






一、回归检验
使用均方误差(MSE:全称Mean Square Error),误差越小,精度越高,模型越好。
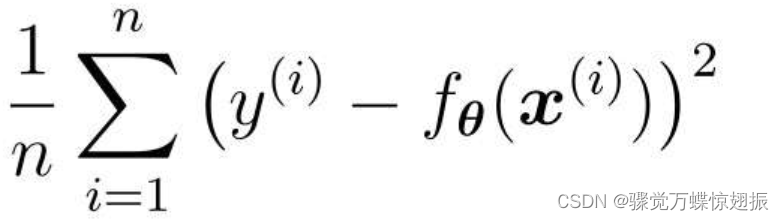
二、分类问题的验证
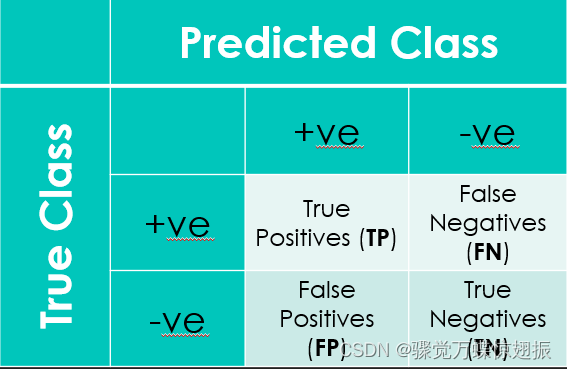
(一)整体精度
分类结果有四种
则分类的精度可被计算为
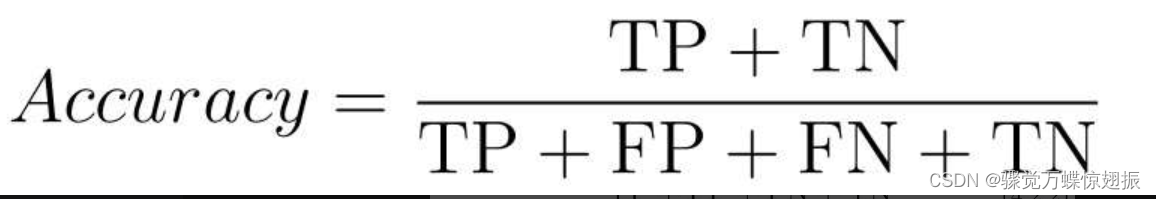
(二)精确率和召回率
设有100个数据,其中95个是Negative。那么,哪怕出现模型把数据全部分类为Negative的极端情况,Accuracy值也为0.95,也就是说模型的精度是95%。但不能说其为好模型。因此要引入其他指标。
1、精确率 Precision
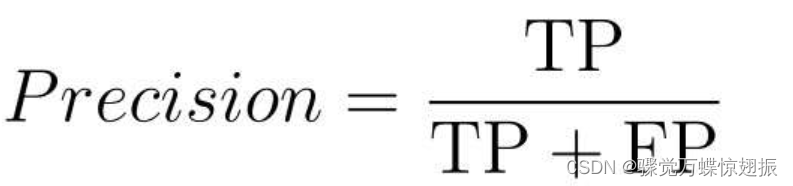
它的含义是在被分类为Positive的数据中,实际就是Positive的数据所占的比例。值越高,说明分类错误越少。Precision is the proportion of +ve predictions that are correct.
2、召回率 Recall

它的含义是在Positive数据中,实际被分类为Positive的数据所占的比例。这个值越高,说明被正确分类的数据越多。Recall is the proportion of actually +ve documents that are predicted correctly.
精确率和召回率都很高的模型就是一个好模型,但一般来说,精确率和召回率会一个高一个低,需要我们取舍。
(三)F值

该指标考虑到了精确率和召回率的平衡,也有很多人把F1值(F1-Score)的表达式写成下面这样:
![]()
F1值是精确率和召回率的调和平均值,且更接近两者中更低的那个。
除F1值之外,还有一个带权重的F值指标:
![]()
我们可以认为F值指的是带权重的F值,当权重为1时才是刚才介绍的F1值。
以TN为主来计算精确率和召回率的表达式是这样的:
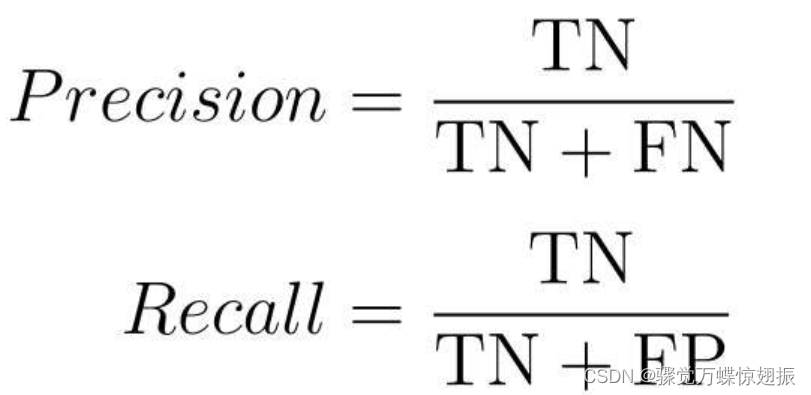
当数据不平衡时,使用数量少的那个会更好。
对于回归和分类,我们都可以这样来评估模型。
把全部训练数据分为测试数据和训练数据的做法称为交叉验证,交叉验证的方法中,尤为有名的是K折交叉验证。即:
● 把全部训练数据分为K份。
● 将K-1份数据用作训练数据,剩下的1份用作测试数据。
● 每次更换训练数据和测试数据,重复进行K次交叉验证。
● 最后计算K个精度的平均值,把它作为最终的精度。
假如我们要进行4折交叉验证,那么就会这样测量精度

三、正则化
(一)过拟合 overfitting
模型只能拟合训练数据的状态被称为过拟合,避免过拟合的方法有:
● 增加全部训练数据的数量
● 使用简单的模型
● 正则化
(二)正则化
如回归的目标函数为:
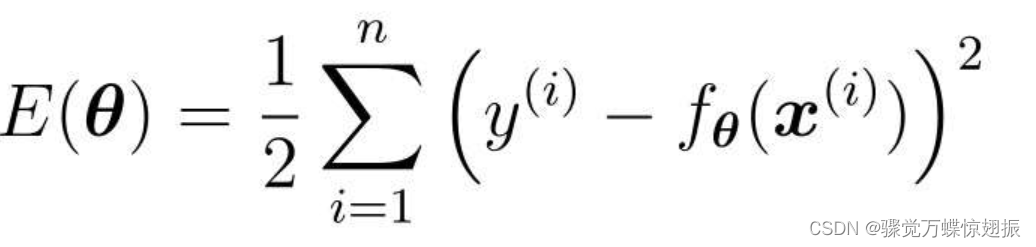
向这个目标函数增加下面这样的正则化项:
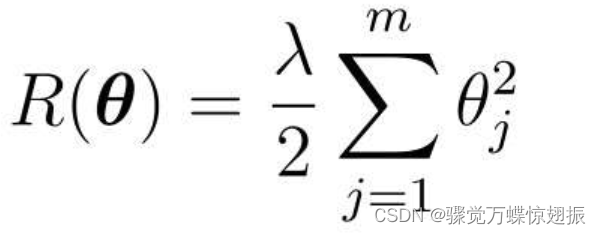
则得到
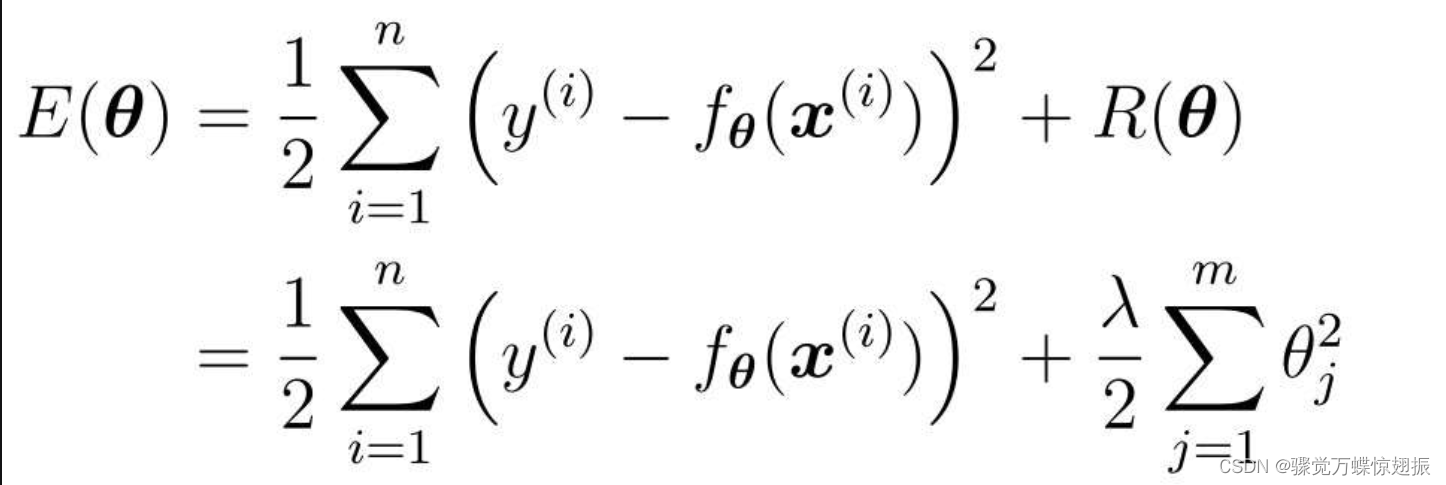
对这个新的目标函数进行最小化,这种方法就称为正则化。其中,m是参数的个数,j一般从1开始取,即一般来说不对θ0应用正则化,θ0这种只有参数的项称为偏置项。 λ是决定正则化项影响程度的正的常数,这个值需要我们自己来定。
正则化的效果如下:
首先把目标函数分成两个部分,C(θ)是本来就有的目标函数项,R(θ)是正则化项。
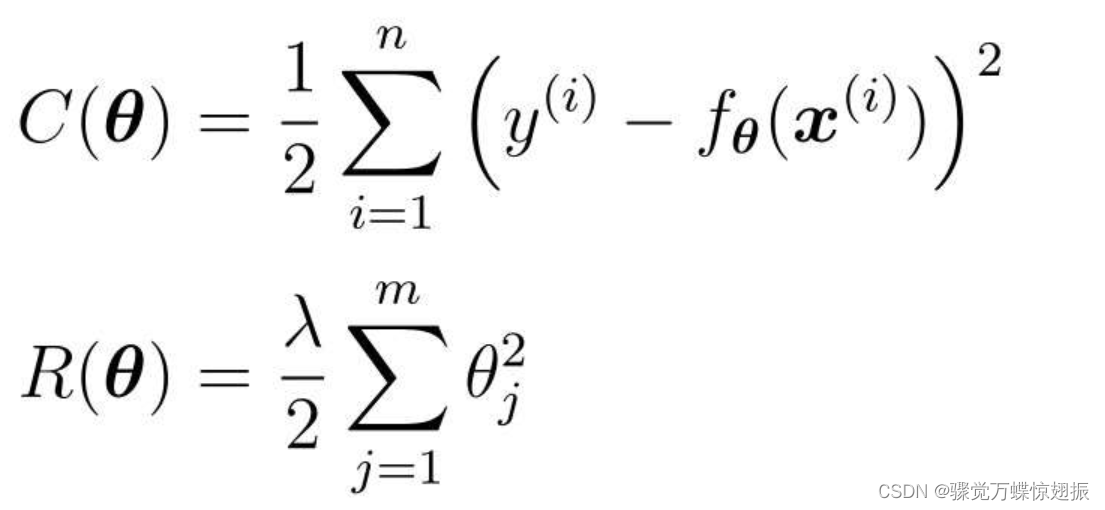
目标函数C(θ)在没有正则化项时的形状来看,θ1=4.5附近是最小值。R(θ)为过原点的简单二次函数。
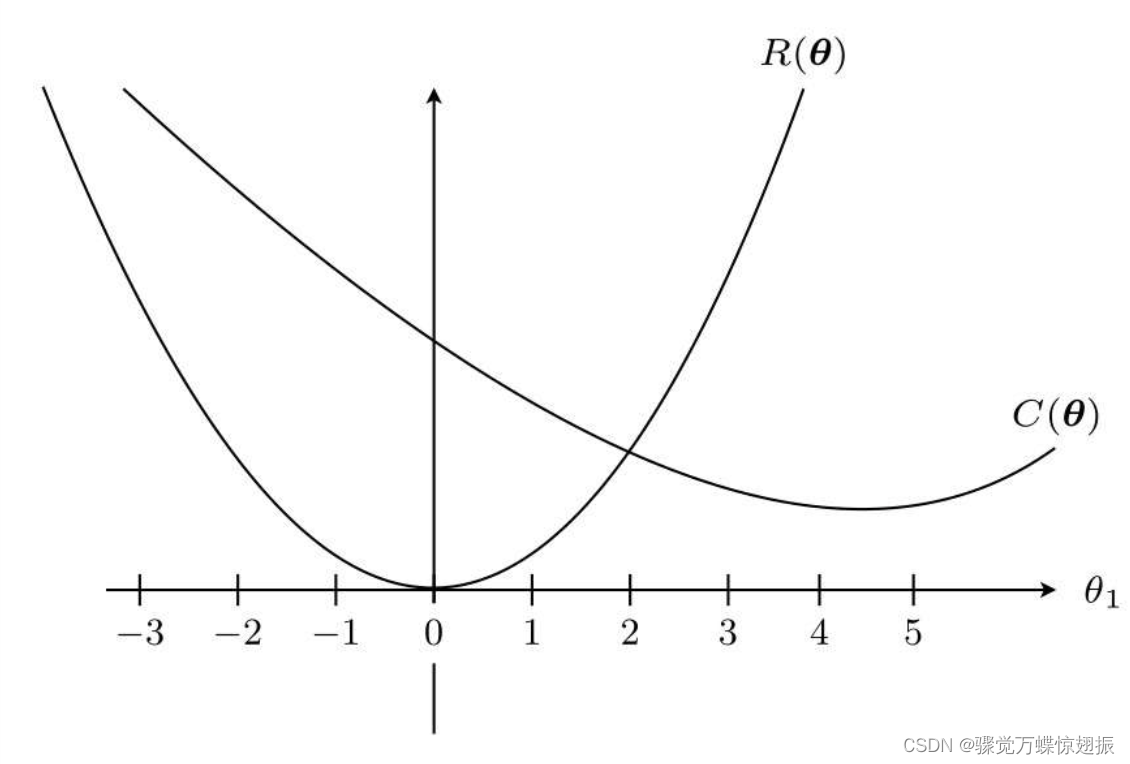
而实际的目标函数是这两个函数之和E(θ)=C(θ)+R(θ),图像如下,最小值是θ1=0.9。

与加正则化项之前相比,θ1更接近0。这就是正则化的效果。它可以防止参数变得过大,有助于参数接近较小的值。这正是通过减小不需要的参数的影响,将复杂模型替换为简单模型来防止过拟合的方式。
而为了防止参数的影响过大,训练时增加λ。λ为0,相当于不需要正则化;λ越大,约束函数越厉害。
(三)分类的正则化
![]()
反转符号是为了将最大化问题替换为最小化问题,在更新参数时就要像回归一样,与微分的函数的符号反方向移动才行。
(四)包含正则化项的表达式的微分
新的目标函数如下:
![]()
要对其进行微分,前者在回归时已求过微分形式,为:
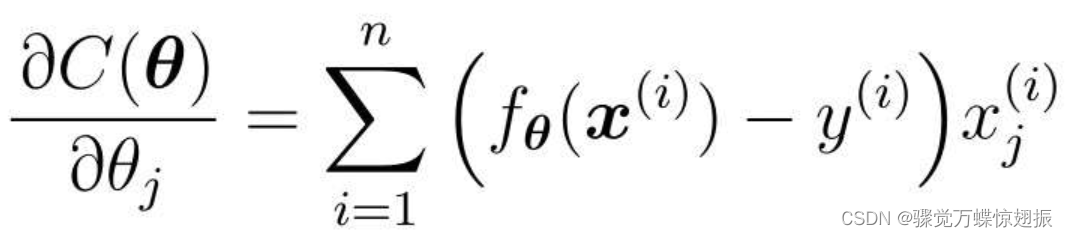
对正则化部分的微分为:


最终的微分结果为

代入到参数更新表达式里去则为:

区分两种情况是因为,一般不对θ0应用正则化,R(θ)对θ0微分的结果为0,所以j=0时表达式中的λθj就消失了。
逻辑回归的流程也是一样的。原来的目标函数是C(θ),正则化项是R(θ),现在对E(θ)进行微分。
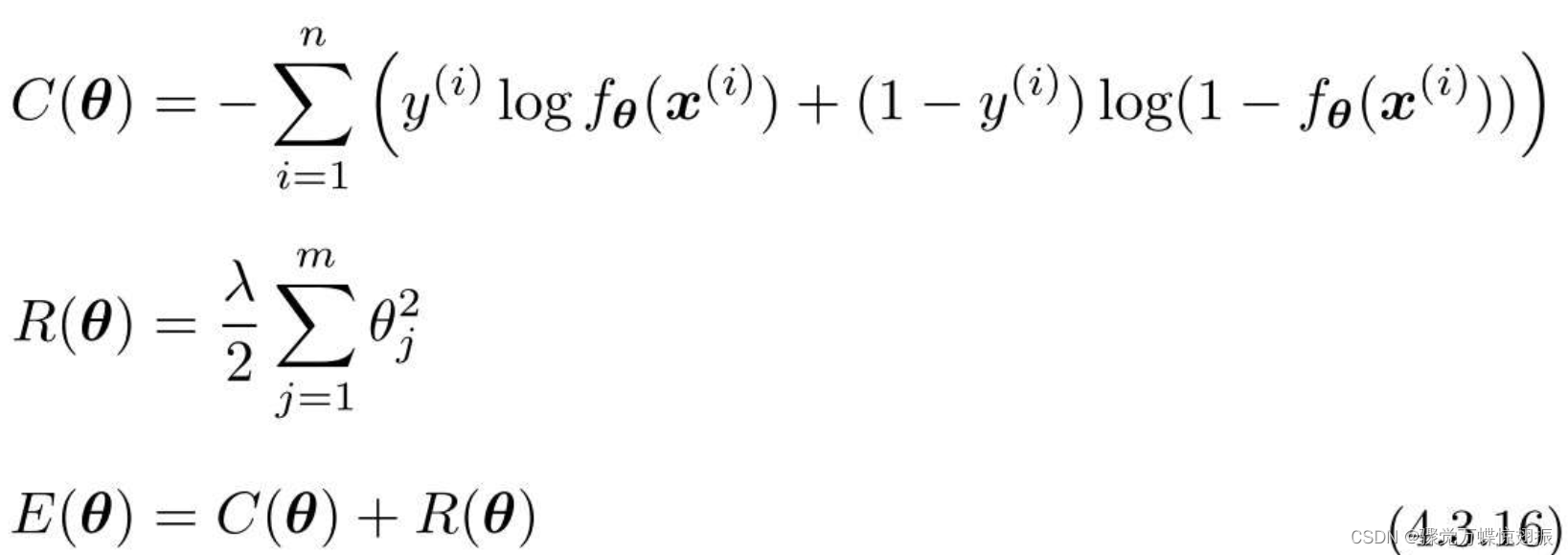
得出
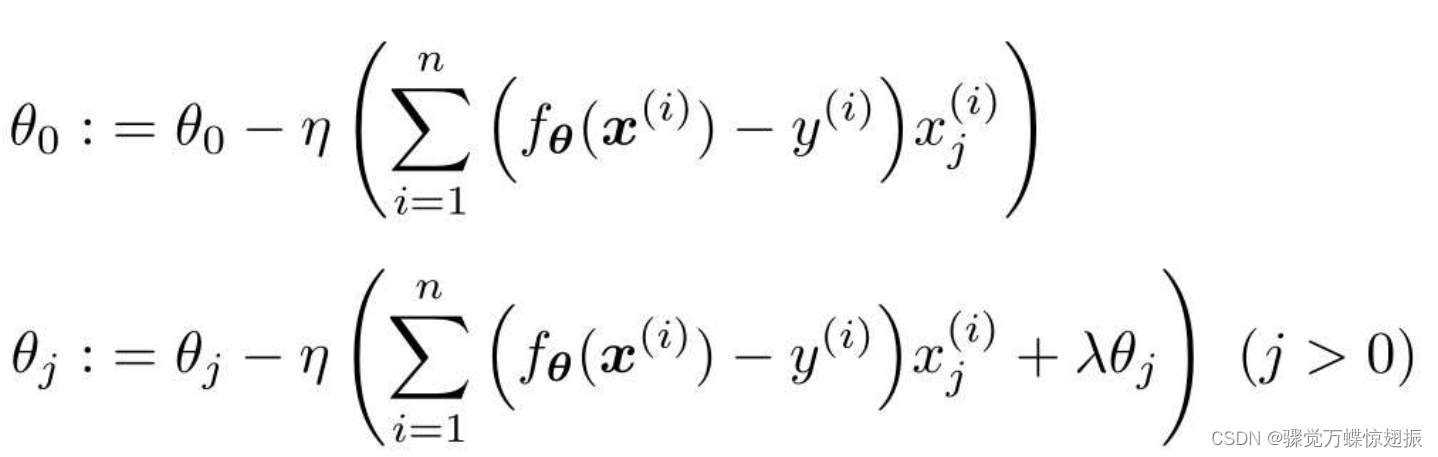
这种方法叫L2正则化,还有L1正则化方法,它的正则化项R是这样的:

L1正则化的特征是被判定为不需要的参数会变为0,从而减少变量个数。而L2正则化不会把参数变为0。L2正则化会抑制参数,使变量的影响不会过大,而L1会直接去除不要的变量。
四、学习曲线
(一)欠拟合 underfitting
主要原因就是模型相对于要解决的问题来说太简单了
(二)区分过拟合和欠拟合的方法
如果模型过于简单,那么随着数据量的增加,误差也会一点点变大。换句话说就是精度会一点点下降。如下图:

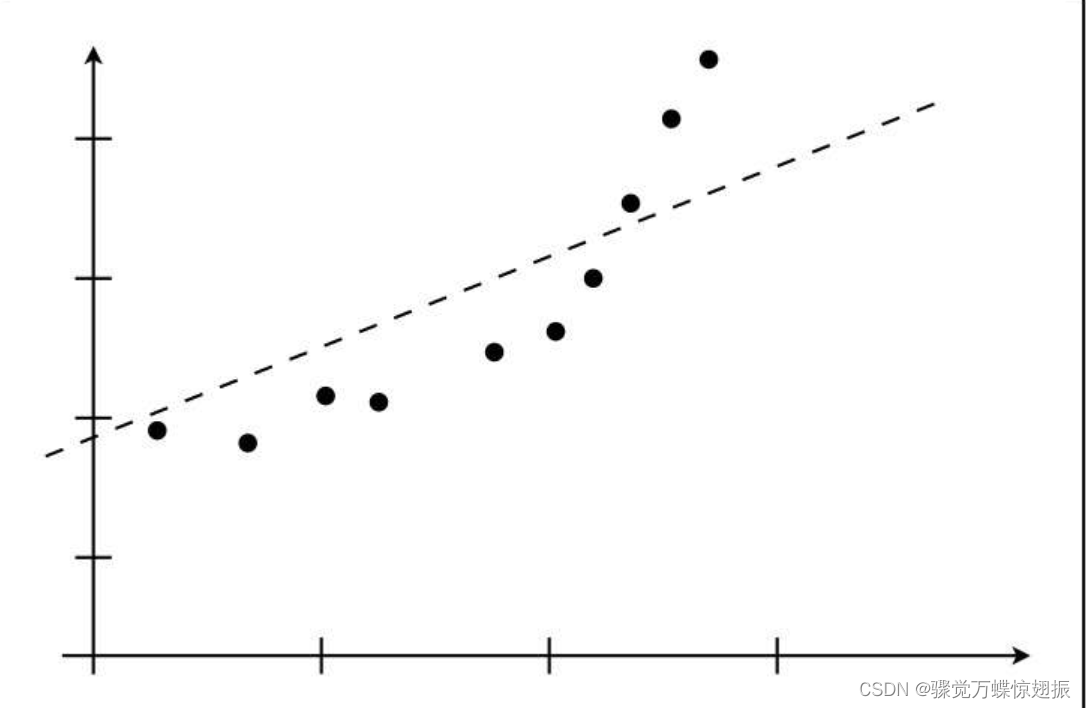
数据量为2时,可以完美拟合,误差为0;如果把10个数据全部训练,尽可能拟合数据,则误差会增大。
以数据的数量为横轴、以精度为纵轴,形状大致为:

假设还有测试数据,我们用这些测试数据来评估各个模型,之后用同样的方法求出精度,并画成图

将两份数据的精度用图来展示后,如果是这种形状,就说明出现了欠拟合的状态,也叫作高偏差。
图中需要注意的点在这里

而在过拟合的情况下,图是这样的。也叫作高方差。随着数据量的增加,使用训练数据时的精度一直很高,而使用测试数据时的精度一直没有上升到它的水准。

像这样展示了数据数量和精度的图称为学习曲线。
在知道模型精度低,却不知道是过拟合还是欠拟合的时候,可通过学习曲线判断,接下来采取相应的对策以便改进模型。















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









