与编码器中的自注意力机制类似,解码器中的自注意力机制用于计算目标序列中各个位置之间的依赖关系,以生成上下文相关的表示。它的操作步骤与编码器中的自注意力机制相同。
编码器-解码器注意力机制:解码器与编码器之间的注意力机制允许解码器在生成每个目标序列位置的表示时,对编码器的输出进行参考。具体而言,编码器-解码器注意力机制包括以下步骤:
解码器当前位置的查询(Query)通过线性变换映射到查询空间。
编码器输出的键(Key)和值(Value)分别通过线性变换映射到键空间和值空间。
计算查询与键之间的相似度得分,并将其进行缩放和softmax操作,以获得每个查询与所有键的权重分布。
使用权重分布对值进行加权求和,得到每个查询的上下文向量。
通过线性变换将上下文向量映射到更高维度的空间。
解码器中的每个子层也都包含残差连接和层归一化,与编码器类似。
在生成目标序列时,解码器通过自回归的方式逐个位置地生成序列元素,直到生成完整的目标序列。在每个位置,解码器将前一个位置的输出作为输入,并结合自注意力机制和编码器-解码器注意力机制生成当前位置的表示。
NOTE:解码器还可以使用前馈神经网络层进行非线性变换和特征提取。
Transformer模型中的解码器使得模型能够生成与输入序列相关的输出序列,例如机器翻译任务中的目标语言句子。它的设计使得模型能够在保持上下文相关性的同时,逐步生成输出序列的每个元素。















 2564
2564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









