






苹果结合MobileNet以及自注意力发布了MobileViT系列论文。
mobileViTv1
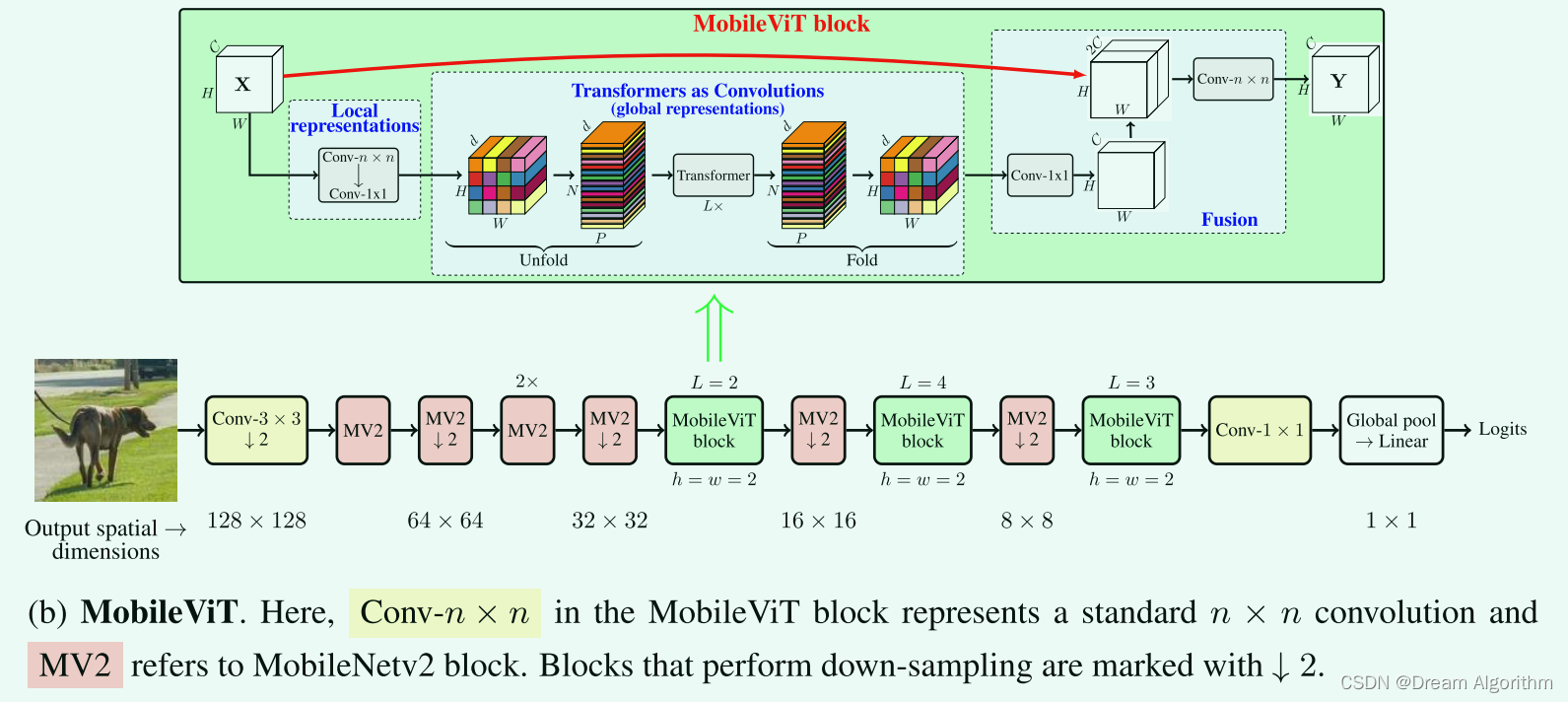
卷积中间加上transformer,既有全局信息,又有局部信息。想要理解这个网络主要要理解N、P、d代表的是啥,
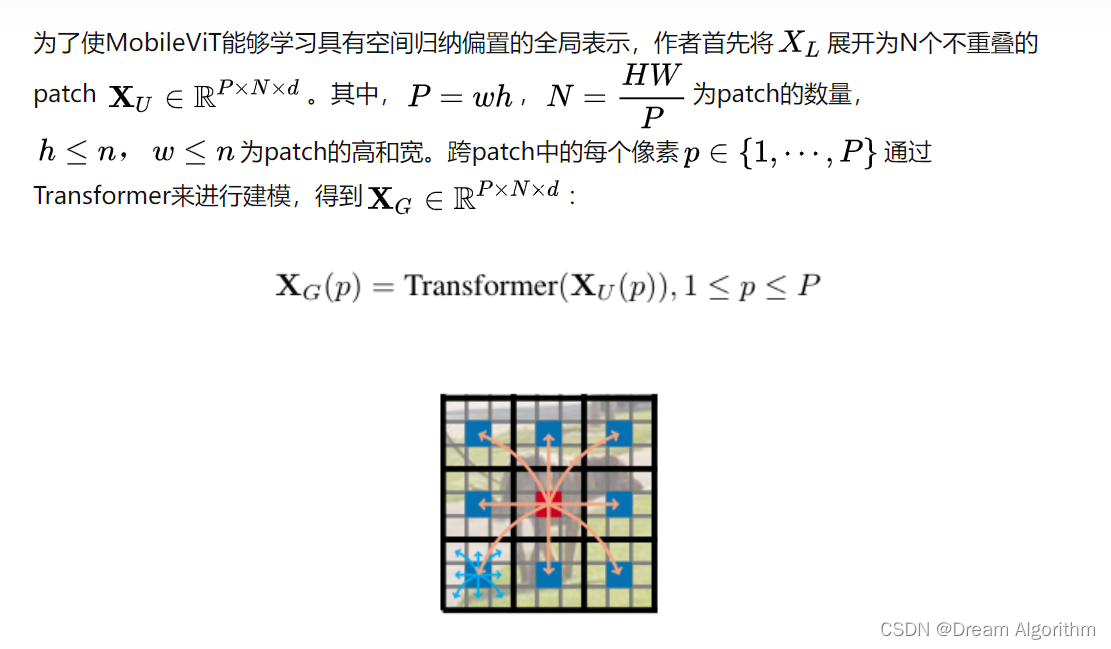
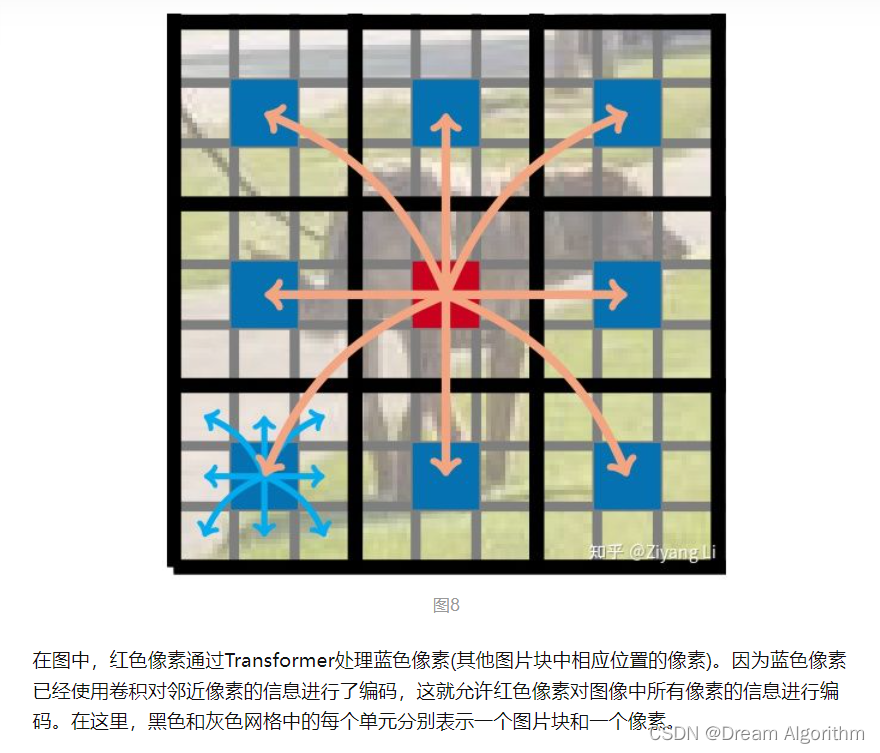
先将一张图片划分为一个个不重叠的patch,P = wh, ,跨patch的每个像素通过transformer进行建模,论文中说是这样可以学习具有空间归纳偏置的全局表示,我还有听到的解释是:之所以可以这样操作是因为图片中有大量的冗余像素,可以将一个patch当中的像素当成是同一个东西。
unfolding和folding的代码如下:
def unfolding(self, x: Tensor) -> Tuple[Tensor, Dict]:
patch_w, patch_h = self.patch_w, self.patch_h
patch_area = patch_w * patch_h
batch_size, in_channels, orig_h, orig_w = x.shape
new_h = int(math.ceil(orig_h / self.patch_h) * self.patch_h)
new_w = int(math.ceil(orig_w / self.patch_w) * self.patch_w)
interpolate = False
if new_w != orig_w or new_h != orig_h:
# Note: Padding can be done, but then it needs to be handled in attention function.
x = F.interpolate(x, size=(new_h, new_w), mode="bilinear", align_corners=False)
interpolate = True
# number of patches along width and height
num_patch_w = new_w // patch_w # n_w
num_patch_h = new_h // patch_h # n_h
num_patches = num_patch_h * num_patch_w # N
# [B, C, H, W] -> [B * C * n_h, p_h, n_w, p_w]
x = x.reshape(batch_size * in_channels * num_patch_h, patch_h, num_patch_w, patch_w)
# [B * C * n_h, p_h, n_w, p_w] -> [B * C * n_h, n_w, p_h, p_w]
x = x.transpose(1, 2)
# [B * C * n_h, n_w, p_h, p_w] -> [B, C, N, P] where P = p_h * p_w and N = n_h * n_w
x = x.reshape(batch_size, in_channels, num_patches, patch_area)
# [B, C, N, P] -> [B, P, N, C]
x = x.transpose(1, 3)
# [B, P, N, C] -> [BP, N, C]
x = x.reshape(batch_size * patch_area, num_patches, -1)
info_dict = {
"orig_size": (orig_h, orig_w),
"batch_size": batch_size,
"interpolate": interpolate,
"total_patches": num_patches,
"num_patches_w": num_patch_w,
"num_patches_h": num_patch_h,
}
return x, info_dict
def folding(self, x: Tensor, info_dict: Dict) -> Tensor:
n_dim = x.dim()
assert n_dim == 3, "Tensor should be of shape BPxNxC. Got: {}".format(
x.shape
)
# [BP, N, C] --> [B, P, N, C]
x = x.contiguous().view(
info_dict["batch_size"], self.patch_area, info_dict["total_patches"], -1
)
batch_size, pixels, num_patches, channels = x.size()
num_patch_h = info_dict["num_patches_h"]
num_patch_w = info_dict["num_patches_w"]
# [B, P, N, C] -> [B, C, N, P]
x = x.transpose(1, 3)
# [B, C, N, P] -> [B*C*n_h, n_w, p_h, p_w]
x = x.reshape(batch_size * channels * num_patch_h, num_patch_w, self.patch_h, self.patch_w)
# [B*C*n_h, n_w, p_h, p_w] -> [B*C*n_h, p_h, n_w, p_w]
x = x.transpose(1, 2)
# [B*C*n_h, p_h, n_w, p_w] -> [B, C, H, W]
x = x.reshape(batch_size, channels, num_patch_h * self.patch_h, num_patch_w * self.patch_w)
if info_dict["interpolate"]:
x = F.interpolate(
x,
size=info_dict["orig_size"],
mode="bilinear",
align_corners=False,
)
return x
def forward(self, x: Tensor) -> Tensor:
res = x
fm = self.local_rep(x)
# convert feature map to patches
patches, info_dict = self.unfolding(fm)
# learn global representations
for transformer_layer in self.global_rep:
patches = transformer_layer(patches)
# [B x Patch x Patches x C] -> [B x C x Patches x Patch]
fm = self.folding(x=patches, info_dict=info_dict)
fm = self.conv_proj(fm)
fm = self.fusion(torch.cat((res, fm), dim=1))
return fm
MobileViTv2
v2相对于v1的改进是在注意力方面,注意力采用的是线性注意力。
上图:
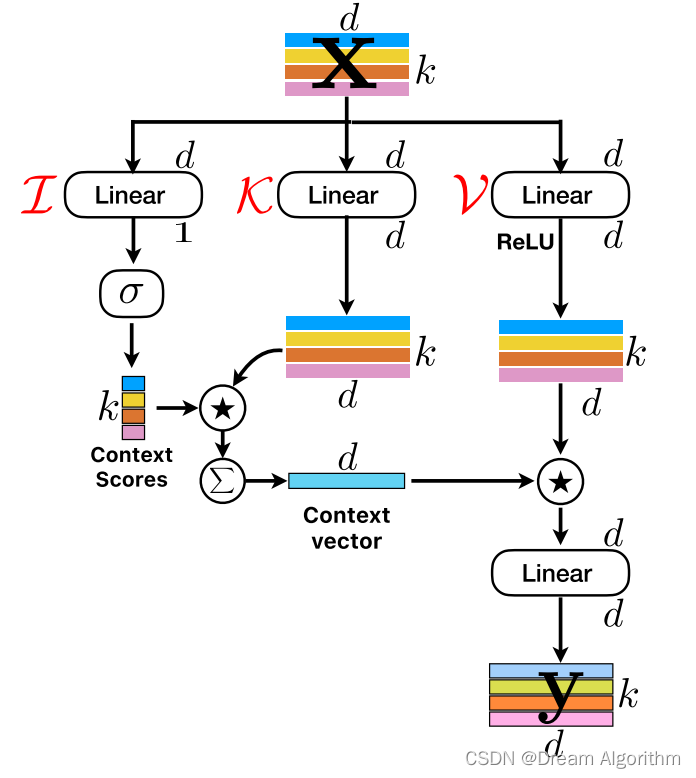
简单来说就是:先经过三个线性映射,B_,k,d -> B_,k,1
B_,k,1 * B_,k,d -> B_,k,d
B_,k,d -> B_,1,d
B_,1,d * B_,k,d = B_,k,d
MobileViTv3
v3是在v2的基础上又进行了小改进
v1、v2、v3对比如下:
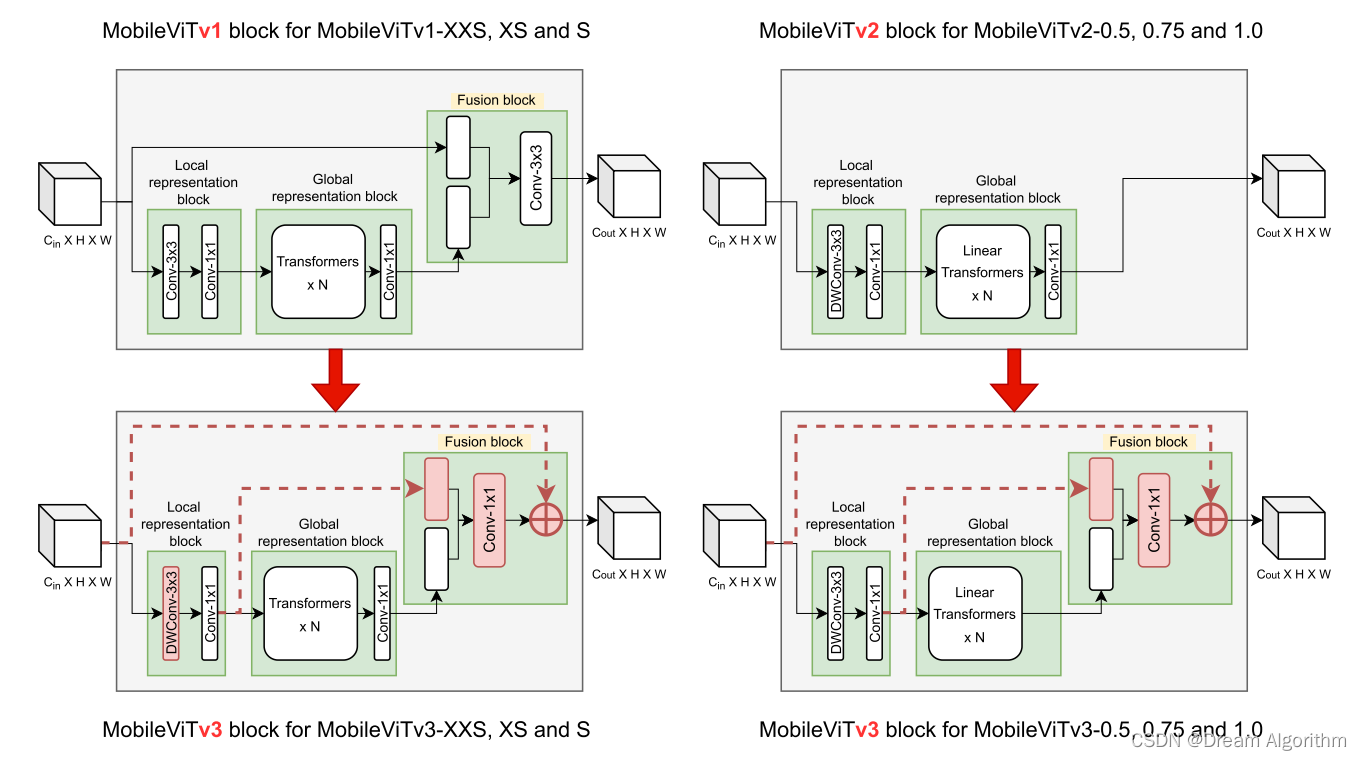
以上就是我对MobileViT的理解,仅作为学习总结,如有理解有误的地方欢迎指正。

















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









