







文章目录
前言
如果你的Linux服务器突然负载暴增,告警短信频繁发送你的手机,如何在最短时间内找出Linux性能问题所在?来看下面的这篇博文,看它们通过十条命令在一分钟内对机器性能问题进行诊断。
一、概述
通过执行以下命令,可以在1分钟内对系统资源使用情况有个大致的了解

其中一些命令需要安装sysstat包,有一些由procps包提供。这些命令的输出,有助于快速定位性能瓶颈,检查出所有资源(CPU、内存、磁盘IO等)的利用率(utilization)、饱和度(saturation)和错误(error)度量,也就是所谓的USE方法。
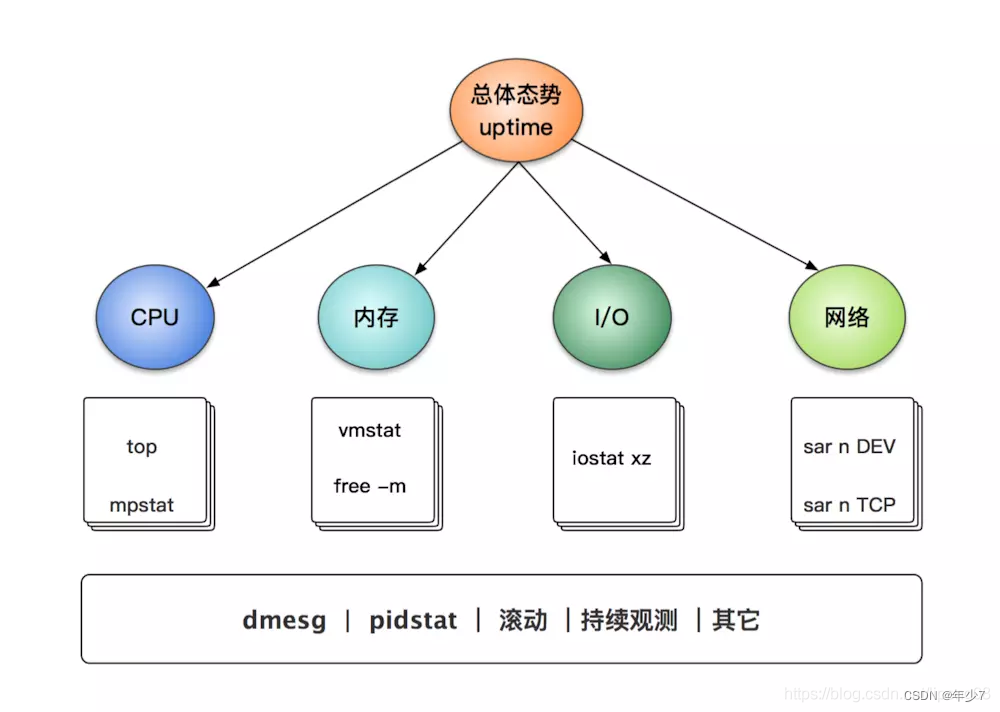
下面我们来逐一介绍下这些命令,有关这些命令更多的参数和说明,请参照命令的用法。
1.1 uptime
[root@matrix01 ~]# uptime
10:14:15 up 134 days, 15:02, 13 users, load average: 13.90, 14.59, 13.80
当前用户数目以及最近1分钟,5分钟以及15分钟的系统平均负载。系统平均负载指的是处于runnable(运行进程或者就绪进程)或者uninterruptable(不可中断的等待进程)状态的平均的进程数目。

上面的这个例子表明负载在不断上升,因为最近1分钟的平均负载(13.90)大于最近15分钟的平均负载(13.80)。
- ① 这个命令可以快速查看机器的负载情况。在Linux系统中,这些数据表示等待CPU资源的进程和阻塞在不可中断IO进程(进程状态为D)的数量。这些数据可以让我们对系统资源使用有一个宏观的了解。
- ② 命令的输出分别表示1分钟、5分钟、15分钟的平均负载情况。通过这三个数据,可以了解服务器负载是在趋于紧张还是区域缓解。如果1分钟平均负载很高,而15分钟平均负载很低,说明服务器正在命令高负载情况,需要进一步排查CPU资源都消耗在了哪里。反之,如果15分钟平均负载很高,1分钟平均负载较低,则有可能是CPU资源紧张时刻已经过去。
- ③ 上面图片例子中的输出,可以看见最近1分钟的平均负载非常高,且远高于最近15分钟负载,因此我们需要继续排查当前系统中有什么进程消耗了及占用了大量的资源。可以通过下文将会介绍的vmstat、mpstat等命令进一步排查。
1.2 dmesg丨tail
该命令会输出系统日志的最后10行,有些错误可能会报告出来。
示例中的输出,可以看见一次内核的oom kill和一次TCP丢包。这些日志可以帮助排查性能问题。千万不要忘了这一步。
[root@matrix01 ~]# dmesg|tail
[11600577.911527] beegfs: enabling unsafe global rkey
[11601115.782482] beegfs: enabling unsafe global rkey
[11603309.802755] beegfs: enabling unsafe global rkey
[11603480.008089] beegfs: enabling unsafe global rkey
[11603480.254171] beegfs: enabling unsafe global rkey
[11603480.685068] beegfs: enabling unsafe global rkey
[11603481.828464] beegfs: enabling unsafe global rkey
[11603482.240611] beegfs: enabling unsafe global rkey
[11604539.680715] beegfs: enabling unsafe global rkey
[11605122.279650] beegfs: enabling unsafe global rkey

1.3 vmstat 1
[root@matrix01 ~]# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
7 0 0 17147716 1908 78268800 0 0 0 53 0 0 15 6 79 0 0
11 0 0 17010680 1908 78270592 0 0 0 1484 89765 79693 15 6 79 0 0
24 0 0 16581568 1908 78270832 0 0 0 2848 106242 105007 22 10 68 0 0
23 0 0 16270556 1908 78269624 0 0 0 2336 131197 178975 27 12 61 0 0
9 0 0 16156524 1908 78273424 0 0 0 1604 129154 127436 40 13 47 0 0
16 0 0 15864848 1908 78275408 0 0 0 2880 122037 131268 27 12 61 0 0
4 0 0 15695844 1908 78275112 0 0 0 3360 138485 148813 14 8 78 0 0
5 0 0 15740768 1908 78275168 0 0 0 2176 108877 154865 10 5 84 0 0
8 0 0 15737108 1908 78274408 0 0 0 2808 93849 91389 10 5 85 0 0
6 0 0 15747440 1908 78275368 0 0 0 1860 92933 88750 9 5 86 0 0
7 0 0 15695372 1908 78275552 0 0 0 1280 93294 110368 7 5 88 0 0
9 0 0 15727928 1908 78277208 0 0 0 2912 114428 163776 15 7 77 0 0
11 0 0 15730748 1908 78277264 0 0 0 1780 100517 91527 13 8 80 0 0
16 0 0 15723544 1908 78276048 0 0 0 1652 84046 69151 17 7 76 0 0
24 0 0 15611072 1908 78277040 0 0 0 2892 108346 106202 25 11 65 0 0
11 0 0 15794508 1908 78276616 0 0 0 1832 128752 202478 23 11 67 0 0
15 0 0 15799304 1908 78276512 0 0 0 1428 90940 79760 14 6 80 0 0
7 0 0 15857088 1908 78276752 0 0 0 2704 102835 92594 20 8 71 0 0
33 0 0 15825696 1908 78276808 0 0 0 1860 124716 125094 33 13 54 0 0
25 0 0 16090488 1908 78268416 0 0 0 1760 152010 206816 38 14 48 0 0
13 0 0 16411980 1908 78268272 0 0 0 2792 101803 108018 20 10 70 0 0
5 0 0 16483148 1908 78269744 0 0 0 1928 99747 97305 10 6 84 0 0
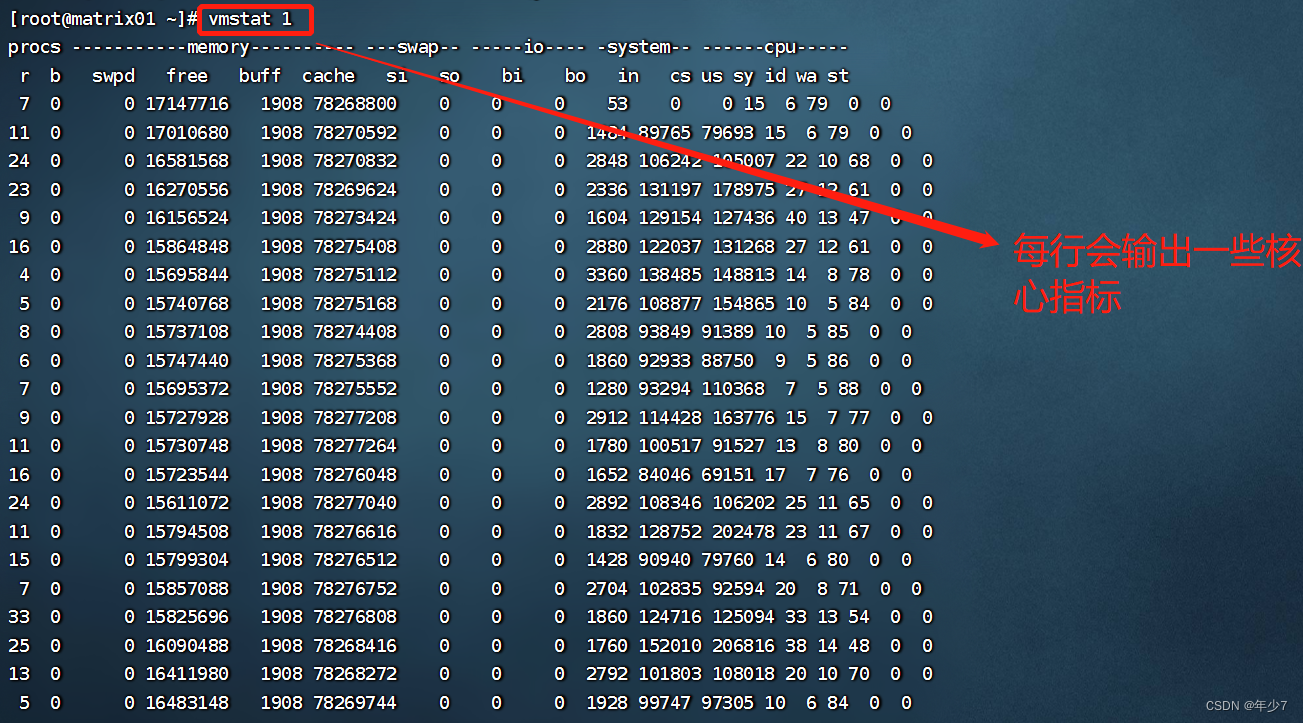
vmstat(8) 命令: 每行会输出一些系统核心指标,这些指标可以让我们更详细的了解系统状态。后面跟的参数1,表示每秒输出一次统计信息,表头提示了每一列的含义,这几介绍一些和性能调优相关的列:
- ① r:等待在CPU资源的进程数。这个数据比平均负载更加能够体现CPU负载情况,数据中不包含等待IO的进程。如果这个数值大于机器CPU核数,那么机器的CPU资源已经饱和。
- ② free:系统可用内存数(以千字节为单位),如果剩余内存不足,也会导致系统性能问题。下文介绍到的free命令,可以更详细的了解系统内存的使用情况。
- ③ si, so:交换区写入和读取的数量。如果这个数据不为0,说明系统已经在使用交换区(swap),机器物理内存已经不足。
- ④ us, sy, id, wa, st:这些都代表了CPU时间的消耗,它们分别表示用户时间(user)、系统(内核)时间(sys)、空闲时间(idle)、IO等待时间(wait)和被偷走的时间(stolen,一般被其他虚拟机消耗)。
上述这些CPU时间,可以让我们很快了解CPU是否出于繁忙状态。一般情况下,如果用户时间和系统时间相加非常大,CPU出于忙于执行指令。如果IO等待时间很长,那么系统的瓶颈可能在磁盘IO。
示例命令的输出可以看见,大量CPU时间消耗在用户态,也就是用户应用程序消耗了CPU时间。这不一定是性能问题,需要结合r队列,一起分析。
- ⑤ 简单总结几个注意点:
r列:代表运行的进程数目(就绪或者运行),很大表明工作量很多;
memeory列可以根据free -m的结果进行分析;
si和so:如果它的值非0,表明内存不够用,交换分区起用了;
us,sy等:代表user,sys,idle,wait,以及stole time。 user time很大表明用户任务繁忙,wait很大表明磁盘I/O时间很长,这个时候cpu一般是空闲的(需要阻塞等待),它类似于idle,但是不同的是,cpu处于等待I/O而无法执行。
1.4 mpstat-P ALL 1
- ① 该命令可以显示每个CPU的占用情况,如果有一个CPU占用率特别高,那么有可能是一个单线程应用程序引起的。
- ② mpstat关注的是每个cpu processor(
注意这个是逻辑核心)的情况,可帮助查看各个cpu逻辑核是否负载均衡。例如如果只有一个cpu繁忙,那可判断属于单进程的程序。
[root@matrix01 ~]# mpstat -P ALL 1
Linux 3.10.0-957.27.2.el7.x86_64 (matrix01) 2022年12月08日 _x86_64_ (48 CPU)
10时25分11秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10时25分12秒 all 11.98 0.21 7.18 0.00 0.00 0.25 0.00 0.00 0.00 80.38
10时25分12秒 0 8.25 0.00 6.19 0.00 0.00 0.00 0.00 0.00 0.00 85.57
10时25分12秒 1 4.08 0.00 5.10 0.00 0.00 0.00 0.00 0.00 0.00 90.82
10时25分12秒 2 6.19 0.00 4.12 0.00 0.00 0.00 0.00 0.00 0.00 89.69
10时25分12秒 3 16.16 0.00 10.10 0.00 0.00 0.00 0.00 0.00 0.00 73.74
10时25分12秒 4 13.13 0.00 3.03 0.00 0.00 0.00 0.00 0.00 0.00 83.84
10时25分12秒 5 9.18 0.00 7.14 0.00 0.00 0.00 0.00 0.00 0.00 83.67
10时25分12秒 6 14.43 0.00 8.25 0.00 0.00 0.00 0.00 0.00 0.00
[...]
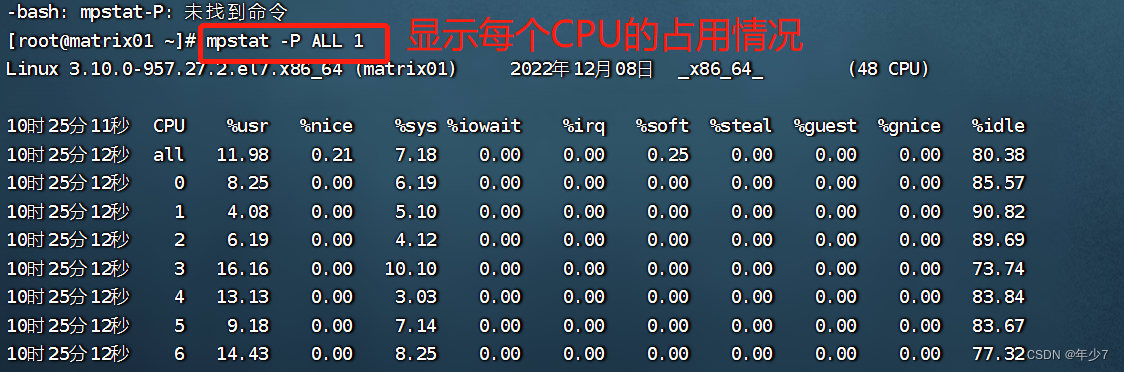
③ 例如我们的机器有2个NUMA核心,一个上面有3个物理核心,每个物理核包括2个逻辑核心。因此,从mpstat来看一共是2 * 3 * 2 = 16个逻辑核心,cpu利用率最高为1200%。
1.5 pidstat 1
[root@matrix01 ~]# pidstat 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
07:41:02 PM UID PID %usr %system %guest %CPU CPU Command
07:41:03 PM 0 9 0.00 0.94 0.00 0.94 1 rcuos/0
07:41:03 PM 0 4214 5.66 5.66 0.00 11.32 15 mesos-slave
07:41:03 PM 0 4354 0.94 0.94 0.00 1.89 8 java
07:41:03 PM 0 6521 1596.23 1.89 0.00 1598.11 27 java
07:41:03 PM 0 6564 1571.70 7.55 0.00 1579.25 28 java
07:41:03 PM 60004 60154 0.94 4.72 0.00 5.66 9 pidstat
07:41:03 PM UID PID %usr %system %guest %CPU CPU Command
07:41:04 PM 0 4214 6.00 2.00 0.00 8.00 15 mesos-slave
07:41:04 PM 0 6521 1590.00 1.00 0.00 1591.00 27 java07:41:04 PM 0 6564 1573.00 10.00 0.00 1583.00 28 java
07:41:04 PM 108 6718 1.00 0.00 0.00 1.00 0 snmp-pass
07:41:04 PM 60004 60154 1.00 4.00 0.00 5.00 9 pidstat
pidstat命令输出进程的CPU占用率,该命令会持续输出,并且不会覆盖之前的数据,可以方便观察系统动态。如上的输出,可以看见两个JAVA进程占用了将近1600%的CPU时间,既消耗了大约16个CPU核心的运算资源。
1.6 iostat-xz 1
[root@matrix01 ~]# iostat -xz 1
Linux 3.10.0-957.27.2.el7.x86_64 (matrix01) 2022年12月08日 _x86_64_ (48 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
14.73 0.05 5.81 0.04 0.00 79.38
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 8.55 0.00 2.87 2.87 0.00 2.81 0.00
sdc 0.00 0.00 0.00 23.95 0.01 146.60 12.24 0.00 0.10 0.18 0.10 0.06 0.13
sdb 0.00 1.77 0.92 149.06 16.80 2376.93 31.92 0.04 0.28 0.48 0.28 0.05 0.69
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 5.08 0.00 0.55 0.55 0.00 0.55 0.00
dm-1 0.00 0.00 0.00 0.07 0.00 0.30 8.67 0.00 0.36 0.43 0.36 0.34 0.00
dm-2 0.00 0.00 0.00 0.07 0.00 0.30 8.68 0.00 0.36 0.60 0.36 0.36 0.00
dm-4 0.00 0.00 0.00 0.07 0.00 0.30 8.68 0.00 0.38 1.00 0.38 0.36 0.00
dm-5 0.00 0.00 0.00 0.00 0.01 0.00 7.87 0.00 48.63 60.35 19.54 14.22 0.00
dm-6 0.00 0.00 0.00 0.30 0.00 50.30 334.78 0.01 24.32 4.83 24.35 0.32 0.01
dm-7 0.00 0.00 0.00 0.30 0.00 50.30 334.88 0.01 24.33 5.75 24.36 0.32 0.01
dm-9 0.00 0.00 0.00 0.30 0.00 50.28 335.17 0.24 809.92 9.87 810.95 0.40 0.01
[...]
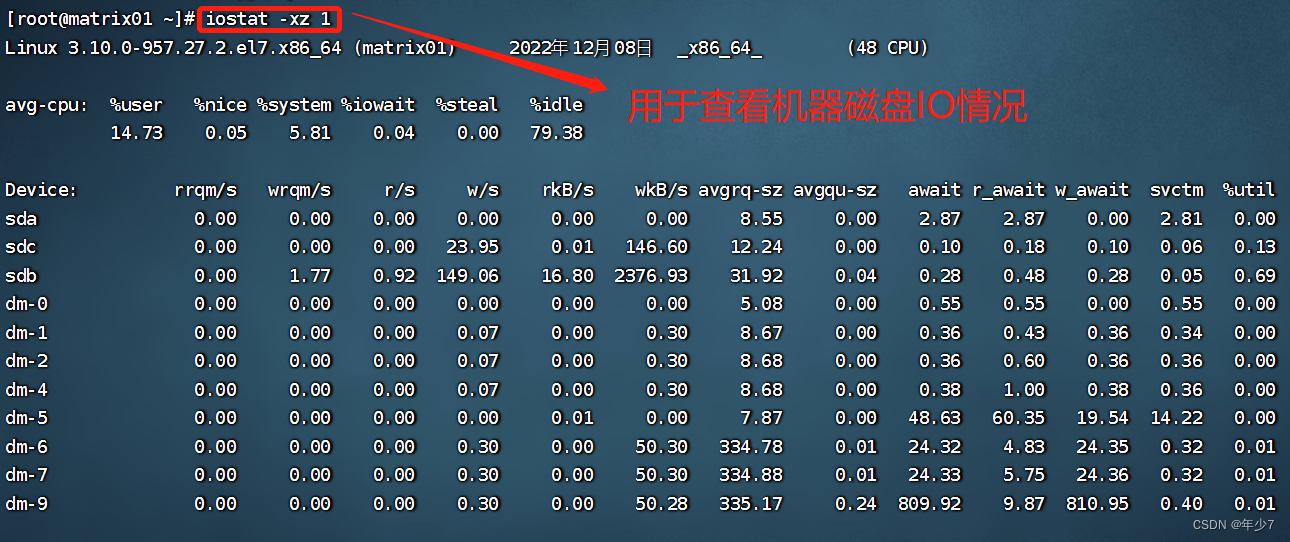
iostat命令主要用于查看机器磁盘IO情况。上面的数据太多列了,重点关注r/s, w/s, rMB/s, wMB/s, avgqu-sz, await, %util。
- ① r/s, w/s: 每秒读写设备的次数(可认为是随机读的次数),一般情况下随机读几百次硬盘就扛不住了;读写量过大,可能会引起性能问题。
- ② rMB/s, wMB/s: 每秒读写字节数;
- ③ avgqu-sz: 平均的I/O等待队列大小,如果大于0,表明有I/O在等待;
- ④ await:平均服务时间(包括等待以及服务的时间的总和);
- ⑤ %util:磁盘利用率,这个太有用了,如果利用率为100%,那么磁盘I/O基本上处于饱和状态。
1.7 free -m
free命令可以查看系统内存的使用情况,-m参数表示按照兆字节展示。
- ① 最后两列分别表示用于IO缓存的内存数,和用于文件系统页缓存的内存数。需要注意的是,第二行-/+ buffers/cache,看上去缓存占用了大量内存空间。这是Linux系统的内存使用策略,尽可能的利用内存,如果应用程序需要内存,这部分内存会立即被回收并分配给应用程序。因此,这部分内存一般也被当成是可用内存。
- ② 如果可用内存非常少,系统可能会动用交换区(如果配置了的话),这样会增加IO开销(可以在iostat命令中提现),降低系统性能。
- 这里free代表当前的空闲内存,还不到1个G。如果free很小,可能会导致进程申请内存失败.
[root@matrix01 ~]# free -m
total used free shared buff/cache available
Mem: 128365 36539 15190 4267 76635 82109
Swap: 0 0 0

注意: 对于本例子来说,系统依然有很多可用内存(虽然不是free)。如上例,buff/cache有76个G的样子,这些内存是临时的缓存(buff是块设备缓存,cache是文件系统page cache),可被回收。因此available列的数据有接近70个G。
1.8 sar -n DEV 1
[root@matrix01 ~]# sar -n DEV 1
Linux 3.10.0-957.27.2.el7.x86_64 (matrix01) 2022年12月08日 _x86_64_ (48 CPU)
10时39分27秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
10时39分28秒 cali55401735ffe 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10时39分28秒 cali2650cd35748 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10时39分28秒 cali13261eb8ab1 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10时39分28秒 veth3c2cfb28 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10时39分28秒 wsbbridge0 249.00 320.00 84.96 26.79 0.00 0.00 0.00
10时39分28秒 calied013e2ac86 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10时39分28秒 bond1 670.00 1228.00 129.66 843.07 0.00 0.00 0.00
10时39分28秒 cali1420e622636 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10时39分28秒 cali91e1b09f28d 6.00 9.00 3.07 0.99 0.00 0.00 0.00
10时39分28秒 calibae80c15b8e 9.00 7.00 0.71 1.33 0.00 0.00 0.00
10时39分28秒 cali05ea64682ab 0.00 0.00 0.00 0.00 0.00 0.00 0.00
10时39分28秒 calia1c5cdd6c44 2.00 2.00 0.17 0.15 0.00 0.00 0.00
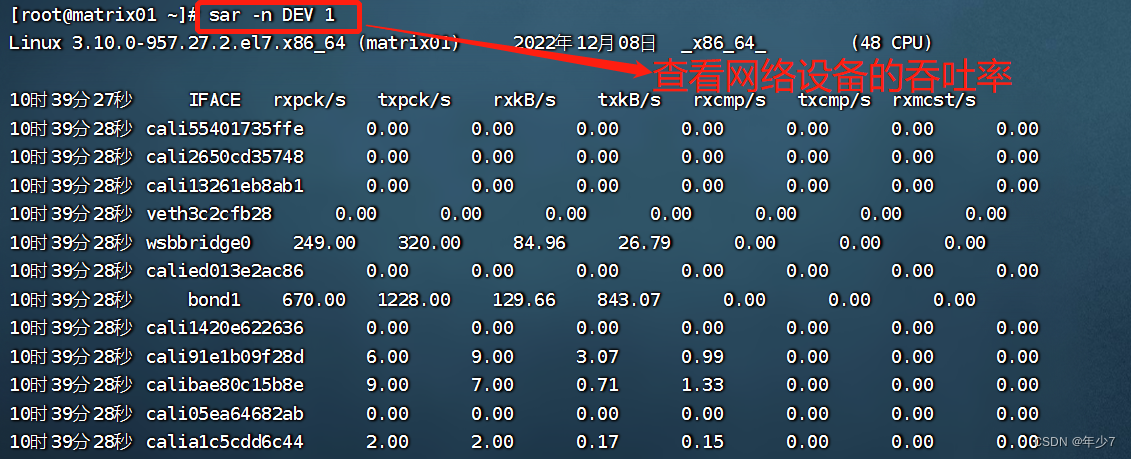
sar命令在这里可以查看网络设备的吞吐率。
在排查性能问题时,可以通过网络设备的吞吐量,判断网络设备是否已经饱和。
1.9 sar -n TCP,ETCP 1
[root@matrix01 ~]# sar -n TCP,ETCP 1
Linux 3.10.0-957.27.2.el7.x86_64 (matrix01) 2022年12月08日 _x86_64_ (48 CPU)
10时51分50秒 active/s passive/s iseg/s oseg/s
10时51分51秒 2.00 1.00 392.00 722.00
10时51分50秒 atmptf/s estres/s retrans/s isegerr/s orsts/s
10时51分51秒 0.00 1.00 0.00 0.00 1.00
10时51分51秒 active/s passive/s iseg/s oseg/s
10时51分52秒 5.00 1.00 433.00 870.00
10时51分51秒 atmptf/s estres/s retrans/s isegerr/s orsts/s
10时51分52秒 0.00 1.00 0.00 0.00 1.00
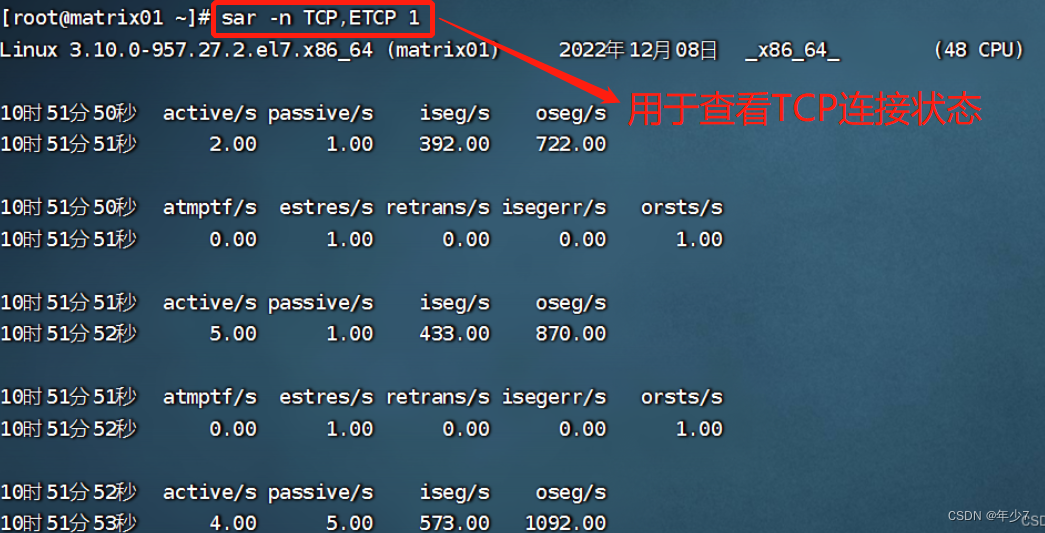
sar命令在这里用于查看TCP连接状态,其中包括:
- active/s:每秒本地发起的TCP连接数,既通过connect调用创建的TCP连接;
- passive/s:每秒远程发起的TCP连接数,即通过accept调用创建的TCP连接;
- retrans/s:每秒TCP重传数量;
TCP连接数可以用来判断性能问题是否由于建立了过多的连接,进一步可以判断是主动发起的连接,还是被动接受的连接。TCP重传可能是因为网络环境恶劣,或者服务器压力过大导致丢包。
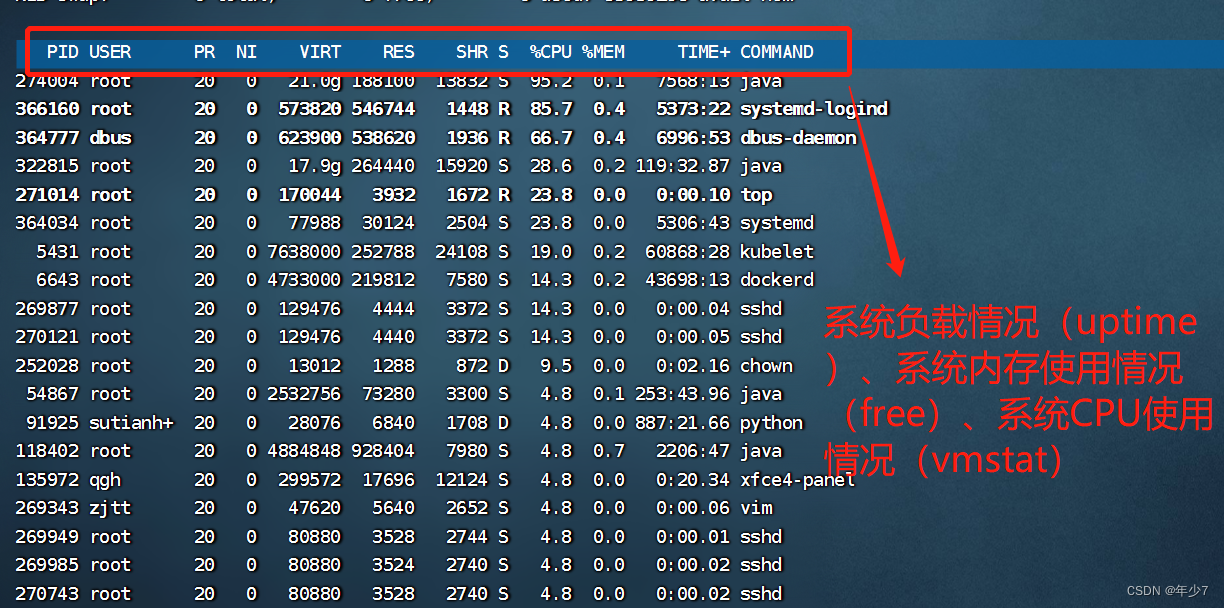
1.20 top
top命令包含了前面好几个命令的检查的内容: 比如系统负载情况(uptime)、系统内存使用情况(free)、系统CPU使用情况(vmstat)等。
- ① 因此通过这个命令,可以相对全面的查看系统负载的来源。同时,top命令支持排序,可以按照不同的列排序,方便查找出诸如内存占用最多的进程、CPU占用率最高的* 进程等。
- ② 但是,top命令相对于前面一些命令,输出是一个瞬间值,如果不持续盯着,可能会错过一些线索。这时可能需要暂停top命令刷新,来记录和比对数据。
- ③ 这是查看一个能查看多种指标的工具,现在先简单将它归为查看cpu的工具。它的自动刷新机制可能使得历史数据被清除。
[root@matrix01 ~]# top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
274004 root 20 0 21.0g 188100 13832 S 100.0 0.1 7566:49 java
366160 root 20 0 573820 546744 1448 R 97.7 0.4 5372:00 systemd-logind
364034 root 20 0 77992 30160 2504 R 47.5 0.0 5306:22 systemd
54620 admin 20 0 25.5g 1.3g 11656 S 38.7 1.1 48373:08 java
5431 root 20 0 7638000 252788 24108 S 31.8 0.2 60868:00 kubelet
34822 100 20 0 2066376 141916 2868 S 23.3 0.1 53434:21 beam.smp
6643 root 20 0 4733000 219812 7580 S 17.7 0.2 43697:52 dockerd
31882 root 20 0 5033120 60432 16508 S 15.1 0.0 10133:05 calico-node
364777 dbus 20 0 623900 538620 1936 S 11.1 0.4 6996:39 dbus-daemon
1 root 20 0 202380 14796 2704 R 10.8 0.0 17045:30 systemd
6632 root 20 0 9693536 124936 16312 S 10.2 0.1 14510:42 containerd
165148 qgh-ai 38 18 25832 9356 3460 S 9.5 0.0 688:44.65 python
91925 sutianh+ 20 0 28076 6840 1708 D 8.9 0.0 887:13.57 python
437246 root 20 0 29124 17824 908 D 6.9 0.0 0:25.82 chown
187497 root 20 0 134080 2892 1284 S 5.6 0.0 0:03.10 sshd
5386 dbus 20 0 65348 3216 1920 S 5.2 0.0 6409:25 dbus-daemon
二 总 结
排查Linux服务器性能问题还有很多工具,上面介绍的一些命令,可以帮助我们快速的定位问题。例如前面的示例输出,多个证据证明有JAVA进程占用了大量CPU资源,之后的性能调优就可以针对应用程序进行。















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









