






 文章介绍了机器学习中的监督学习和无监督学习,包括回归问题和分类问题。在监督学习中,重点讲解了线性回归,目标是最小化代价函数。梯度下降算法用于优化参数,通过学习率和偏导数调整权重。文章还讨论了特征缩放和学习率对模型训练的影响,以及如何判断梯度下降是否收敛。
文章介绍了机器学习中的监督学习和无监督学习,包括回归问题和分类问题。在监督学习中,重点讲解了线性回归,目标是最小化代价函数。梯度下降算法用于优化参数,通过学习率和偏导数调整权重。文章还讨论了特征缩放和学习率对模型训练的影响,以及如何判断梯度下降是否收敛。
机器学习
监督学习 supervised learning
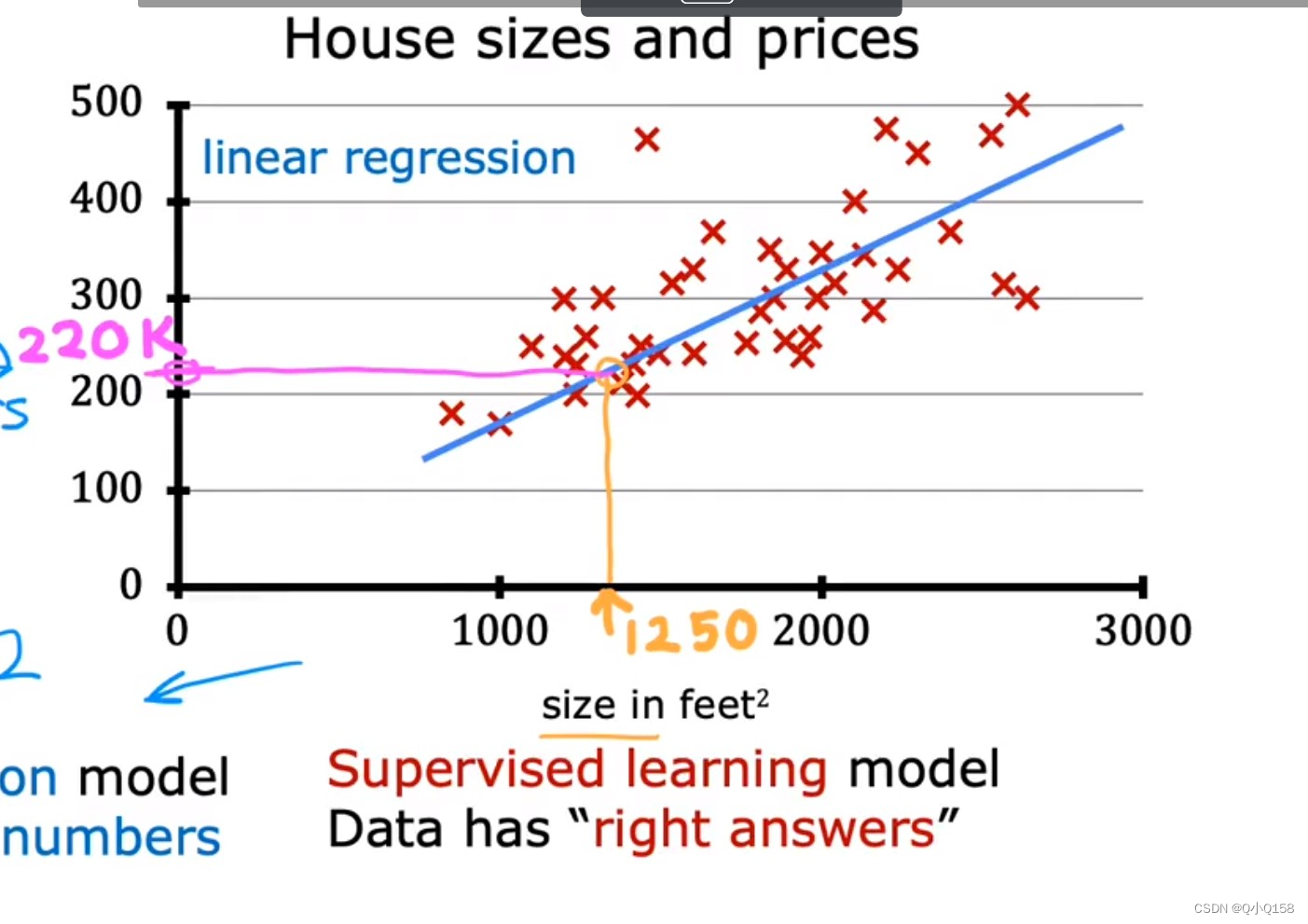
监督学习已经知道数据的label,对数据集中每个样本进行算法预测,得到“正确答案”。
-
回归问题 regression problem:预测连续指输出,如预测房价等
-
分类问题 classification problem:预测离散值输出
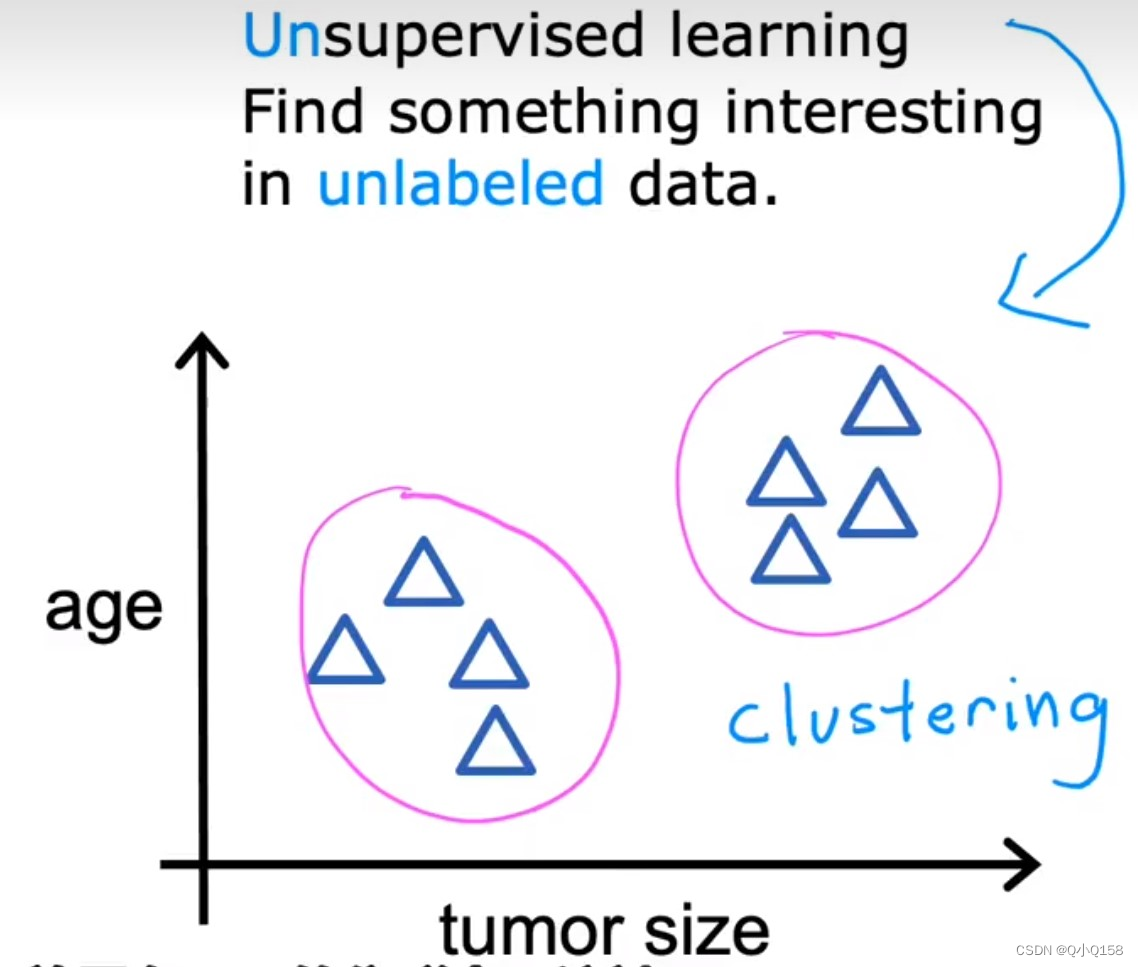
无监督学习 unsupervised learning
无监督学习是不知道数据具体的含义,比如给定一些数据但不知道它们具体的信息,对于分类问题,无监督学习可以得到多个不同的聚类,从而实现预测的功能。
聚类算法 clustering algorithm 应用:组织大型的计算机集群、社交网络的分析、天文数据分析
线性回归 linear regression
线性回归是将训练数据尽可能拟合到一条线上。多变量的线性回归称为多元线性回归。
一些术语

代价函数 Cost Function
度量预测值f(x^i)和真实值y之间的差异函数叫做代价函数。如果多个样本,则将所有代价函数的取指求平均,即除以样本总数m,得到平均平方误差。(为了便于后续计算,代价函数往往要再除以一个2)

Goal of linear regression: minimize J(w). 找到参数w或w和b,使代价函数J的值最小。
梯度下降算法 gradient descent
最小化J ,大体过程:首先为每个参数赋一个初值,通过代价函数的梯度不断调整参数,最终得到一个局部最优解。初值的不同可能会得到两个不同的结果,即梯度下降不一定得到全局最优解。

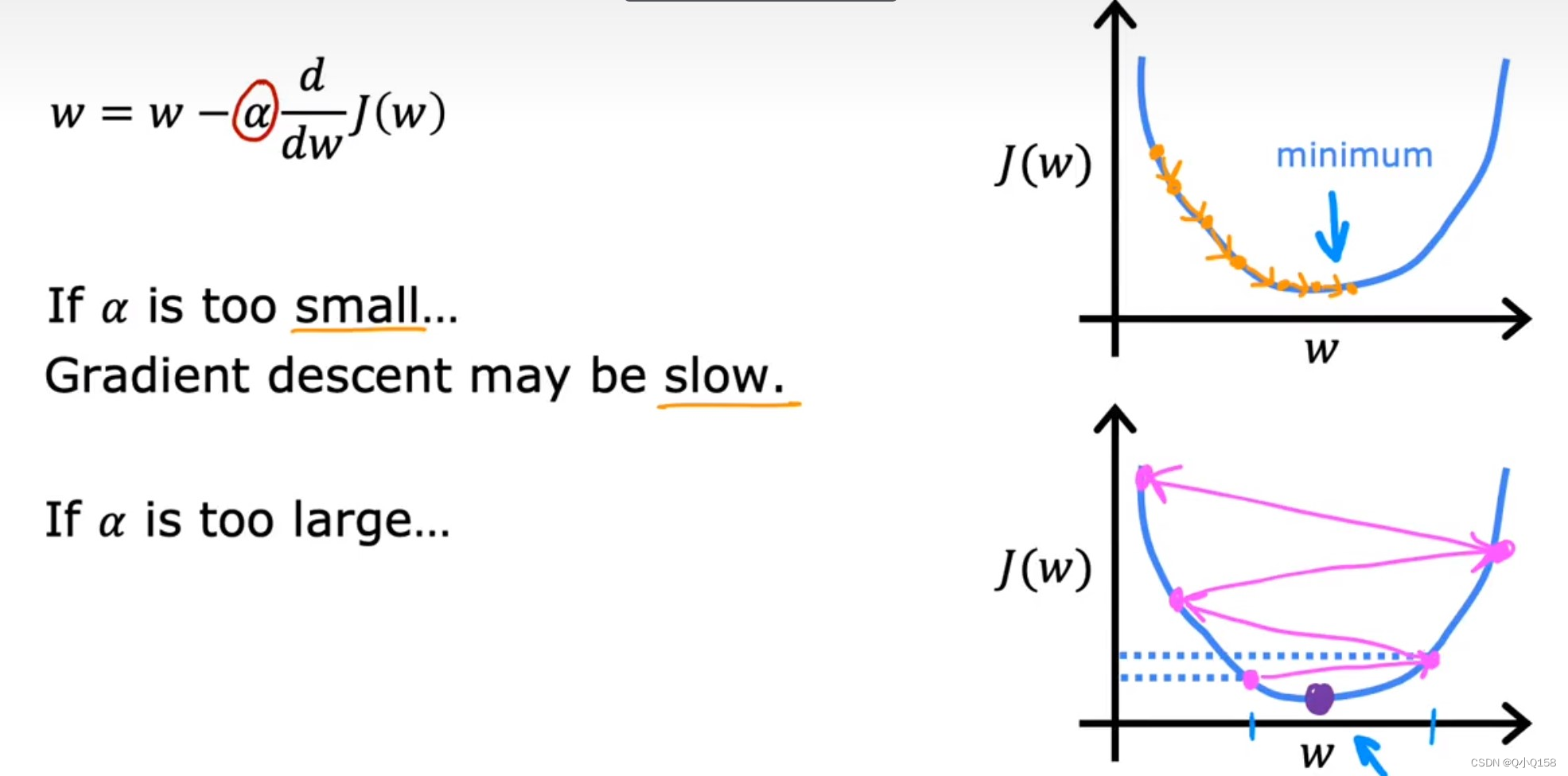
梯度下降公式当中有两个部分,学习率和偏导数。

偏导数用来计算当前参数对应代价函数的斜率,导数为正则θ(w,b)减小,导数为负则θ(w,b)增大,通过这样的方式使得整体收敛,得到局部最优点。
α表示学习率,即每次参数更新的步长。
可以用“下坡”的例子来理解,偏导数代表下坡的方向,而学习率α表示每次下坡走的步数,如果步数太小,则需要走很多步才能收敛,而如果太大则可能不会收敛甚至发散。
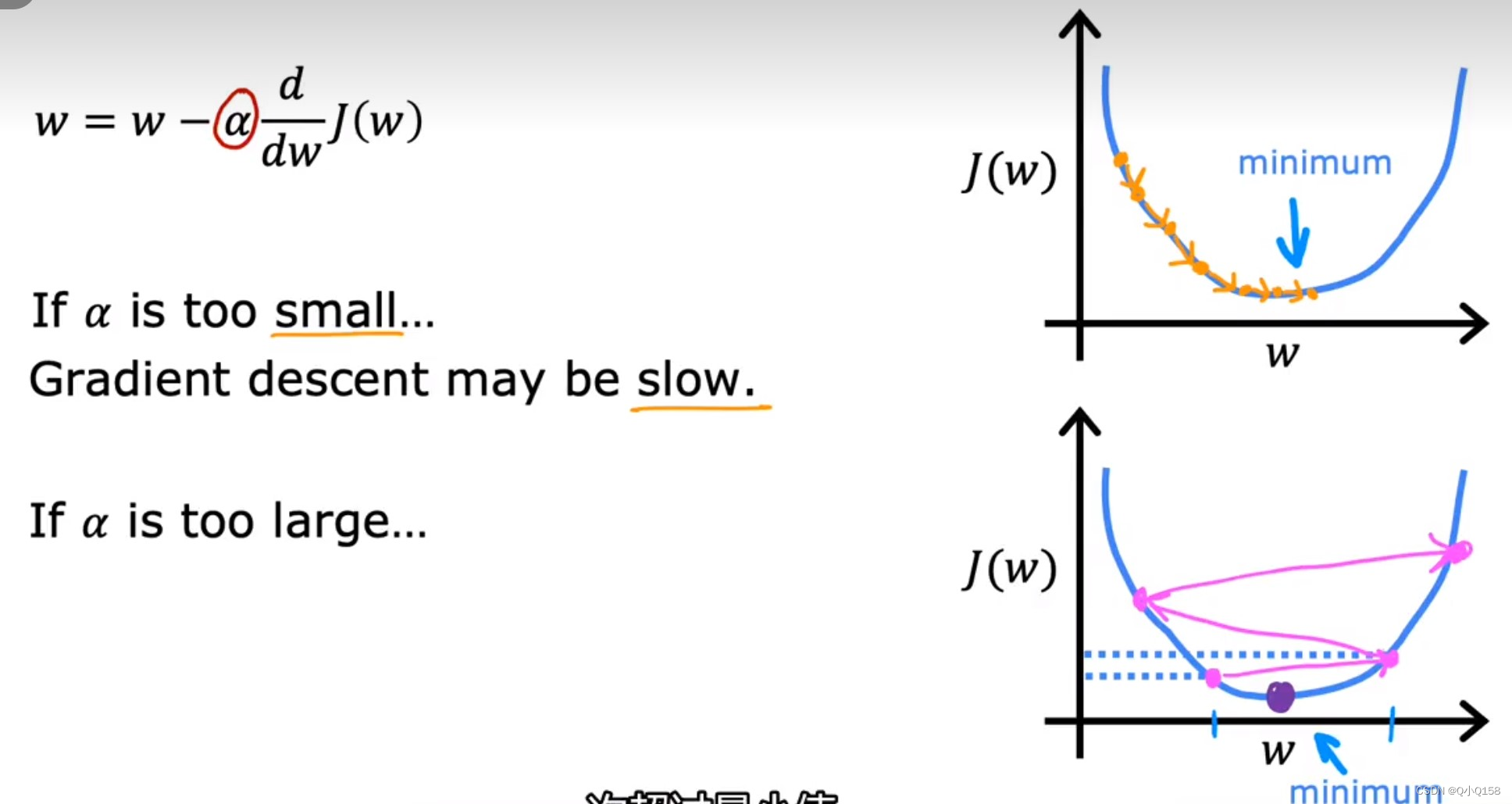
梯度下降运算总结

单元梯度下降
单个变量

多元梯度下降
通常问题都会设计多个变量,例如房价预测就包括面积、房间个数、楼层、价格等。
注意角标的不同意义,上标i代表第i个训练样例,下标j代表第j个具体特征。
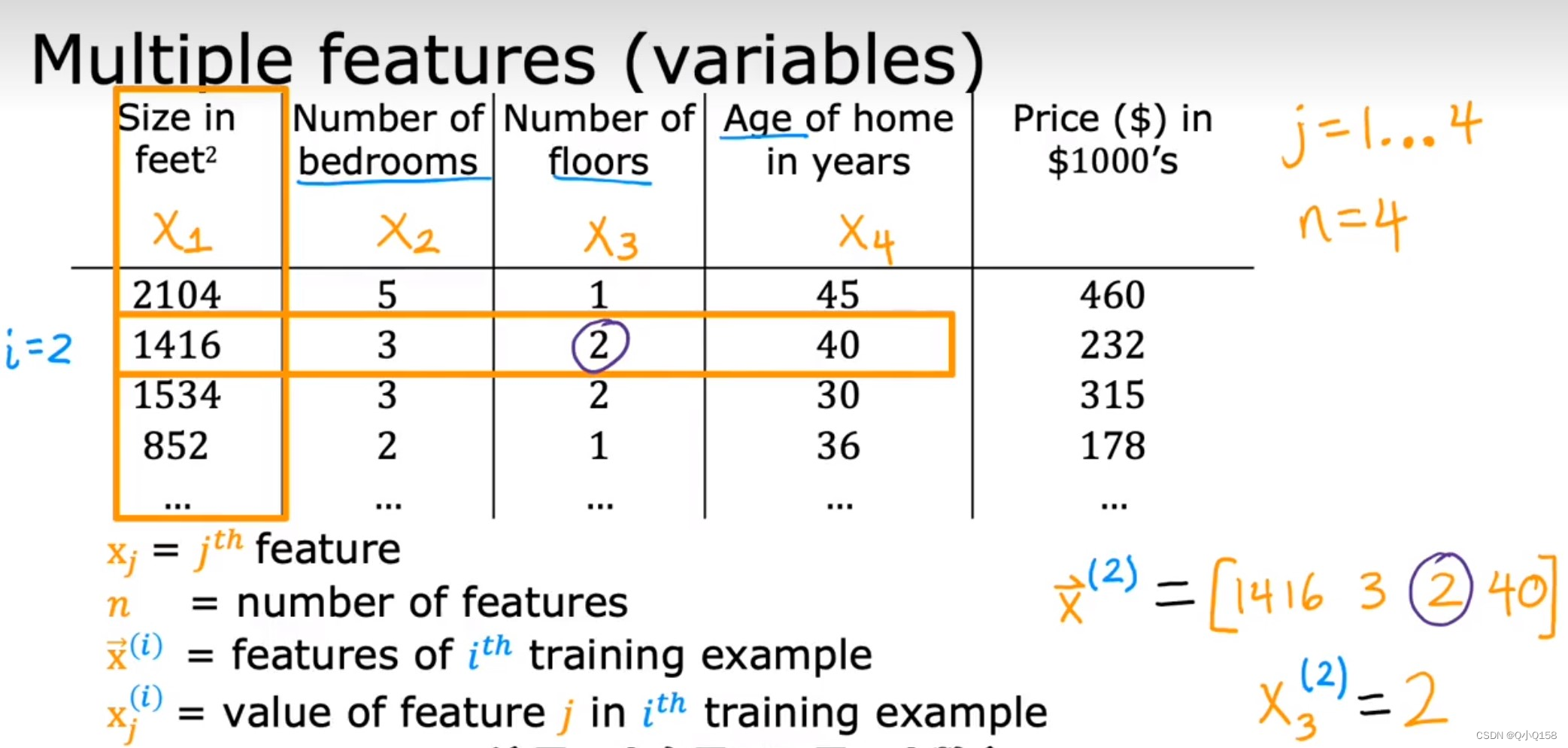
因此代价函数会包含多个变量,为了同一可以对常量引入变量x0=1.
对每个参数求偏导与单个参数类似
特征缩放
多个变量的度量不一样,数字之间相差的大小也会不同,可以将所有的特征变量缩放到大致相同范围,减少梯度算法的迭代。
特征缩放不一定非要落到[-1,1]之间,要求数据相对接近。
Xi=(Xi-μ)/σ,μ表示平均值,σ表示标准差。

学习率α
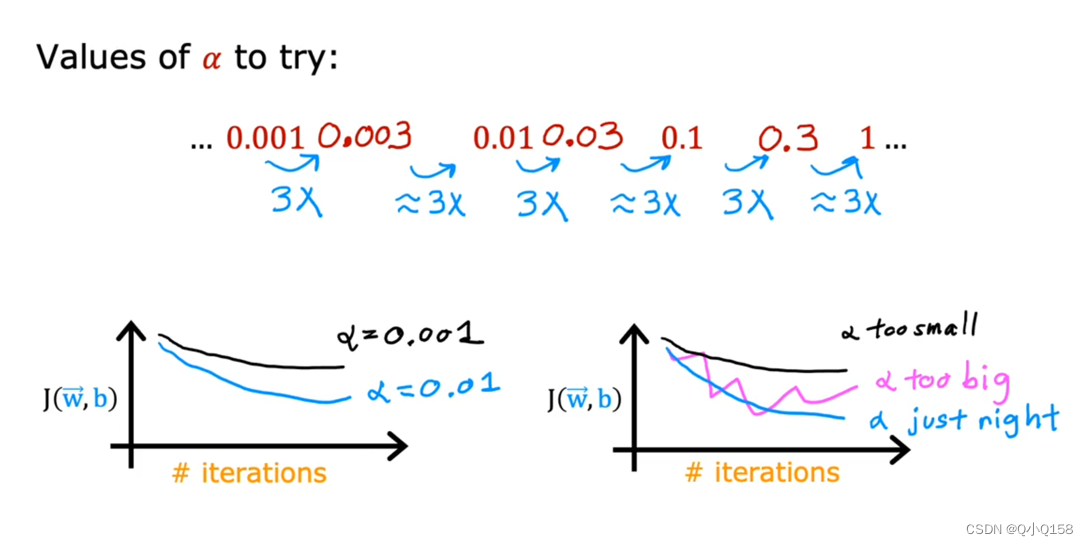
学习率的大小会影响梯度算法的执行,太大可能会导致算法不收敛,太小会增加迭代的次数。
检查梯度下降是否收敛
确定一个极小量ε,如0.001或0.000001等,当代价函数的增减小于等于这个极小量时则收敛。

如何设置学习率
不断尝试,不能太大也不能太小















 3100
3100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









