





 本文提出MobileViT,一种专为移动设备设计的轻量级通用视觉变压器,旨在结合CNN和ViT的优点,提供低延迟、高性能。MobileViT在保持较少参数的同时,在ImageNet和MS-COCO任务上超越了基于CNN和ViT的模型,展示了在移动视觉任务中的优秀表现和鲁棒性。
本文提出MobileViT,一种专为移动设备设计的轻量级通用视觉变压器,旨在结合CNN和ViT的优点,提供低延迟、高性能。MobileViT在保持较少参数的同时,在ImageNet和MS-COCO任务上超越了基于CNN和ViT的模型,展示了在移动视觉任务中的优秀表现和鲁棒性。
ABSTRACT
轻量级卷积神经网络(cnn)是移动视觉任务的实际应用。他们的空间归纳偏差使他们能够在不同的视觉任务中学习参数更少的表征。然而,这些网络在空间上是局部的。为了学习全局表征,采用了基于自注意的视觉变换(ViTs)。与cnn不同,vit是重量级的。在本文中,我们提出了以下问题:是否有可能将cnn和vit的优势结合起来,为移动视觉任务构建一个轻量、低延迟的网络?为此,我们推出了MobileViT,这是一款用于移动设备的轻型通用视觉变压器。MobileViT为变压器的全球信息处理提供了不同的视角。我们的研究结果表明,在不同的任务和数据集上,MobileViT明显优于基于cnn和viti的网络。在ImageNet-1k数据集上,MobileViT在约600万个参数下达到了78.4%的前1准确率,在相同数量的参数下,比MobileNetv3(基于cnn)和DeIT(基于viti)的准确率分别提高了3.2%和6.2%。在MS-COCO目标检测任务上,对于相似数量的参数,MobileViT比MobileNetv3的准确率高5.7%。我们的源代码是开源的,可以在:
1 INTRODUCTION
基于自注意的模型,特别是视觉变形器(ViTs);图1;Dosovitskiy等人,2021)是卷积神经网络(cnn)学习视觉表征的替代方案。
简而言之,ViT将图像划分为一系列不重叠的patch,然后在transformer中使用多头自关注学习patch间表示(V aswani et al, 2017)。总的趋势是增加ViT网络中的参数数量以提高性能(例如,Touvron等人,2021a;Graham et al, 2021;Wu et al, 2021)。然而,这些性能改进是以模型大小(网络参数)和延迟为代价的。许多现实世界的应用(例如,增强现实和自动轮椅)需要在资源受限的移动设备上及时运行视觉识别任务(例如,对象检测和语义分割)。为了有效,这些任务的ViT模型应该是轻量级和快速的。即使减小ViT模型的模型尺寸以匹配移动设备的资源约束,其性能也明显不如轻量级cnn。例如,对于大约500 - 600万的参数预算,DeIT (Touvron等人,2021a)的准确性比MobileNetv3 (Howard等人,2019)低3%。因此,设计轻量级ViT模型势在必行。
轻量级cnn为许多移动视觉任务提供了动力。然而,基于viti的网络距离在这些设备上使用还很遥远。与易于优化并与特定任务网络集成的轻量级cnn不同,vit是重量级的(例如,ViT-B/16 vs. MobileNetv3: 86,750万个参数),更难优化(Xiao等人,2021),需要大量的数据增强和L2正则化以防止过拟合(Touvron等人,2021a;Wang et al ., 2021),下游任务需要昂贵的解码器,特别是密集预测任务。例如,基于vitl的分割网络(Ranftl et al, 2021)学习了大约3.45亿个参数,并实现了与基于cnn的网络DeepLabv3 (Chen et al, 2017)相似的性能,具有5900万个参数。基于vit的模型需要更多的参数可能是因为它们缺乏图像特定的归纳偏差,这是cnn固有的(Xiao et al, 2021)。为了构建鲁棒和高性能的ViT模型,需要结合卷积和变压器的混合方法
正在获得兴趣(Xiao et al ., 2021;d’ascoli等,2021;Chen et al ., 2021b)。然而,这些混合模型仍然是重量级的,并且对数据扩展很敏感。例如,去除CutMix (Zhong等人,2020)和deit风格(Touvron等人,2021a)数据增强会导致Heo等人(2021)的ImageNet精度显著下降(78.1%至72.4%)。
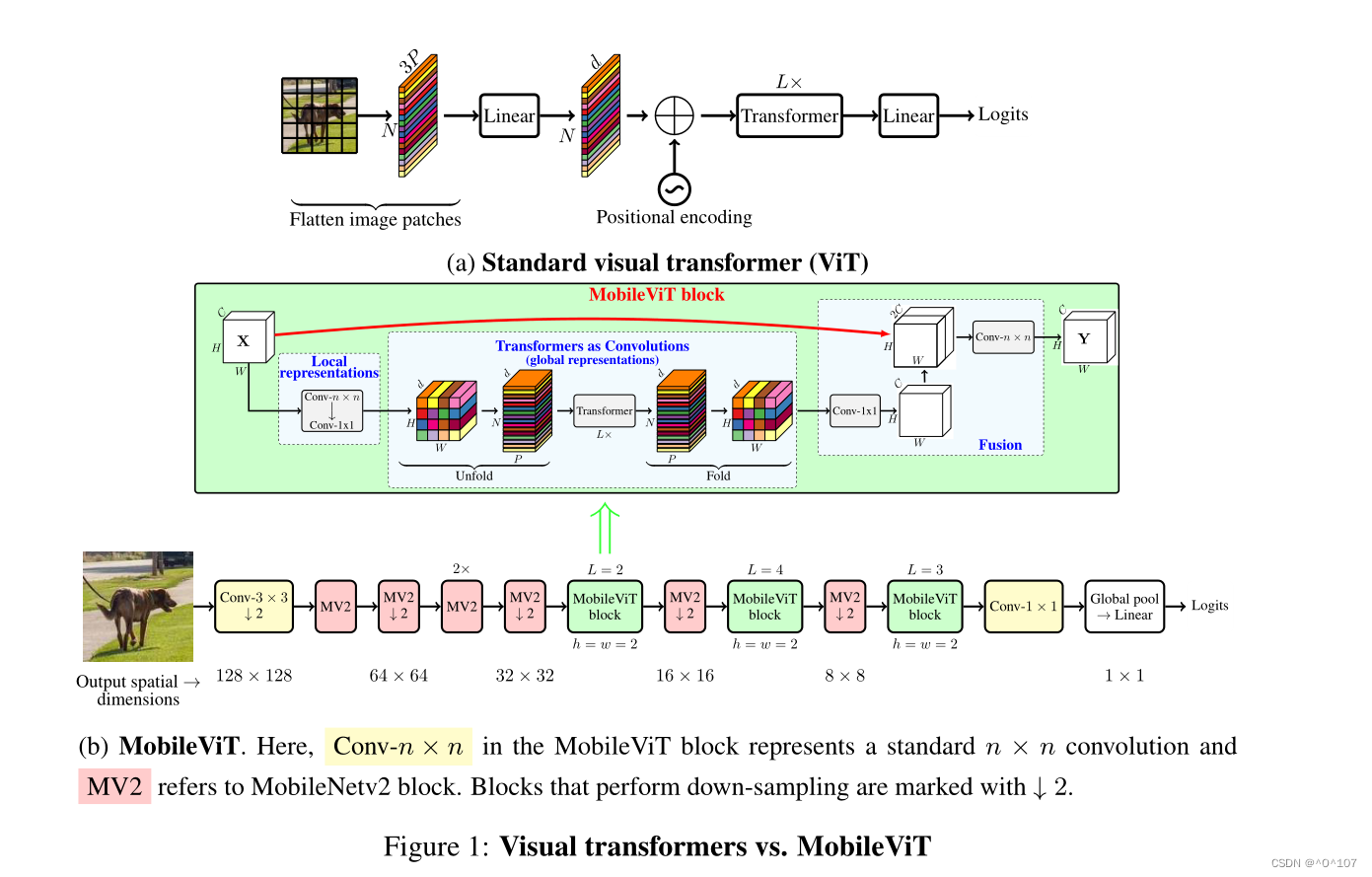
如何结合cnn和变压器的优势来构建移动视觉任务的ViT模型仍然是一个悬而未决的问题。移动视觉任务需要轻量、低延迟和精确的模型,以满足设备的资源限制,并且是通用的,以便它们可以应用于不同的任务(例如,分割和检测)。请注意,浮点操作(FLOPs)不足以满足移动设备上的低延迟,因为FLOPs忽略了几个重要的相关因素,如内存访问、并行度和平台特性(Ma et al, 2018)。例如,Heo等人(2021)的基于vitv的方法PiT比DeIT (Touvron等人,2021a)的FLOPs少3倍,但在移动设备上具有相似的推理速度(DeIT与iPhone-12上的PiT: 10.99 ms vs. 10.56 ms)。因此,本文不是针对FLOPs1进行优化,而是专注于为移动视觉任务设计轻量级(§3)、通用(§4.1 &§4.2)和低延迟(§4.3)的网络。我们通过MobileViT实现了这一目标,MobileViT结合了cnn的优点(例如,空间归纳偏差和对数据增强的敏感度较低)和vit(例如,输入自适应加权和全局处理)。具体来说,我们引入了MobileViT块,它可以有效地对张量中的局部和全局信息进行编码(图1b)。与ViT及其变体(有或没有卷积)不同,MobileViT提供了学习全局表示的不同视角。标准卷积包括三个操作:展开、局部处理和
折叠。MobileViT块将卷积中的局部处理替换为使用变压器的全局处理。这使得MobileViT块具有类似CNN和vitv的属性,这有助于它用更少的参数和简单的训练食谱(例如,基本增强)学习更好的表示。据我们所知,这是第一个表明轻量级vit可以在不同的移动视觉任务中通过简单的训练食谱实现轻量级cnn级性能的工作。对于大约5-6百万的参数预算,MobileViT在ImageNet-1k数据集上达到了78.4%的前1准确率(Russakovsky等人,2015),比MobileNetv3的准确率高3.2%,并且具有简单的训练处方(MobileViT vs. MobileNetv3: 300 vs. 600 epoch;1024 vs. 4096批大小)。我们还观察到,在高度优化的移动视觉任务特定架构中,将MobileViT用作特征主干时,性能有了显著提高。用MobileViT取代MNASNet (Tan等人,2019)作为SSDLite (Sandler等人,2018)的特征主干,可以获得更好的(+1.8% mAP)和更小的(1.8倍)检测网络(图2)。
2 RELATED WORK
轻量级的cnn。cnn的基本构建层是一个标准的卷积层。由于这一层的计算成本很高,因此提出了几种基于分解的方法来使其轻量化和移动友好(例如,Jin等人,2014;Chollet, 2017;Mehta et al, 2020)。
其中,Chollet(2017)的可分离卷积引起了人们的兴趣,并广泛用于最先进的轻量级cnn,用于移动视觉任务,包括MobileNets (Howard等人,2017;Sandler等人,2018;Howard等人,2019),ShuffleNetv2 (Ma等人,2018),ESPNetv2 (Mehta等人,2019),MixNet (Tan和Le, 2019b)和MNASNet (Tan等人,2019)。这些轻量级的cnn功能齐全,易于训练。例如,这些网络可以很容易地取代现有任务特定模型(例如DeepLabv3)中的重量级骨干(例如ResNet (He et al, 2016)),以减小网络规模并改善延迟。尽管有这些好处,但这些方法的一个主要缺点是它们在空间上是局部的。这项工作将变压器视为卷积;允许利用卷积(例如,通用和简单的训练)和变压器(例如,全局处理)的优点来构建轻量级(§3)和通用(§4.1和§4.2)vit。
视觉变形金刚。Dosovitskiy等人(2021)将V aswani等人(2017)的变压器应用于大规模图像识别,并表明在超大规模的数据集(例如JFT-300M)下,ViTs可以达到cnn级别的精度,而不会产生图像特定的感应偏置。通过大量的数据增强、大量的L2正则化和蒸馏,vit可以在ImageNet数据集上进行训练,以达到cnn级别的性能(Touvron等,2021a;b;Zhou et al, 2021)。然而,与cnn不同的是,vit的可优化性不达标,而且难以训练。后续作品(如Graham et al ., 2021;Dai等,2021;Liu et al ., 2021;Wang等,2021;袁等,2021b;Chen et al ., 2021b)表明,这种不合格的可优化性是由于vit中缺乏空间归纳偏差。在vit中使用卷积结合这种偏差可以提高它们的稳定性和性能。已经探索了不同的设计来获得卷积和变压器的好处。
例如,Xiao et al .(2021)的ViT- c在ViT中加入了一个早期卷积干。CvT (Wu et al ., 2021)修改了变压器中的多头注意,并使用深度可分离卷积代替线性投影。僵尸网络(Srinivas et al ., 2021)用多头关注取代ResNet瓶颈单元中的标准3×3卷积。ConViT (d 'Ascoli等人,2021)使用门控位置自注意结合了软卷积归纳偏差。PiT (Heo et al, 2021)用深度卷积池化层扩展了ViT。虽然这些模型可以在广泛增强的情况下达到与cnn竞争的性能,但这些模型大多数是重量级的。例如,PiT和CvT学习的参数分别比EfficientNet (Tan & Le, 2019a)多6.1倍和1.7倍,并且在ImageNet1k数据集上分别达到了相似的性能(top-1准确率约为81.6%)。此外,当这些模型按比例缩小以构建轻量级ViT模型时,它们的性能明显低于轻量级cnn。对于600万左右的参数预算,PiT的ImageNet-1k精度比MobileNetv3低2.2%。
讨论。与普通的vit相比,结合卷积和变压器可以产生鲁棒和高性能的vit。然而,这里有一个悬而未决的问题:如何结合卷积和变压器的优势来构建用于移动视觉任务的轻量级网络?本文的重点是设计轻量级的ViT模型,用简单的训练配方胜过最先进的模型。为此,我们引入了MobileViT,它结合了cnn和vit的优势,构建了一个轻量级、通用的、移动友好的网络。MobileViT带来了一些新颖的观察结果。(i)更好的性能:对于给定的参数预算,与现有的轻量级cnn相比,els在不同的移动视觉任务(§4.1和§4.2)上实现了更好的性能。(ii)泛化能力:泛化能力是指培训指标与评价指标之间的差距。对于具有相似训练指标的两个模型,具有更好评估指标的模型具有更强的泛化性,因为它可以更好地预测未知数据集。与cnn相比,以前的ViT变体(有卷积和没有卷积)即使在广泛的数据增强下也表现出较差的泛化能力(Dai等人,2021),而MobileViT表现出更好的泛化能力(图3)。(iii)鲁棒性:一个好的模型应该对超参数(例如,数据增强和L2正则化)具有鲁棒性,因为调整这些超参数是费时和消耗资源的。与大多数基于vit的模型不同,MobileViT模型使用基本增强进行训练,并且对L2正则化不太敏感(§C)。















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









