






使用python爬虫获取猫眼热榜top100
需先安装 python 的 requests 库
windows 系统可在命令行中使用 pip 下载,下载命令为 pip install requests
先导入 python 库
import re
import json// 在新版的 python 中自带 json,如没有则需自行下载,下载命令为 pip install json
import time
import requests
form requests.exceptions import RequestException—————–正文 —————————————————------------------------------------------------------
// 定义获取首页的函数
def get_one_page(url):
try:
// 这里的 headers 的获取方法自行百度,这里就不多赘述了
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'
}
response = requests.get(url,headers=headers)
// 这里判断网页返回值,若为 200 则网页正常打开
if response.status_code == 200:
return response.text
return None
except RequestException:
return None这段代码使用 requests 库发送一个 GET 请求到指定的 URL,并返回响应的文本内容。如果请求失败,函数会捕捉 RequestException 异常并返回 None。
// 使用正则表达式从 HEML 文本中提取电影信息
def parse_one_page(html):
"""
打开源码发现每个热门电影的信息都在 <dd></dd > 之间,据此写出获取电影名称、主演、排名等信息的正则表达式,若不懂正则表达式建议先去学习
"""
pattern = re.compile(
'<dd>.*?board-index.*?>(.+?)</i>.*?data-src="(.*?)".*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S
)
items = re.findall(pattern,html)
for item in items:
"""
使用yield 让返回的数据更加顺眼
"""
yield {
'index' : item[0],
'image' : item[1],
'title' : item[2].strip(),
'actor' : item[3].strip()[3:],
'time' : item[4].strip()[5:],
'score' : item[5] + item[6]
}这段代码使用正则表达式获取电影具体信息,并调用下方的 write_to_file 函数写出为 txt 文件
// 将结果输出为 txt 文件的函数
def write_to_file(content):
print('789')
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False)+'\n')// 定义 main 函数
def main(offset):
url = 'http://maoyan.com/board/4?offset='+str(offset))// 打开猫眼 top100 可发现每 10 个热榜网址末尾数字递增 10
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)主函数构造 url 然后使用各个函数达成爬虫效果
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)以下是输出的 txt 效果
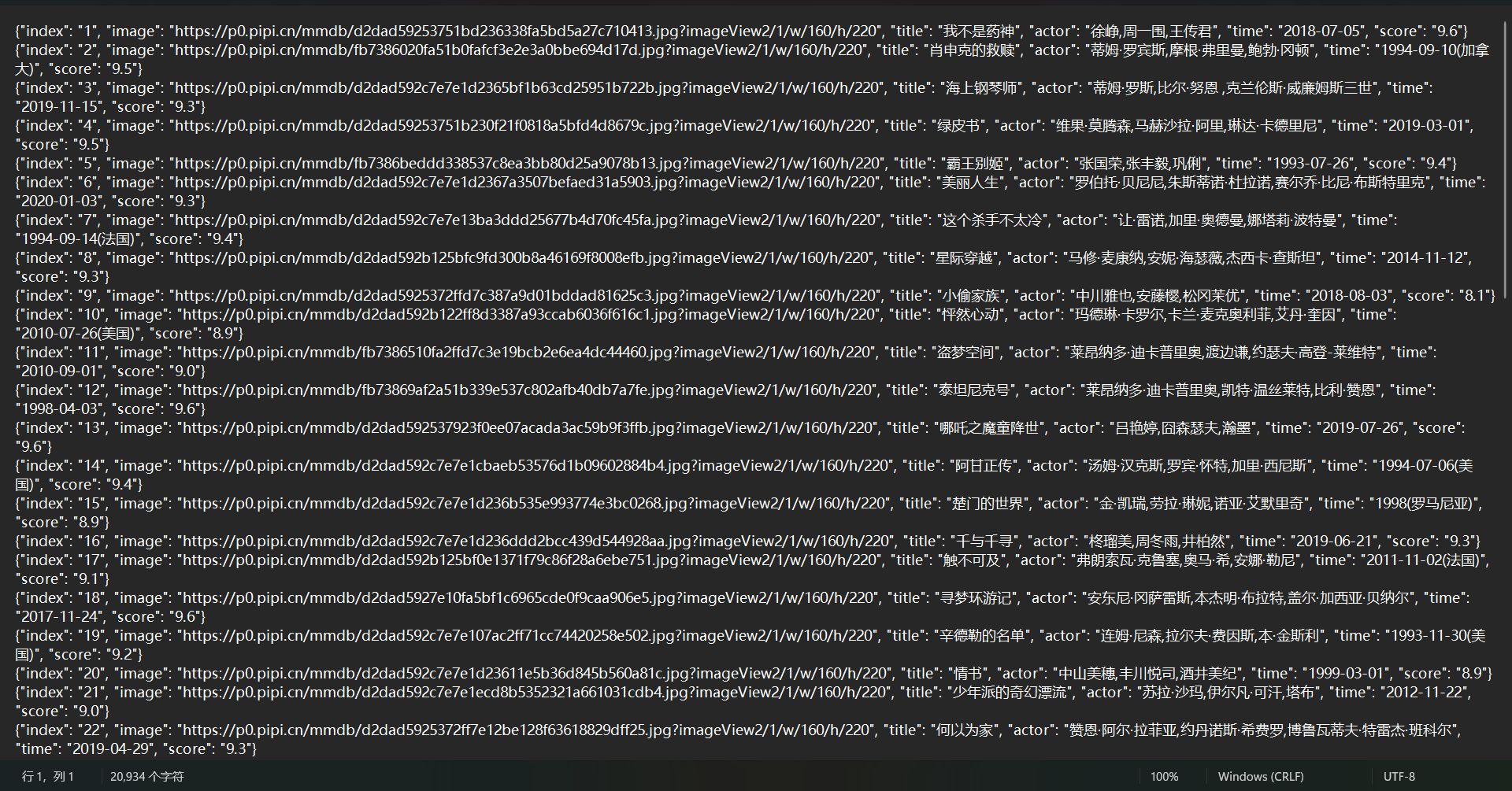
















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











