







简介
Life是一个基于pytorch实现的强化学习库,实现了多种强化学习算法。
项目地址:https://github.com/HanggeAi/Life
目前包含的强化学习算法
- Sarsa
- multi-Sarsa
- Q-Learning
- Dyna-Q
- DQN
- Double-DQN
- Dueling-DQN
- REINFORCE策略梯度
- Actor-Critic
- PPO
- DDPG
- SAC
- BC
- GAIL
- CQL
主要特征
- 基于目前主流的深度学习框架pytorch,支持gpu加速。
- 覆盖面广,从传统的QLearning,到一些最新的强化学习算法都有实现。
- 封装程度低,支持自定义结构的深度神经网络。
- 简洁易用,仅需寥寥几行代码,即可实现强化学习算法的构建与训练。
结构
图解Life的结构

Life将强化学习算法分为以下几类:
- 传统的强化学习算法,如Sarsa;
- 只基于值函数的深度强化学习算法,如DQN;
- 基于策略函数和值函数的深度强化学习算法,如AC;
- 模仿强化学习算法,如BC;
- 离线强化学习算法,如CQL。
对于每一类强化学习算法,都配有一个训练器
训练器的名称和算法的名称是一一对应的,如要训练DQN,则其训练函数的名称为:
train_dqn
以DQN为例,其结构如下
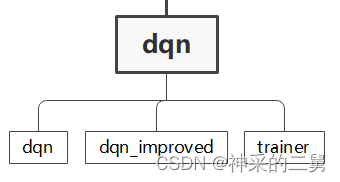
其中:
- dqn.py中为传统DQN算法
- dqn_improved.py中为一些改进的DQN算法
- trainer中包含了以上各种dqn算法的训练函数
Get Started
要使用Life进行强化学习,仅需简单的三步,下面以DQN在CartPole环境上的训练为例进行快速入门:
第一步,导入相关的模块
from life.dqn.dqn import DQN # 导入模型
from life.dqn.trainer import train_dqn # 导入训练器
from life.envs.dis_env_demo import make # 环境的一个例子
from life.utils.replay.replay_buffer import ReplayBuffer # 回放池
import torch
import matplotlib.pyplot as plt
第二步,设置超参数,并构建模型
# 设置超参数
lr = 2e-3
num_episodes = 500
hidden_dim = 128
gamma = 0.98
epsilon = 0.01
target_update = 10
buffer_size = 10000
minimal_size = 500
batch_size = 64
device = torch.device("cpu") # 也可指定为gpu : torch.device("cuda")
env=make() # 建立环境,这里为 CartPole-v0
replay_buffer = ReplayBuffer(buffer_size) # 回放池
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 建立模型
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device) # DQN模型
注意,如果你足够细心,你会发现在上述建立DQN的过程中,我们没有传入一个Neural Network,这是因为在建立深度强化学习时,Life提供了一个默认的双层神经网络作为建立DQN的默认神经网络。当然,你也可以使用自己设计的神经网络结构:
class YourNet:
"""your network for your task"""
pass
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device, q_net=YourNet) # DQN模型
第三步,使用训练器训练模型
result=train_dqn(agent,env,replay_buffer,minimal_size,batch_size,num_episodes)
上述训练函数返回的是:训练过程中每个回合的汇报,如果你想的话,可以将其可视化出来:
episodes_list = list(range(len(result)))
plt.figure(figsize=(8,6))
plt.plot(episodes_list, result)
plt.xlabel("Episodes")
plt.ylabel("Returns")
plt.title("DQN on {}".format("Cart Pole v1"))
plt.show()
得到:

当然,如果你需要智能体的话,也可以设置return_agent=True,这会返回一个元组(return_list, agent)
其中,return_list为:训练过程中每个回合的汇报,agent为训练好的智能体。
return_agent默认为False
可见,除了超参数的设置之外,我们构建DQN算法只使用了两行代码:
from life.dqn.dqn import DQN
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,target_update, device)
我们训练DQN同样只使用了两行代码:
from life.dqn.trainer import train_dqn
result=train_dqn(agent,env,replay_buffer,minimal_size,batch_size,num_episodes)
这让我们的强化学习实现的相当简洁和方便!
上述的例子在项目的examples中
关于名称与LOGO
- Life的中文含义为:生命,生活,强化学习本来就是人生的一个过程,我们无时无刻不在进行着强化学习。强化学习不仅是一种科学的决策方法,各种算法的思想也给予我们很多人生的哲理,使人受益匪浅。
- LOGO 底色采用深蓝色,图案和文字采用浅蓝白色,整体端庄严谨,富有科技感。文字部分由项目名称LIFE字样和寄语:RL IS THE PROCESS OF LIFE 即可以理解为强化学习是人生的过程,也可以理解为强化学习是Life库的程序,一语双关。
- LOGO图案部分为4个伸长了的F,同时将F上面一个笔画伸长,使其左旋90°时形成L字样,为LIFE的简写LF; 同时致敬OpenAI的LOGO.















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









