







精读文献内容,以常见的论文框架【研究背景、存在问题、实施方法、实验对比、结论影像】进行总结概括。
一、文献来源
1.1 文献名称
此次阅读的文献为:
The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games
1.2 作者信息
| Name | Institution |
|---|---|
| Chao Yu | Tsinghua University |
| Akash Velu | University of California, Berkeley |
| Eugene Vinitsky | University of California, Berkeley |
| Jiaxuan Gao | Tsinghua University |
| Yu Wang | Tsinghua University |
| Alexandre Bayen | University of California, Berkeley |
| Yi Wu | Tsinghua University,Shanghai Qi Zhi Institute |
1.3 发表情况
36th Conference on Neural Information Processing Systems (NeurIPS 2022) Track on Datasets and Benchmarks.
第 36 届神经信息处理系统会议 (NeurIPS 2022) 跟踪数据集和基准。
🌟人工智能领域-CCF A类会议,顶会🌟
1.4 摘要
Proximal Policy Optimization (PPO) is a ubiquitous on-policy reinforcement learning algorithm but is significantly less utilized than off-policy learning algorithms in multi-agent settings. This is often due to the belief that PPO is significantly less sample efficient than off-policy methods in multi-agent systems. In this work, we carefully study the performance of PPO in cooperative multi-agent settings. We show that PPO-based multi-agent algorithms achieve surprisingly strong performance in four popular multi-agent testbeds: the particle-world environments, the StarCraft multi-agent challenge, Google Research Football, and the Hanabi challenge, with minimal hyperparameter tuning and without any domain-specific algorithmic modifications or architectures. Importantly, compared to competitive off-policy methods, PPO often achieves competitive or superior results in both final returns and sample efficiency. Finally, through ablation studies, we analyze implementation and hyperparameter factors that are critical to PPO’s empirical performance, and give concrete practical suggestions regarding these factors. Our results show that when using these practices, simple PPO-based methods can be a strong baseline in cooperative multi-agent reinforcement learning. Source code is released at https://github.com/marlbenchmark/on-policy.
直译:
近似策略优化( PPO )是一种无处不在的在策略强化学习算法,但在多智能体环境中的应用明显少于非策略学习算法。这往往是由于在多智能体系统中,PPO的样本效率明显低于非策略方法。在这项工作中,我们仔细研究了PPO在协作多智能体环境中的性能。我们展示了基于PPO的多智能体算法在粒子世界环境、星际争霸多智能体挑战、谷歌研究足球和Hanabi挑战这4个流行的多智能体测试床上取得了出人意料的强性能,并且没有任何特定领域的算法修改或架构。重要的是,与竞争性的政策外方法相比,PPO往往在最终收益和样本效率上都取得了竞争性或更优越的结果。最后,通过消融研究,我们分析了对PPO实证表现至关重要的实现和超参数因素,并针对这些因素给出了具体的实践建议。我们的结果表明,在使用这些实践时,简单的基于PPO的方法可以成为合作多智能体强化学习中的强基线。源代码在https://github.com/marlbenchmark/on-policy.发布
二、研究背景
PPO算法本质是on-policy的算法,因其样本效率低的原因,在多智能体应用场景中使用率低于off-policy的算法。
三、存在问题
PPO算法在多智能体应用场景中使用率的缘由可归结于以下两点:
① PPO 的样本效率低于off-policy方法,因此在资源受限的环境中有用性较低;
② 在single agent设置中使用 PPO 时的超参数优化做法,在转移到multi-agent设置时通常不会产生强大的性能。
四、实施方法
4.1 预设
- 研究场景
研究的场景主要针对:“decentralized partially observable Markov decision processes (DEC-POMDP) with shared rewards”,即“基于共享奖励的部分可观测马尔可夫决策过程”。
DEC-POMDP可定义为七元组: ⟨ S , A , O , R , P , n , γ ⟩ \langle\mathcal{S},\mathcal{A},O,R,P,n,\gamma\rangle ⟨S,A,O,R,P,n,γ⟩
S {S} S:表示状态空间。
A {A} A:表示每个agent的共享动作空间。
o i = O ( s ; i ) o_i=O(s;i) oi=O(s;i):表示全局状态 S {S} S 下智能体 i {i} i 的局部观测值。
P ( s ′ ∣ s , A ) P(s^{\prime}|s,A) P(s′∣s,A):表示 n {n} n 个智能体联合动作 A = ( a 1 , … , a n ) A=(a_1,\ldots,a_n) A=(a1,…,an) 的从状态 s {s} s 到状态 s ′ {s^{\prime}} s′ 的转换概率。
γ \gamma γ:表示折扣率。
其中,智能体使用各自的参数化policy π θ ( a i ∣ o i ) \pi_{\theta}(a_{i}|o_{i}) πθ(ai∣oi) ,从局部观测值 o i {o_i} oi 产生动作 a i {a_i} ai。
优化目标为基于状态和联合动作的累计奖励值: J ( θ ) = E A t , s t [ ∑ t γ t R ( s t , A t ) ] J(\theta)=\mathbb{E}_{A^t,s^t}\left[\sum_t\gamma^tR(s^t,A^t)\right] J(θ)=EAt,st[∑tγtR(st,At)]
🌟从预设场景可以看出,该文献主要针对的是多智能体环境下的合作场景。
- 训练-执行架构
我们在多智能体设置中实现 PPO 与单代理设置中的 PPO 结构非常相似,通过学习策略
π
θ
{\pi_{\theta}}
πθ 和值函数
V
ϕ
(
s
)
V_{\phi}(s)
Vϕ(s);这些函数表示为两个单独的神经网络。
V
ϕ
(
s
)
V_{\phi}(s)
Vϕ(s) 用于方差减少,仅在训练期间使用;因此,它可以将智能体本地观测中不存在的额外全局信息作为输入。
从而允许多智能体域中的 PPO 遵循 CTDE:Centralized training and decentralized execution 结构。
4.2 两类PPO算法区别
为清楚起见,我们将具有 集中价值函数 输入的 PPO 称为 MAPPO (Multi-Agent PPO)。
将 策略和价值函数均具有本地输入 的 PPO 称为 IPPO (Independent PPO)。
4.3 实现细节
- 参数共享
在具有同质智能体的基准环境中(即智能体具有相同的观察和动作空间),我们利用参数共享;过去的工作表明,这提高了学习效率,这也与我们的实证发现一致。在这些设置中,代理共享policy和value函数参数。 - 广义优势估计(Generalized Advantage Estimation: GAE)
采用了实施 PPO 的常见做法,包括具有优势归一化和值剪辑的广义优势估计 (GAE)。
五、实验对比
进行了一项全面的实证研究,以检验 PPO 在四个流行的合作多智能体基准上的表现:多智能体粒子世界环境 (MPE) [22]、星际争霸多智能体挑战 (SMAC) [28]、谷歌研究足球 (GRF) [19] 和 Hanabi 挑战 [3]。
5.1 Baseline算法
基于下述多智能体仿真环境,以MAPPO与IPPO分别对比了off-policy的诸多算法;
| Environment | Baseline Algorithm(off-policy) |
|---|---|
| MPE | Qmix,MADDPG |
| SMAC | Qmix,Qplex,CWQMix,AIQMix,RODE |
| GRF | Qmix,CDS,TiKick |
| Hanabi | SAD,VDN |
5.2 设备情况
实验在具有 256 GB RAM、一个 64 核 CPU 和一个 GeForce RTX 3090 GPU 的台式机上执行,用于前向动作计算和训练更新。
5.3 主要结论
在大多数环境中,PPO 获得的结果优于或与非策略方法相当,样本效率相当。
5.4 实验结果
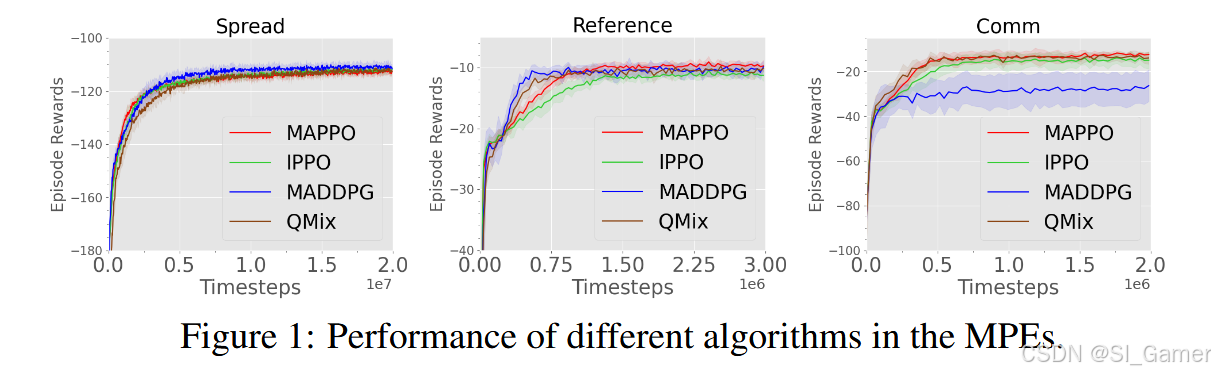
以MPE多智能体粒子环境为例,说明其实验配置与结果
- 实验配置
我们考虑了 [22] 中提出的三个合作任务:物理欺骗任务 (Spread)、简单参考任务 (Reference) 和合作通信任务 (Comm)。由于 MPE 环境不提供全局输入,我们遵循 [22] 并连接所有代理的局部观察以形成一个全局状态,该状态被 MAPPO 和非策略方法使用。此外,Comm 是唯一没有同质代理的任务;因此,我们不利用参数共享来完成此任务。所有结果均取 10 粒种子的平均值。
- 实验结果
每种算法在收敛时的性能如图 1 所示。MAPPO 的性能可与off-policy baseline相媲美,甚至优于off-policy baseline;我们特别看到 MAPPO 在所有任务上的性能都与 QMix 非常相似,并且在 Comm 任务中超过了 MADDPG 的性能,同时使用了相当数量的环境步骤。尽管没有利用全局信息,但 IPPO 也实现了与集中式非策略方法相似或更好的性能。与 MAPPO 相比,IPPO 在多种环境(Comm 和 Reference)中收敛到略低的最终回报。
六、结论影响
我们这项工作的目的不是提出一种新的 MARL 算法,而是实证证明,通过简单的修改,PPO 可以在各种协作多代理设置中实现强大的性能。我们还相信,我们的建议将帮助从业者通过 PPO 取得有竞争力的结果。
6.1 探索PPO算法在多智能体环境下的性能
• 我们证明 PPO 在没有任何特定领域的算法更改或架构的情况下,只需最少的调整,即可在四个多智能体合作基准上实现与非策略方法竞争的最终性能。
6.2 与off-policy算法进行性能对比
• 我们证明 PPO 在使用与许多非政策方法相当数量的样本时获得了这些强有力的结果。
6.3 分析PPO算法在多智能体场景下的超参数影响
• 我们确定并分析了在这些情况下控制 PPO 实际性能的五个超参数因素,并就有关这些因素的最佳实践提供了具体建议。
5项超参数包含:
value normalization, value function inputs, training data usage, policy/value clipping, and batch size.
值归一化、值函数输入、训练数据使用、策略/值裁剪和批量大小。
(1)value normalization
we standardize the targets of the value function by using running estimates of the average and standard deviation of the value targets.
通过使用价值目标的平均值和标准差的运行估计来标准化价值函数的目标。
Suggestion 1: Utilize value normalization to stabilize value learning.
建议 1:利用价值归一化来稳定价值学习。
(2)value function inputs
Suggestion 2: When available, include both local, agent-specific features and global features in the value function input. Also check that these features do not unnecessarily increase the input dimension.
建议 2:如果可用,请在值函数输入中同时包含特定于代理的本地特征和全局特征。还要检查这些功能是否不会不必要地增加 input 维度。
(3)training data usage
An important feature of PPO is the use of importance sampling for off-policy corrections, allowing sample reuse. [14] suggest splitting a large batch of collected samples into mini-batches and training for multiple epochs. In single-agent continuous control domains, the common practice is to split a large batch into about 32 or 64 mini-batches and train for tens of epochs. However, we find that in multi-agent domains, MAPPO’s performance degrades when samples are re-used too often.
PPO 的一个重要特点是使用重要性抽样进行非策略校正,从而允许样本重用。[14] 建议将一大批收集的样本分成小批量,并针对多个 epoch 进行训练。在单智能体连续控制域中,常见的做法是将一个大批次分成大约 32 或 64 个小批次,并训练数十个 epoch。然而,我们发现,在多智能体领域,当样本重复使用过于频繁时,MAPPO 的性能会下降。
Suggestion 3: Use at most 10 training epochs on difficult environments and 15 training epochs on easy environments. Additionally, avoid splitting data into mini-batches.
建议 3:在困难环境中最多使用 10 个训练 epoch,在简单环境中最多使用 15 个训练 epoch。此外,请避免将数据拆分为小批量。
(4)policy/value clipping
Another core feature of PPO is the use of clipped importance ratio and value loss to prevent the policy and value functions from drastically changing between iterations. Clipping strength is controlled by the hyperparameter: large values allow for larger updates to the policy and value function. Similar to the number of training epochs, we hypothesize that policy and value clipping can limit the non-stationarity which is a result of the agents’ policies changing during training. For small , agents’ policies are likely to change less per update, which we posit improves overall learning stability at the potential expense of learning speed. In single-agent settings, a common value is 0.2
PPO 的另一个核心功能是使用裁剪的重要性比率和值损失来防止策略和值函数在迭代之间发生剧烈变化。剪切强度由 ε 超参数 控制:较大的 ε 值允许对 policy 和 value 函数进行更大的更新。 与训练时期的数量类似,我们假设策略和值裁剪可以限制非平稳性,这是智能体策略在训练期间发生变化的结果。
对于小的 ε 值,智能体的策略在每次更新时可能会更改较少,我们认为这可以提高整体学习稳定性,但可能会牺牲学习速度。
在单智能体设置中,常用值为 0.2 。
Suggestion 4: For the best PPO performance, maintain a clipping ratio under 0.2; within this range, tune as a trade-off between training stability and fast convergence.
建议 4: 为获得最佳 PPO 性能,请将剪切率保持在 0.2 以下;在此范围内,调整为训练稳定性和快速收敛之间的权衡。
(5)batch size
During training updates, PPO samples a batch of on-policy trajectories which are used to estimate the gradients for the policy and value function objectives. Since the number of mini-batches is fixed in our training (see Sec. 5.3), a larger batch generally will result in more accurate gradients, yielding better updates to the value functions and policies. However, the accumulation of the batch is constrained by the amount of available compute and memory: collecting a large set of trajectories requires extensive parallelism for efficiency and the batches need to be stored in GPU memory. Using an unnecessarily large batch-size can hence be wasteful in terms of required compute and sample-efficiency.
在训练更新期间,PPO 对一批策略轨迹进行采样,这些轨迹用于估计策略和价值函数目标的梯度。由于小batch的数量在我们的训练中是固定的(参见第 5.3 节),因此较大的batch-size通常会导致更准确的梯度,从而更好地更新值函数和策略。但是,批处理的累积受到可用计算和内存量的限制: 收集大量轨迹需要广泛的并行性以提高效率,并且批处理需要存储在 GPU 内存中。因此,使用不必要的大batch-size可能会在所需的计算和样本效率方面造成浪费。
Suggestion 5: Utilize a large batch size to achieve best task performance with MAPPO. Then, tune the batch size to optimize for sample-efficiency.
建议 5:利用大batch-size通过 MAPPO 实现最佳任务性能。然后,调整批次大小以优化样本效率。
七、其它说明
- 相关代码的实现可参考:https://github.com/marlbenchmark/on-policy
八、小结
- 该文献没有创造新的算法,只是验证了PPO算法进行简单的修改就能应用到MARL领域。
- 该文献的测试场景仅针对于【参数共享的同构多智能体协作环境】
- 实际代码应用时可以参考5项超参数调整的建议。


















 2141
2141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









