







K-近邻算法(K-Nearest Neighbors,KNN)是一种基本的分类和回归方法,它的基本思想是基于已有的样本数据集,对新的未知样本进行预测。对于一个未知的数据样本,k-近邻算法会在已有的样本数据集中找到与样本距离最近的k个数据点,然后选择这k个数据点中出现次数最多的标签作为最后的预测结果。
本次算法的数据集我用的是鸢尾花数据集,共有150条数据。
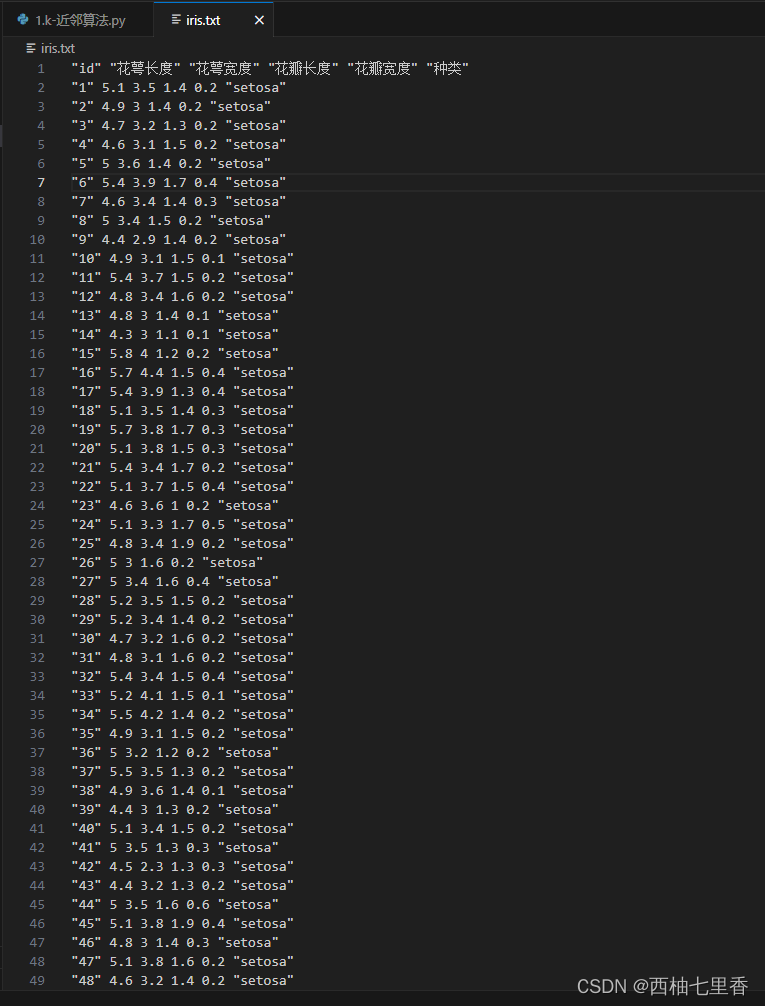
具体python代码如下:
from numpy import *
import math
# "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
temp = []
with open("./iris.txt", "r") as f:
for line in f.readlines():
line = line.strip('\n').split(' ') # 去掉列表中每一个元素的换行符
line.pop(0) # 去掉每行数据的"id"数据
temp.append(line)
iris = array(temp) # 最后用iris二维数组来存储数据集中的数据
testData = [] # 定义一个testData列表来接收用户输入的数据
sepalLength = float(input('请输入花萼长度:'))
sepalWidth = float(input('请输入花萼宽度:'))
petalLength = float(input('请输入花瓣长度:'))
petalWidth = float(input('请输入花瓣宽度:'))
testData.append(sepalLength)
testData.append(sepalWidth)
testData.append(petalLength)
testData.append(petalWidth)
distance = []
for item in iris:
# 计算数据集中每一个鸢尾花数据和与用户输入的数据之间的距离
result = math.sqrt((testData[0] - float(item[0]))**2 + (testData[1] - float(item[1]))**2
+ (testData[2] - float(item[2]))**2 + (testData[3] - float(item[3]))**2)
distance.append({
'data': result,
'species': item[4]
}) # 用一个字典来存储每一个鸢尾花与用户输入的数据之间的距离和每个鸢尾花的种类,
# 并将字典结果存储到distance列表中
for i in range(1, len(distance)): # 用冒泡排序算法根据每个鸢尾花数据与用户输入的数据之间的距离对distance中的数据进行升序排序
for j in range(0, len(distance) - i):
if distance[j]['data'] > distance[j + 1]['data']:
temp = distance[j]
distance[j] = distance[j + 1]
distance[j + 1] = temp
k = 15 # 定义k-近邻算法中的k值为15
species = ["setosa", "versicolor", "virginica"] # 鸢尾花的按三个种类
count = [0, 0, 0] # 用count列表存储距离最小的前k个数据中每个鸢尾花种类的数量
for i in range(0, k): # 统计前k个数据中每个鸢尾花种类的数量并存储到count列表中
if str(distance[i]['species']).replace('"', '') == 'setosa':
count[0] += 1
elif str(distance[i]['species']).replace('"', '') == 'versicolor':
count[1] += 1
else:
count[2] += 1
max = 0
for i in range(1, 3): # 找出前k个数据中数量最多的那个鸢尾花的分类,即为最终的分类结果
if count[i] > max:
max = i
print('预测您的鸢尾花种类为:'+species[max])
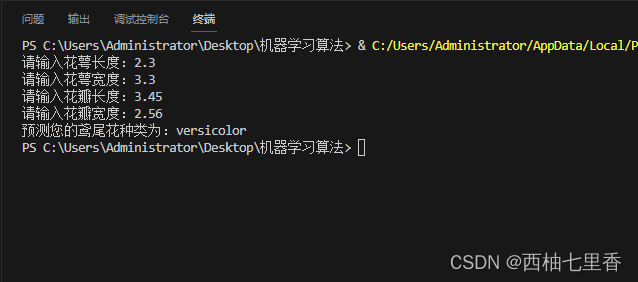
代码运行结果如下:















 1567
1567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









