







VideoAgent: Long-form Video Understanding with Large Language Model as Agent(翻译)
摘要:长格式视频理解是计算机视觉领域的一个重大挑战,需要一个能够对长多模态序列进行推理的模型。受人类对长格式视频理解的认知过程的激励,我们强调交互式推理和计划,而不是处理长视觉输入的能力。我们介绍了一个新的基于智能体的系统,VideoAgent,它采用一个大型语言模型作为中央智能体,迭代地识别和编译关键信息来回答问题,视觉语言基础模型作为翻译和检索视觉信息的工具。在具有挑战性的EgoSchema和NExT-QA基准测试中,VideoAgent实现了54.1%和71.3%的零拍摄准确率,平均只使用8.4帧和8.2帧。这些结果表明,我们的方法比当前最先进的方法具有更高的有效性和效率,突出了基于智能体的方法在推进长格式视频理解方面的潜力。
1.Introduction(介绍)
在计算机视觉领域,理解从几分钟到几小时不等的长视频是一个重大挑战。这项任务需要一个能够处理多模态信息、处理超长序列并对这些序列进行有效推理的模型。
尽管有许多尝试通过增强这些能力来应对这一挑战,但现有模型很难同时在这三个领域脱颖而出。目前的大型语言模型(llm)擅长推理和处理长上下文,但它们缺乏处理视觉信息的能力。相反,视觉语言模型(VLMs)很难对冗长的视觉输入进行建模。早期的努力已经实现了vlm的长上下文建模能力,但是这些适应在视频理解基准中表现不佳,并且在处理长格式视频内容方面效率低下。
我们真的需要将整个长视频直接输入模型吗?这与人类如何完成长格式视频理解任务有很大的不同。当被要求理解一段长视频时,人类通常依靠以下互动过程来制定答案:这个过程首先是对视频的快速概述,以了解其背景。随后,根据手头的具体问题,人类迭代地选择新的框架来收集相关信息。当获得足够的信息来回答问题时,迭代过程结束,并给出答案。在整个过程中,控制迭代过程的推理能力比直接处理冗长的视觉输入的能力更为关键。
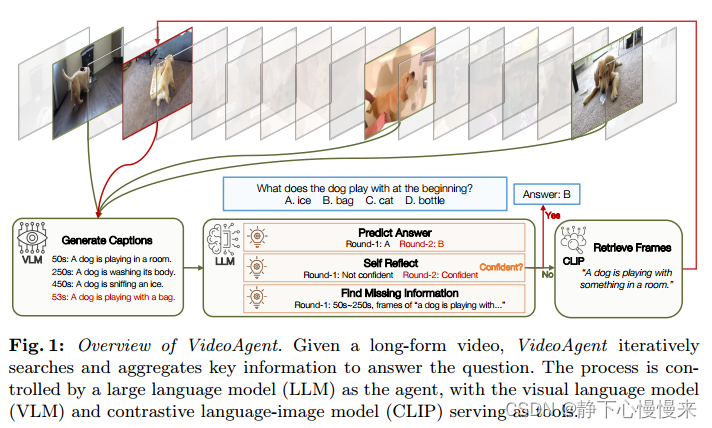
从人类如何理解长视频中获得灵感,我们提出了VideoAgent,这是一个通过基于代理的系统模拟这一过程的系统。我们将视频理解过程表述为一系列状态、动作和观察,其中LLM作为控制该过程的代理(Fig 1)。最初,LLM通过浏览视频中的一组均匀采样帧来熟悉视频上下文。在每次迭代中,LLM评估当前信息(状态)是否足以回答问题;如果没有,则确定需要哪些附加信息(操作)。随后,它利用CLIP检索包含该信息(观察)的新帧,并利用VLM将这些新帧标题为文本描述,更新当前状态。该设计强调推理能力和迭代过程,而不是直接处理长视觉输入,其中VLM和CLIP作为工具性工具,使LLM具有视觉理解和长上下文检索能力。
我们的工作与以往的工作有两个不同之处。相比于统一采样帧或单次迭代选择帧的工作,我们的方法采用多轮方式选择帧,保证了信息的准确性,根据当前的需要收集更准确的数据。与使用原始问题作为查询检索帧的工作相比,我们重写了查询以实现更准确和细粒度的帧检索。
我们对两个成熟的长格式视频理解基准EgoSchema和NExT-QA进行了严格的评估,证明了与现有方法相比,VideoAgent具有卓越的有效性和效率。VideoAgent在这两个基准上分别达到了54.1%和71.3%的准确率,比并发最先进的方法LLoVi分别高出3.8%和3.6%。值得注意的是,VideoAgent平均只使用8.4帧来实现这样的性能,比LLoVi少20倍。我们的消融研究强调了迭代帧选择过程的重要性,该过程根据视频的复杂性自适应地搜索和聚合相关信息。此外,我们的案例研究表明,VideoAgent可以泛化到任意长的视频,包括延长到一个小时或更长时间的视频。
总之,VideoAgent代表了长格式视频理解的重要一步,它包含了基于代理的系统来模拟人类的认知过程,并强调了推理在长上下文视觉信息建模中的首要地位。我们希望我们的工作不仅为长格式视频的理解设定了一个新的基准,而且为这一方向的未来研究指明了方向。
2. Related Work(相关工作)
2.1 Long-form Video Understanding(长格式视频理解)
由于其固有的复杂性和时空输入的高维性,长格式视频理解是计算机视觉中一个特别具有挑战性的领域,这导致了巨大的计算需求。长格式视频理解方法需要平衡计算效率和性能,可以大致分为选择性或压缩稀疏性策略。
压缩稀疏度方法试图用尽可能小的维数将视频压缩成有意义的嵌入/表示。例如,MovieChat采用了一种内存整合机制,该机制基于余弦相似性合并相似的相邻帧令牌,有效地减少了长视频序列中的令牌冗余。Chat-UniVi利用kNN聚类对视频令牌进行时空压缩。然而,压缩不需要发生在嵌入本身,并且可以压缩成时空图甚至文本。例如,Zhang等人引入了LLoVi,并表明在视频之前简单地添加字幕,并用这些字幕提示LLM可以作为一个强大的基线。
与此同时,选择性压缩方法试图将视频分成更有意义的帧,利用输入的问题/文本作为指导,实际上试图只对与手头问题相关的帧进行采样。例如,R-VLM和R2A等方法利用CLIP模型在给定文本提示的情况下检索相关帧.
2.2 LLM Agents
代理被定义为在动态、实时环境中做出决策并采取行动以实现某些特定目标的实体。大型语言模型(llm)的进步,特别是其新兴的推理和规划能力,激发了最近自然语言处理的研究,以利用它们作为现实场景中的代理。这些模型已经在各种场景中取得了巨大的成功,例如在线搜索、纸牌游戏和数据库管理。通过思维链推理或自我反思等方法可以进一步增强其有效性。
同时,计算机视觉界已经开始在不同的视觉环境中探索基于llmas -agent的方法,如GUI理解和机器人导航。在长格式视频理解领域,一些研究已经初步尝试了类似代理的方法,利用llm与外部工具进行交互或合并额外的功能。与这些方法不同,我们的工作将视频理解重新定义为决策过程,这是受到人类如何解决视频解释方法的启发。我们把视频看作是一个环境,在这个环境中,我们要么寻求更多的信息,要么结束互动。这一观点指导了VideoAgent的创建,这是一个新颖的框架,通过强调视频理解中固有的决策方面,与现有的方法有很大的不同。
3.Method(方法)
在本节中,我们将介绍VideoAgent的方法。VideoAgent的灵感来自于人类理解长视频的认知过程。给定一个视频对于问题,人类首先浏览几个帧来了解其上下文,然后迭代搜索其他帧以获得足够的信息来回答问题,最后汇总所有信息并做出预测。
我们将过程表述为一系列状态、动作和观察{(st, at, ot)|1≤t≤t},其中状态是所有看到的帧的现有信息,动作是回答问题还是继续搜索新帧,观察是当前迭代中看到的新帧,t是最大迭代次数。
我们利用大型语言模型(LLM) GPT-4作为代理来执行上述过程(图1)。LLM已被证明具有记忆、推理和规划以及工具使用能力,可分别用于对状态、动作和观察进行建模。
3.1 Obtaining the Initial State(获取初始状态)
为了开始迭代过程,我们首先让LLM熟悉视频的背景,这可以通过浏览从视频中均匀采样的N帧来实现。由于LLM没有视觉理解的能力,我们利用视觉语言模型(vlm)将视觉内容转换为语言描述。具体来说,我们用“详细描述图像”的提示为这N帧配上标题,并将标题提供给LLM。这个初始状态s1记录了视频内容和语义的草图。
3.2 Determining the Next Action(决定下一步行动)
给定存储所有已见帧信息的当前状态st,下一个动作有两种可能的选择:
动作1:回答问题。如果状态st中的信息足以回答问题,我们应该回答问题并退出迭代过程。
动作2:搜索新信息。如果st中的当前信息是不够的,我们应该决定需要什么进一步的信息来回答这个问题,并继续寻找它。
为了在行动1和行动2之间做出决定,我们需要LLM对问题和现有信息进行推理。这可以通过三个步骤来实现。首先,我们通过思维链提示迫使LLM基于当前状态和问题做出预测。其次,我们要求LLM根据步骤1生成的状态、问题、预测及其推理过程进行自我反思并生成一个置信度分数。置信分数有三个级别:1(不充分信息),2(部分信息)和3(充分信息)。最后,我们根据置信度评分选择行动1或2。这个过程如fig2所示。我们建议使用三步过程,而不是单步过程,直接选择动作,因为直接预测总是决定搜索新信息。这种自我反思过程的动机是,它在自然语言处理中已经证明了优越的有效性。
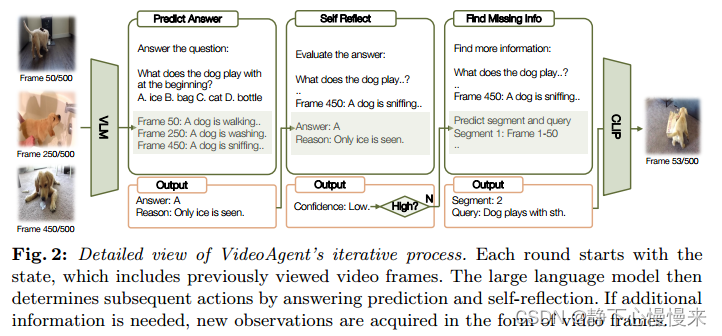
3.3 Gathering a New Observation(收集新的观察结果)
假设LLM确定没有足够的信息来回答问题,并选择搜索新的信息。在这种情况下,我们进一步要求LLM决定需要哪些额外的信息,以便我们可以利用工具来检索它们(图2)。由于一些信息可能在视频中多次出现,我们执行片段级检索而不是视频级检索,以增强时间推理能力。例如,假设问题是“男孩离开房间后沙发上的玩具是什么?”,并且我们看到男孩在第i帧时离开了房间。如果我们检索查询“一帧显示沙发上的玩具”,那么在第i帧之前可能存在包含“沙发上的玩具”的帧,但它们与回答问题无关。
为了执行片段级检索,我们首先根据看到的帧索引将视频分成不同的片段,并要求LLM预测要用查询文本检索哪些片段。例如,如果我们看到了视频的第i帧、第j帧和第k帧,一个有效的预测是区段2(第i帧到第j帧),查询是“一帧显示沙发上的玩具”。
我们利用CLIP来获得LLM给出的输出的附加信息。具体来说,给定每个查询和段,我们返回与该段中的文本查询具有最高余弦相似性的图像帧。这些检索到的帧被用作更新状态的观察值。
由于几个原因,与使用LLM或VLM相比,在检索步骤中使用CLIP计算效率很高,可以忽略不计。首先,CLIP的特征计算只涉及一个单一的前馈过程。其次,CLIP采用图像-文本后期交互架构,实现了跨不同文本查询的图像帧特征的缓存和重用。最后,我们的段级检索设计只需要计算特定段内的特征,进一步提高了效率。经验表明,CLIP的计算量不到VLM和LLM的1%。
3.4 Updating the Current State(更新当前状态)
最后,给定新的观测值(即检索到的帧),我们利用vlm为每帧生成标题,然后简单地根据帧索引将新标题与旧帧标题排序并连接起来,并要求LLM生成下一轮预测。
人们可能会提出的一个问题是,为什么我们利用多轮过程,因为一些现有的作品使用所有或均匀采样帧作为单个步骤中的状态。与这些基线相比,我们的方法有许多优点。首先,使用过多的帧会引入大量的信息和噪声,这会导致性能下降,因为llm受到长上下文的影响,很容易分心。此外,由于LLM上下文长度的限制,它的计算效率很低,很难扩展到一小时长的视频。相反,使用过少的帧可能无法捕获相关信息。我们的自适应选择策略找到最相关的信息,并以最低的成本回答不同难度的问题。
我们将VideoAgent概括为算法1。

4.Experiments(实验)
在本节中,我们首先介绍数据集和实现细节,然后介绍VideoAgent的结果、分析、消融和案例研究。
4.1 Datasets and Metrics(数据集和指标)
在我们的实验中,我们使用两个不同的成熟数据集来测试我们模型的性能,特别关注零射击理解能力。
EgoSchema。EgoSchema是一个长视频理解的基准,包含5000个选择题,来自5000个以自我为中心的视频。这些视频提供了一种以自我为中心的观点,即人类从事各种各样的活动。该数据集的一个显著特征是其视频的长度,每个视频持续3分钟。EgoSchema只包含一个测试集,其中500个问题的子集具有公开可用的标签。全套问题将在官方排行榜上进行评估。
NExT-QA。NExT-QA数据集包括5440个以日常生活中的物体交互为特征的自然视频,以及48000个选择题。视频的平均长度为44秒。这些问题分为三类:时间、因果和描述性,为视频理解模型提供了全面的评估。与标准做法一致,我们的零射击评估集中在验证集上,该集包含570个视频和5000个选择题。我们还遵循[4]来报告NExT-QA验证集的atp硬子集的性能。这个子集保留了无法用一个框架解决的最难的QA对,更多地关注于长期时间推理。
由于每个数据集都有选择题,我们使用准确性作为评估指标。
4.2 Implementation Details(实现细节)
我们以1 fps的速度解码实验中的所有视频,并使用EVA-CLIP-8Bplus根据生成的视觉描述与帧特征之间的余弦相似度检索最相关的帧。在EgoSchema的实验中,我们使用了LaViLa作为标题,这是一个基于剪辑的标题模型。接下来,为了确保零镜头评估,我们利用在ego4D数据上重新训练的LaViLa模型,用EgoSchema过滤掉重叠的视频。我们根据剪辑检索模块返回的帧索引对视频剪辑进行采样,以便添加字幕。对于NExT-QA,我们使用CogAgent作为标题。我们使用GPT-4作为所有实验的LLM, GPT的版本固定为GPT-4 -1106-preview,以保证可重复性。
4.3 Comparison with State-of-the-arts(比较)
VideoAgent设定了新的基准,在EgoSchema和NExT-QA数据集上实现了最先进(SOTA)的结果,大大超过了以前的方法,同时只需要最少的帧数进行分析。
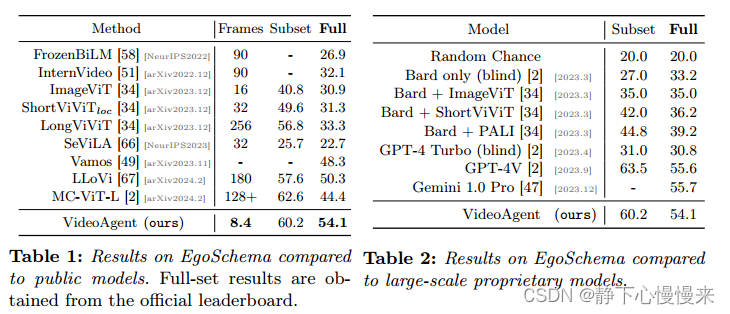
EgoSchema。如表1和表2所示,VideoAgent在EgoSchema完整数据集上实现了54.1%的准确率,在500个问题的子集上实现了60.2%的准确率。完整数据集的准确性是通过将我们的模型预测上传到官方排行榜来验证的,因为地面真相标签是不可公开的。这些结果不仅显著优于以前的SOTA方法LLoVi[67] 3.8%,而且与先进的专有模型(如Gemini-1.0)的性能相当。值得注意的是,我们的方法只需要平均值每个视频8.4帧-与现有方法相比,显着减少了2倍到30倍。
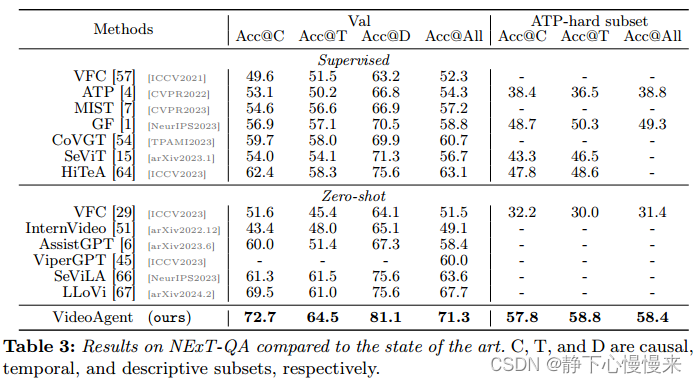
 NExT-QA。在表3中,我们展示了VideoAgent在NExT-QA完整验证集上达到了71.3%的准确率,比之前的SOTA LLoVi高出3.6%。平均每个视频仅使用8.2帧进行零镜头评估,VideoAgent在所有子集(包括那些测试模型的因果关系、时间和描述能力的子集)上始终优于以前的监督和零镜头方法。重要的是,VideoAgent在更具挑战性的子集ATPhard上取得了显著的性能改进[4],证明了它在处理复杂的长格式视频查询方面的熟练程度。
NExT-QA。在表3中,我们展示了VideoAgent在NExT-QA完整验证集上达到了71.3%的准确率,比之前的SOTA LLoVi高出3.6%。平均每个视频仅使用8.2帧进行零镜头评估,VideoAgent在所有子集(包括那些测试模型的因果关系、时间和描述能力的子集)上始终优于以前的监督和零镜头方法。重要的是,VideoAgent在更具挑战性的子集ATPhard上取得了显著的性能改进[4],证明了它在处理复杂的长格式视频查询方面的熟练程度。
这些结果强调了VideoAgent在处理和理解长视频中的复杂问题方面的卓越效果和效率。















 32
32

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









