







1. 本文贡献
- 由于土地覆盖格局复杂,训练样本采集成本高,以及地理差异或获取条件等因素导致卫星图像分布变化严重,很少有研究将高分辨率图像应用于大尺度详细分类的土地覆盖制图。为了填补这一空白,本文提出了一个大规模的土地覆盖数据集,50亿像素。它包含150张高分辨率高分2号(4米)卫星图像,超过50亿标记像素,在24个类别系统中标注,包括人工建造,农业和自然类别。
- 提出了一种基于深度学习的无监督域自适应方法,该方法可以将在标记数据集(称为源域)上训练的分类模型转移到大规模土地覆盖制图的未标记数据(称为目标域)上。
2. “50亿像素”数据集
本文提出的大规模土地覆盖数据集名为“50亿像素”。由150张GF-2卫星图像组成,在一个更完整的分类系统中进行了注释。它具有类别丰富、覆盖范围大、分布广、空间分辨率高(4m)的优点。数据集地址:https://x-ytong.github.io/project/Five-Billion-Pixels.html
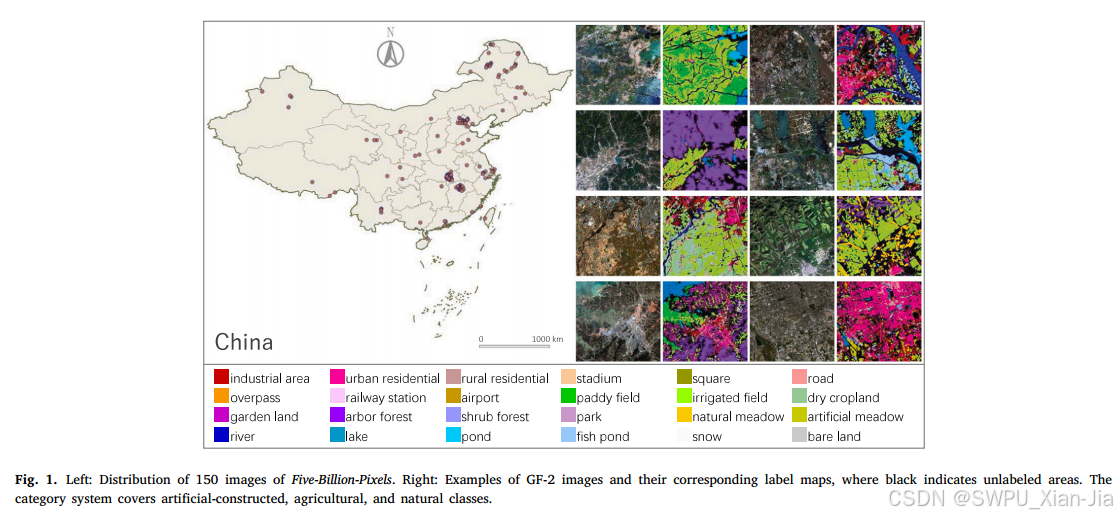
数据集的特点:
- 丰富的类别:50亿像素的类别系统具体包括:工业区、城市住宅、农村住宅、体育场、广场、道路、立交桥、火车站、机场、水田、灌溉田、旱地、园地、乔木林、灌木林、公园、天然草甸、人工草甸、河流、湖泊、池塘、鱼塘、雪地、裸地。
- 覆盖范围大:50亿像素”中包含的150张GF-2卫星图像的总地理覆盖面积超过50,000平方公里。
- 分布广泛:50亿像素的图像来源来自中国60多个分散的行政区域,如上图所示。由于地理分布广泛,“50亿像素”可以反映不同气候、海拔和地质条件下的景观变化。
3. 预测分类的方法
为了使 DCNNs 适应一个新的领域,没有比拥有其特征分布的示例更好的方法了。面对没有标注信息的 𝑻,本文受到伪标签的启发,提出了一种 UDA 方法,该方法从 𝑻 收集可靠的逐像素示例以进行模型自适应。与基于差异和基于对抗的 UDA 方法(这两种方法迫使两个分布在特征空间中对齐)相比,伪标记更灵活,对于复杂的现实世界情况可能更可靠。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









