







前言
距离第一次发布MAPPO的复现已经5个月了,在这学期大作业要实现关于MAPPO算法时,又拿出来看这个discrete不收敛的版本找了又近两个星期,有空的时候看一下到底算法哪里有问题,单个断点调试,结果发现还是没问题。
实现在:FreeRL/tree/main/MAPPO_file
一、MAPPO的离散形式不收敛原因
今天想起来之前复现了一个大佬的MAPPOdiacrete的版本,见:【FreeRL】MAPPO的离散复现和鲁棒性调整(大更新),看与这个代码的区别,突发奇想,断点看了下它的动作输入形式,是下面这种形式,
{'adversary_0': 0, 'agent_0': 4, 'agent_1': 1}
我再打印了下我之前的代码
{'adversary_0': array(0, dtype=int64), 'agent_0': array(4, dtype=int64), 'agent_1': array(1, dtype=int64)}
是这种形式,于是我尝试加int(),改成第一种形式,果然,立马收敛了。
action_ = { agent_id: int(action[agent_id]) for agent_id in env_agents} ## 针对PettingZoo离散动作空间 np.array(0) -> int(0)
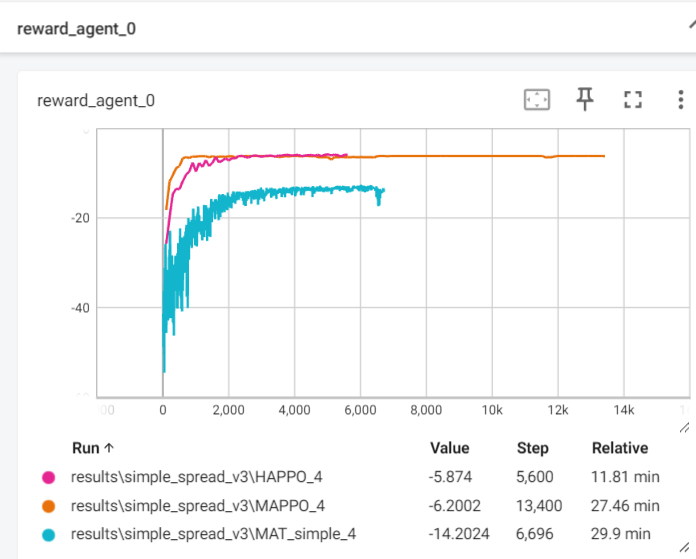
效果如下:均是离散实现,Happo和Mappo的agent数和seed数一致,MAT的agent与这两个不一致,seed不一致,agent个数不一致。
这里只展示收敛效果(是否收敛),不展示算法间收敛差异,详细差异可见:
好像之前没写博客对比,印象中参数都调的比较好的话
效果为MAPPO>HAPPO>MASAC>MATD3 ≈ MAAC >MADDPG+att >MADDPG >MAT
上述看个乐就行,由于这个对比需要耗费很长时间,所以没有严格对比,只有复现时的小数据对比。
那么理论上MASAC也可以加入discrete的版本,若后续我代码上用到,可以实现一下。
二、IPPO复现
ippo:论文链接:https://arxiv.org/pdf/2011.09533 无参考代码,自写
原理:
每个智能体仅估计其局部价值函数,完全去中心化,故称之为独立PPO (IPPO)。
实际上,只是在PPO外面套了一个for循环而已。
也没有找到其他实现可以收敛的,除了《动手学RL》,上有个共享PPOagent的实现,我试过是可以收敛的,但其用的是合作的环境,IPPO真正意义上和MAPPO的区别在于,IPPO可以适用于多人博弈环境如: simple_adversary_v3
而MAPPO由于算法上是将所有奖励和加起来(cat,stack),期望总体奖励最大化,而不是IPPO,是期望单个自己的奖励最大化(MADDPG也是如此),所以不适用博弈环境。
在动手学强化学习/chapter/3/多智能体强化学习进阶中,使用simple_adversary_v3环境的效果如下
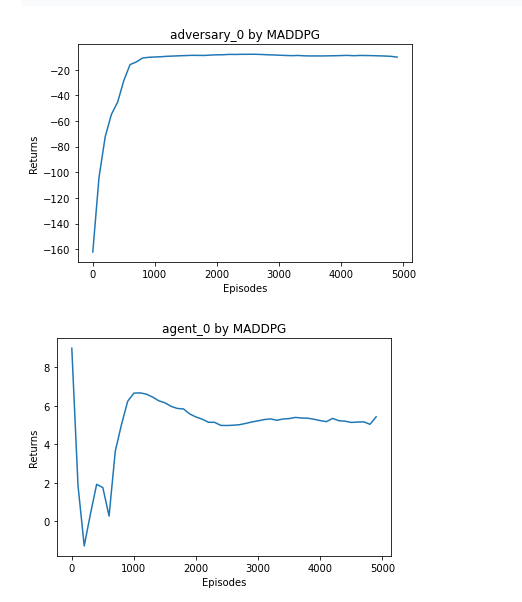
测试IPPO和MAPPO在此环境的效果:可以看出MAPPO确实不适用此环境,同理HAPPO,MAT也不适用。
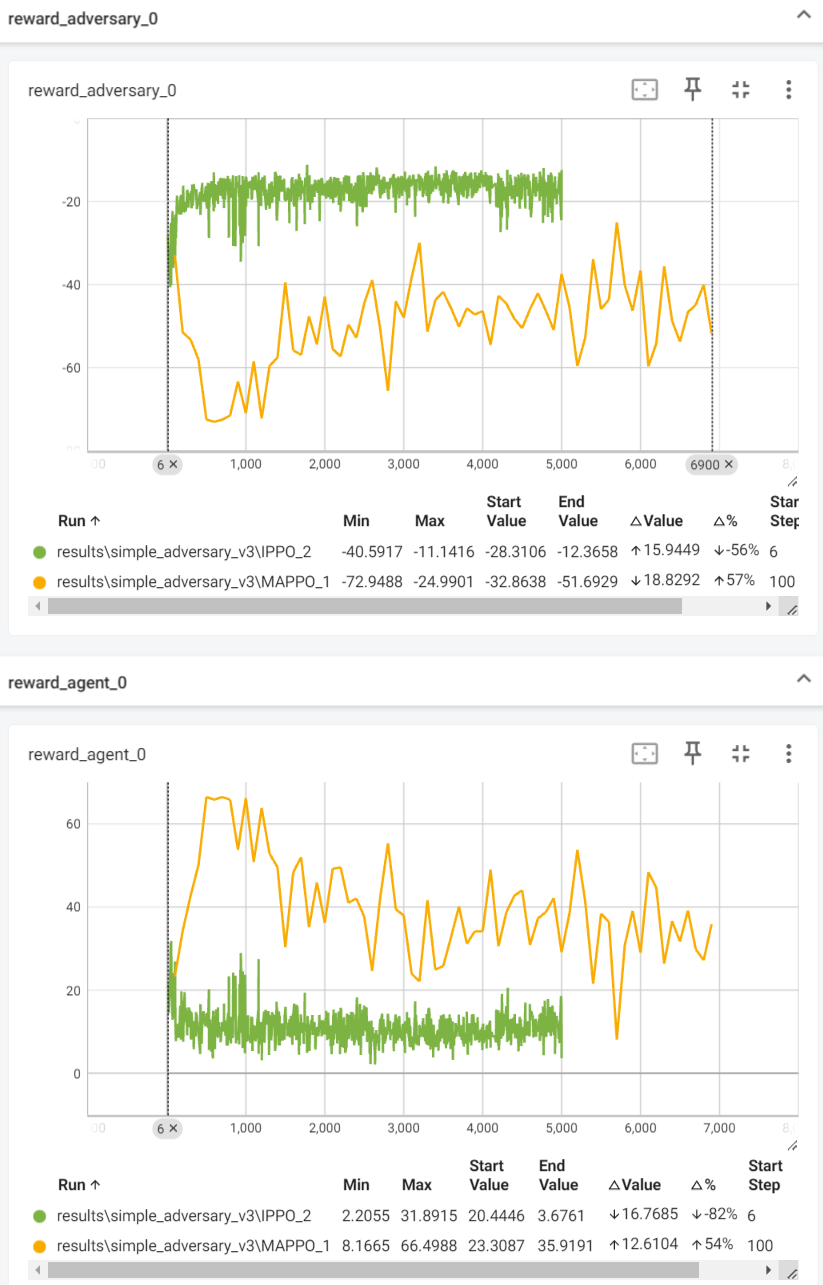
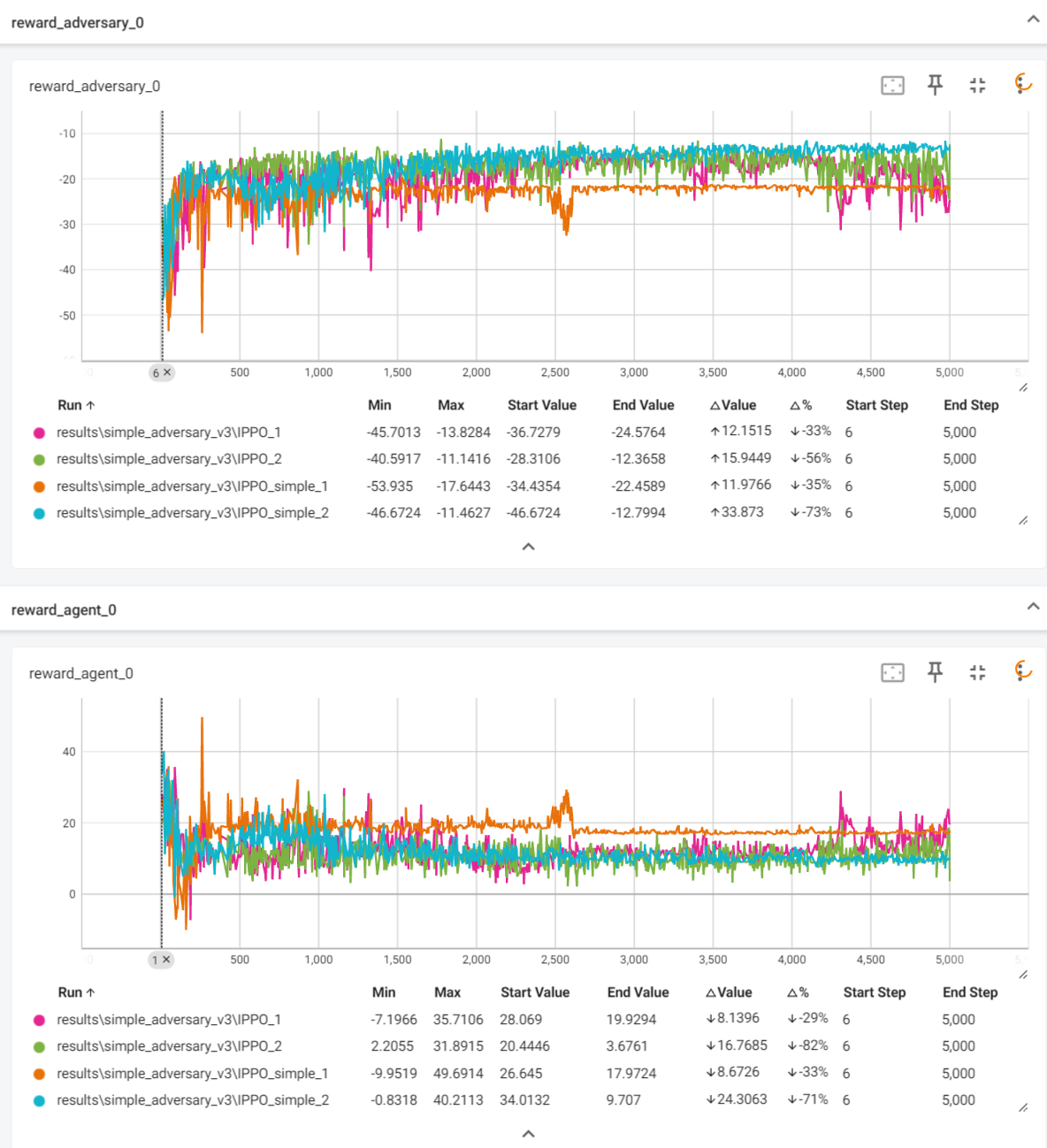
IPPO的效果如下:
2是连续,1是离散,

















 2270
2270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









