







Bert
一、基础框架
1.1 核心
在大量无标记数据 集上训练 Transformer 的 Encoders 来做 NLU (语言理解),得到优秀的特征抽取模型。(最终的模型参数即代表模型学习到的 ” 语言理解能力(特征抽取能力)“ )。
然后根据下游任务微调(fine-tune)模型即可。
1.2 结构
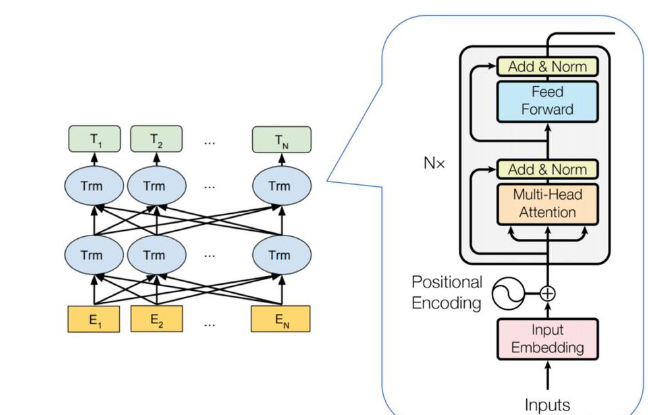
1.3 背景
-
参考了 ELMO 的双向编码 (考虑上下文)思想;
-
参考了 GPT 用 Transformer 作为特征提取器 的思路;
-
(推测)参考了 word2vec 所使用的 CBOW (完形填空)方法;
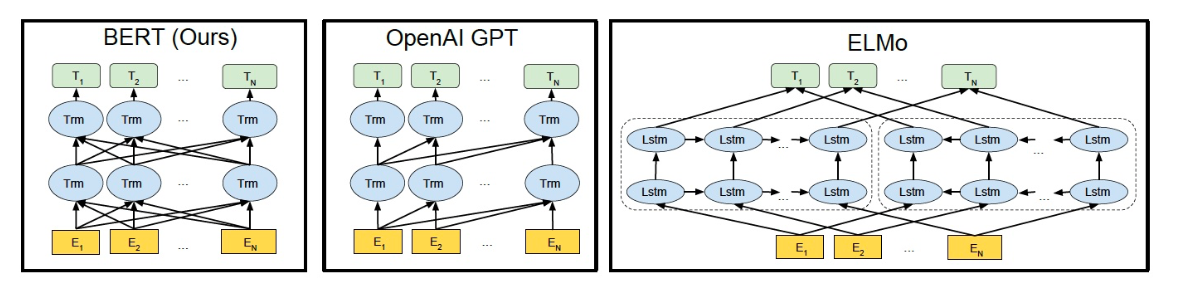
1.4 改进
-
ELMo 前向、后向两个 LSTM 网络, 本质上还是 浅层单向编码,只不过是两个方向上的单向编码的拼接而成的双向编码。
-
Bert 用 Attention 做双向 编码,(推测)综合上下文信息更强。
-
相较于 2 层 LSTM 的 ELMo,多层 Trm 的 Bert 能学到更多更深层的特征信息。
-
仅需 Fine tune( 如加入一层网络 )即可适应多种下游 任务,不用专门训练特定模型。
1.5 BERT 和 GPT 之间的区别:
-
GPT:用 Transformer Decoder 作为特征提取器、具有良好的文本生成能力, 然而单向编码 当前词的语义只能由其上文决定,且在语义理解上不足。 GPT 输出生成结果。
-
BERT:用 Transformer Encoder 作为特征提取器,并使用了配套的 MASK 训练 方法。 虽然使用双向编码 让 BERT 不再具有文本生成能力,但是 BERT 的语义信息提取能力更强。 Bert 输出优秀的特征表示。
1.6 流程
-
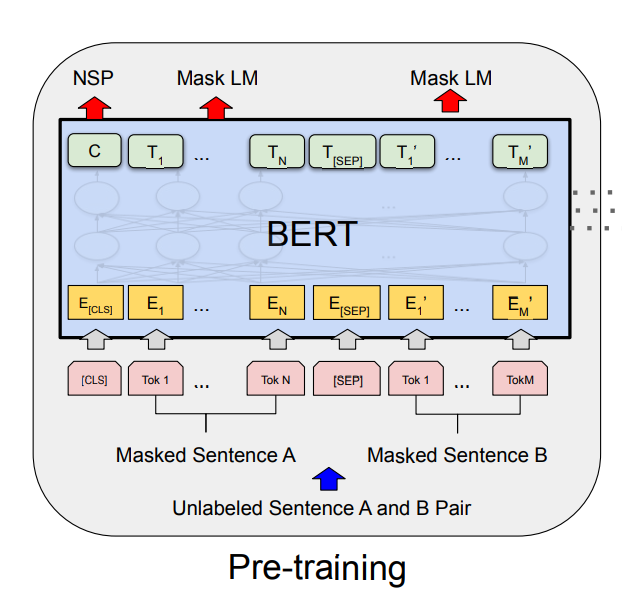
pre-training: 在无标记的数据集 A 上训练 LM 模型。
-
fine-tuning: 用 LM 的参数初始化 Bert 模型, 然后在有标记的数据集 B 上训练解决下游任务(如问答、分类),此时 Bert 所有参数可学习 (fine-tuned)。
(原论文指出)除了 输出层,其余 pre-training 和 fine-tuning 部分结构一样。相同的 pre-trained 模型参数可以用来初始化解决不同下游任务的 模型。在 fine-tuning 阶段,所有参数都是可学习的 (fine-tuned)。
1.7 参数
BERT_{BASE}:L = 12,H = 768,A = 12,总参数量为 1.1 亿
BERT_{LARGE}:L = 24,H = 1024,A = 16,总参数量为 3.4 亿
L:代表 Transformer Block 的层数; H:代表特征向量的维数(此处默认 Feed Forward 层中的中间隐层的维数为 4H); A:表示 Self-Attention 的头数,使用这三个参数基本可以定义 BERT的量级。
(由于参数多、模型大,若训练数据太少,容易过拟合。)
二、Feature-based & Fine tune
NNLM 的 两种训练策略;
2.1 Feature - based(如 ELMo):
核心:训练模型,输出 Feature(特征:LM embedding),将 Feature 输入(特定)模型来做特定任务
利用预训练的 NNLM 的结果也就是 LM embedding,将其作为额外的特征, 引入到原任务的模型(task-specific model)中。
过程:
-
首先在大的语料 A 上训练语言模型 LM_A 。
-
然后构造 task-specific model 例如序列标注模型,语料 B 的训练数据经过 LM_A(参数固定) 得到 LM embedding,作为 task-specific model 的输入(额外特征),有监督的训练 task-sepcific model。
2.2 Fine tune:
核心:无标记训练模型,有标记微调参数,用该模型来解决特定任务。(如 GPT,Bert)
在训练好的 NNLM 的基础上,加入少量的 task-specific parameters。
例如对于分类问题在语言模型基础上加一层softmax网络,然后在新的语料上重新训练来进行 fine-tune。
过程:
-
首先在大的无标记语料 A 上训练语言模型 LM_A 。
-
在 LM_A 上增加少量神经网络层来完成 specific task 例如序列标注、分类等, 采用语料B来有监督地训练 LM_A,这个过程中 LM_A 的参数不固定,可学习。
三、Input/Output Representations
(原论文指出) 为了让 BERT 处理不同的下游任务,BERT 的输入 ( input representations) 应该能 用一个 Token 序列来清晰无争议的表示 单个句子 或 句子对。
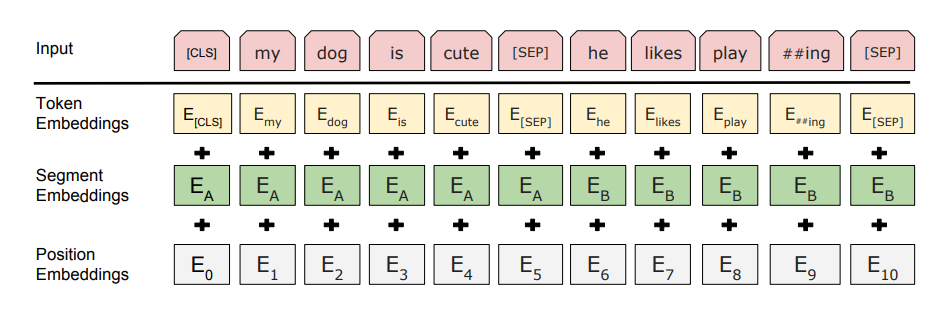
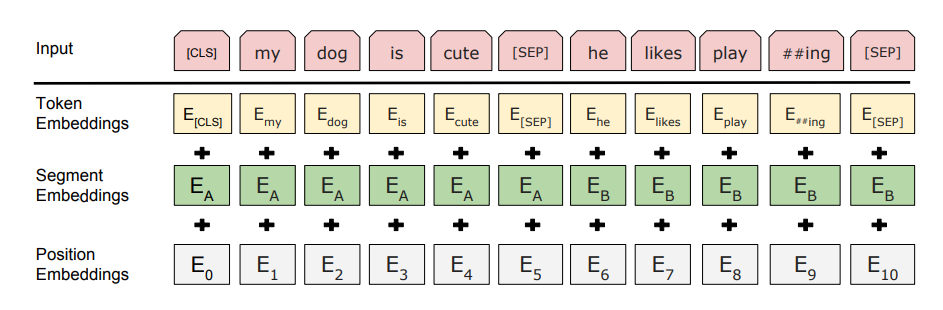
3.1 [CLS]( classification token )
BERT 在每一句前会加一个 [CLS] 标志, 经过最后一层 Trm 该位对应向量可以作为 整句话的语义表示,从而用于下游的分类任务等。
原理: BERT 的特征提取器 Trm 原理是 Multi-Head Self-Attention,即用文本中的其他词来增强目标词的语义表示,但是该特征表示中目标词自身的语义会占主要部分(“存在私心”)。
而 [CLS] 位本身没有语义,经过 Trm 后得到句中所有词的加权平均。 相比其他句中词,最终的 [CLS] 可以更好的表征句子语义 (“公平无私”)。
( 也可以通过对最后一层所有词的 embedding 做 pooling 去表征句子语义。)
3.2 [SEP] ( seperate token )
用于分开两个输入句子,例如输入句子 A 和 B,要在句子 A,B 间增加 [SEP] 标志。
(除此,BERT 给每个 Token 加上 Segment Embeddings 来表示该 Token 属于 A 还是 B。)
3.3 Input Representation
对于每一个 Token,它的 BERT 输入表示为:
Input Representation = Token Embeddings + Segment Embeddings + Position Embeddings
(相较于 Transformer 的 Encoders,Bert 的输入表示多了 Segment Embeddings。
文本在 Token Embeddings 前需要 Tokenization , 采用 WordPiece,会将词继续拆分(解决词的不同时态问题)。
另外,[CLS] 和 [SEP] 也会被加入 Token 序列。
-
Token Embeddings( Token 的向量表示):
将各个词转换成固定维度的向量(如 768 维)。
假设输入文本是 “I like strawberries”,Token Embeddings流程 如下:
-
I like strawberries (3 words) -
"[CLS]","I","like","straw","##berries","[SEP]" (6 tokens) -
6*768 token embeddings
Token Embeddings 层会将每一个 token 转换成768维的向量。这样,例子中的6个token就被转换成了一个(6, 768) 的矩阵或者是(1, 6, 768)的张量(如果考虑batch_size)。
-
-
Segment Embeddings(区分 Token 在哪一个句子):
用于区分一个 token 属于句子对中的哪个句子。Segment Embeddings 层只有两种向量表示。
前一个向量是把0赋给第一个句子中的各个token,后一个向量是把1赋给第二个句子中的各个token。
( 如果输入仅仅只有一个句子,那么它的 Segment Embeddings 就是全0 。)
-
Position Embeddings(引入 Token 的位置信息):
不同于 Transformer 中的 PE。(详见 Transformer)
BERT 的 PE 是在预训练过程中得到的,类似于 word embedding 的 Q 矩阵。
(经过 PE 后,同样的词在不同的位置会有不同的表示。)
注意:3种 embedding 都是768维的,
最后要将其按元素相加,得到每一个 token 最终的768维的 input representation 向量表示。
四、Pre-training BERT
使用两个无监督的任务来预训练 BERT

4.1 Task1: Masked Language Model(MLM)
背景:
标准语言模型(LM)只能 从左到右 或 从右到左 训练。因为双向条件会使模型间接看到 “目标词” 。且在多层
上下文环境中,模型预测目标词的难度非常低,难以达到好的训练效果。(作业太简单,模型达不到学习效果。)
于是,BERT 借鉴完形填空(CBOW)的思想,使用语言掩码模型(MLM )方法训练模型。
( 注意:在CBOW 模型中,每个词都会被预测一遍。)
方法:
随机 mask (遮住)句子中的部分 token(单词),然后模型来预测 被遮住的 token 是什么。
BERT 在 Train 时,每一个句子中随机 mask 15% 的词。
缺陷:
在 fine-tune 时 或 test 时,输入的文本中将没有做 [MASK],train 和 test 的数据偏差导致模型效果变差。
解决方案:
由于潜在解决方案:1. train 时不做 mask 或者 2. test 时做 mask 都不可行。
故采用如下方法减少数据偏差,提高模型学习性能。(注意:不能完全解决 mask 导致的偏差。)
在随机选择 15% 的词作为掩码词后:
-
80% 概率:将选中的词用 [MASK] 来代替;
作用:训练模型预测未知词的能力,使模型更深层的理解语义。
-
10% 概率:选中的词不发生变化;
作用:训练模型 ”认识正确词“ 的能力,避免模型误判。
-
10% 概率:选中的词用任意的词来代替;
作用:训练模型利用上下文信息纠错的能力,使模型更深刻学习上下文,能判断噪声。
效果:
综上,由于由于有 未知的信息、正确的信息、错误的信息,且模型不知道信息的位置和类别。
故模型只能深刻学习 全局 token 的最佳表示,且要深刻的学习上下文信息并嵌入 token。
MLM 训练方法让 BERT 有极强的理解语义能力,远超同期选手,但复杂的训练也很大降低了训练效率。
4.2 Task2: Next Sentence Prediction (NSP)
背景:
NLP 中很多下游任务需要基于句子做逻辑推理(如问答),而 LM 并不具备直接捕获句子之间的语义联系的能力,或者可以说成 单词粒度的训练到不了句子关系这个层级。
为了学会抽取句子之间的语义联系,BERT 采用了 NSP (下句预测)作为无监督预训练的一部分。
方法:
BERT 输入的语句将由一个句子对构成。其中,50% 的概率是 语义连贯的两个句子(连续句对一般选自篇章级别的语料,以此确保前后语句的语义强相关),另外 50% 的概率是完全随机抽取的两个句子。
连续句对:[CLS]今天天气很糟糕[SEP]下午的体育课取消了[SEP] 随机句对:[CLS]今天天气很糟糕[SEP]鱼快被烤焦啦[SEP]
[CLS] 表示标签用于类别预测,结果为 1,表示输入为连续句对;结果为 0,表示输入为随机句对。
模型将在训练中学习对句子关系的理解,加强模型抽取句子语义的能力。
BERT 模型通过对 MLM 和 NSP 进行联合训练,使模型能准确抽取输入文本(单句或语句对)的整体信息,从而输出尽可能准确、全面地 字/词 向量表示。
4.3 Pre-training data
为了提取长的连续序列,使用文档级语料库而不是打乱的句子级语料库至关重要。
五、 Fine-tuning BERT
经过 pre-train 的 BERT 已经有优秀的特征抽取能力,能够很好的抽取文本的语义(字、句)。
此时经过简单的 fine-tuen 即可让 BERT 学会解决下游任务(如分类、问答等)
BERT 根据下游任务的输入和输出的形式,将 fine-tune 的任务分为四类:
-
句对分类;
-
单句分类;
-
文本问答;
-
单句标注;
5.1 句对分类
给定两个句子,判断它们的关系。(类似 NLP-beginner 3 文本匹配)
BERT 在 pre-training 时用 NSP 学习了抽取句对语义关系的能力。
如下图所示,句对用 [SEP] 分隔符拼接成文本序列。在句首加入 [CLS],所对应的输出值作为分类标签。 计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
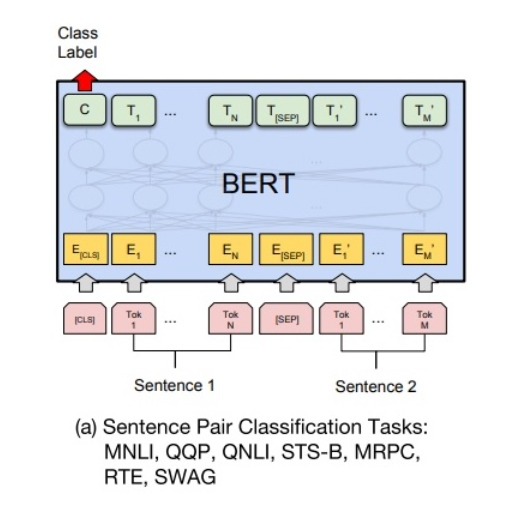
针对二分类任务,BERT 不需要对输入数据和输出数据的结构做任何改动,直接使用与 NSP 训练方法一样的输入和输出结构就行。
针对多分类 任务,需要在 [CLS] 的输出特征向量 后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 arg max 操作(取最大值时对应的索引序号)得到相对应的类别结果。
5.2 单句分类
给定一个句子,判断该句子的类别。(类似 NLP-beginner 1、2 文本分类)
如下图所示,句首加入 [CLS],对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
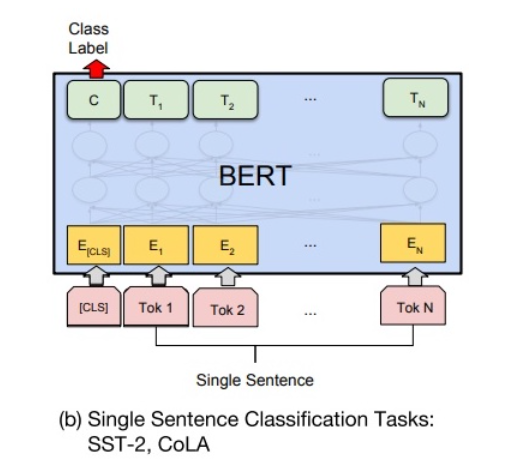
单句二分类,也无须改动 输入、输出结构。
单句多分类,需要在 [CLS] 的输出特征向量 后接一个全连接层和 Softmax 层,后用 argmax 取得分类结果。
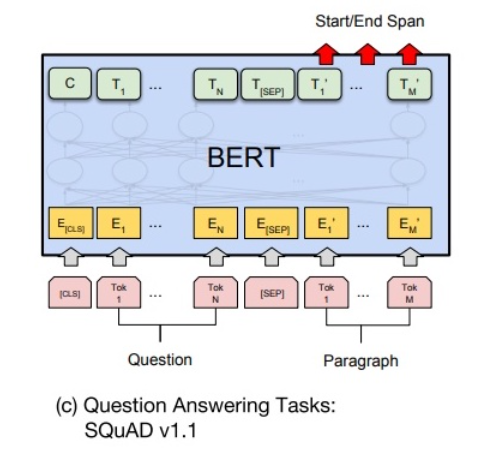
5.3 文本问答
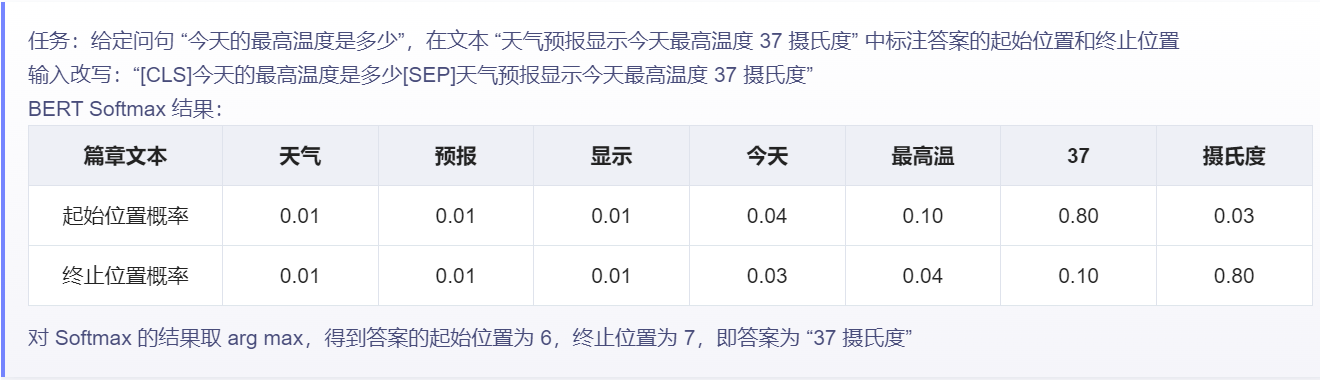
给定问题(句子 A),在给定的段落(句子 B)中标注答案的 起始位置 和 终止位置。(与其它任务差别较大)
引入两个辅助向量 s(start,答案的起始位置) 和 e(end,答案的终止位置)。
如下图所示,BERT 将句子 B 中的每一个 token 得到的最终特征向量 T_i 经过全连接层(利用全连接层将词的抽象语义特征转化为任务指向的特征)后,分别与向量 s 和 e 求内积,对所有内积分别进行 softmax 操作,即可得到词 作为答案其实位置和终止位置的概率。最后,argmax 取概率最大的片段作为最终的答案。
从位置 i 到位置 j 的 score 定义:S \cdot T_i + E \cdot T_i
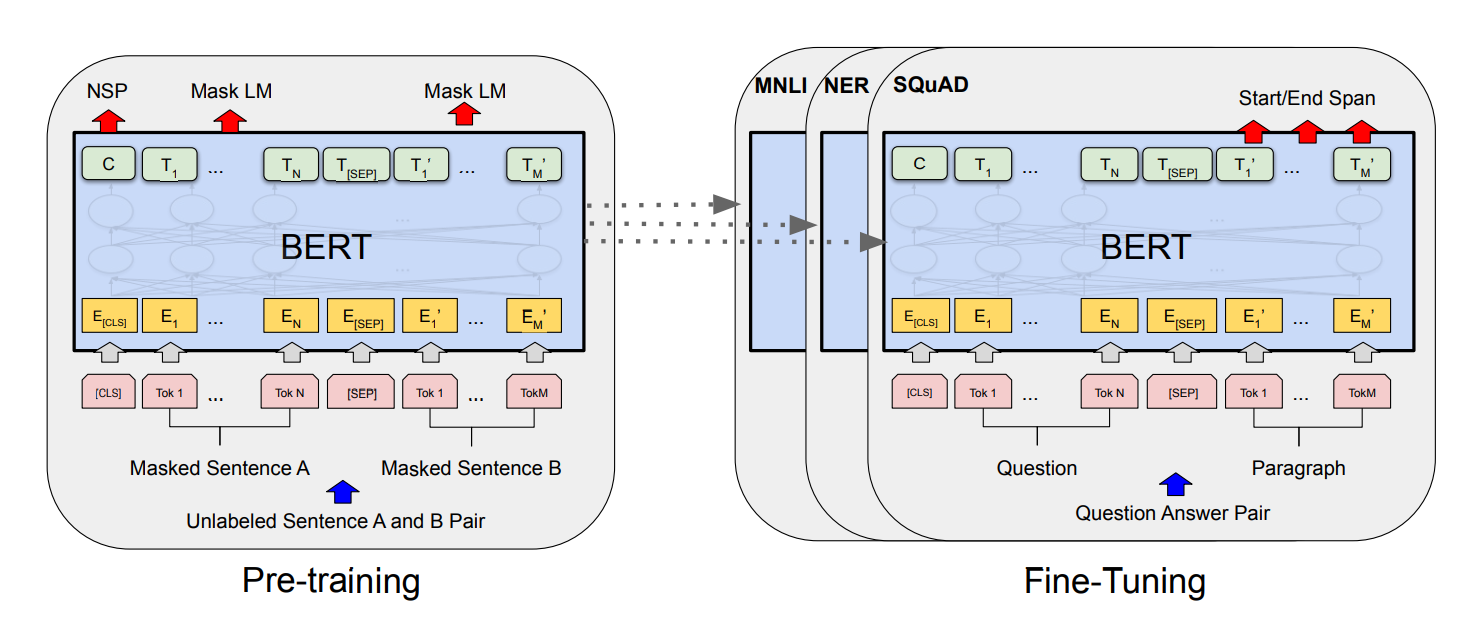
5.4 单句标注
给定一个句子,标注每个次的标签,称为单句标注。如 NER。(类似 NLP-beginner 4 序列标注)
如下图所示,在每个词的最终语义特征向量 T_i 之后添加全连接层,将 T_i 转化为序列标注任务所需的特征,然后对结果做 Softmax 操作,即可得到各类标签的概率分布。
(类似 NLP-beginner 4,可加入 CRF 约束,使得标注更准确。)
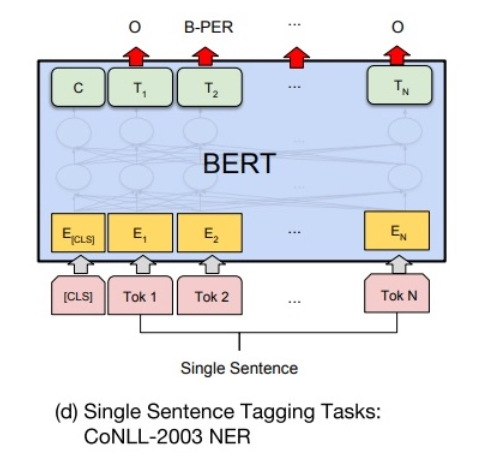
由于 BERT 需要对输入文本进行 WordPieces,独立词将会被分成若干子词,因此 BERT 预测的结果将会是 5 类(细分为 13 小类)
六、损失函数
BERT 原论文用的 loss 是 结合 MLM 和 NSP 阶段的平均似然估计。
七、总结
7.1 回顾
花了两天多学习了 Bert 的原理细节。学习完 Transformer 后趁热打铁的投入到 Bert 的学习,然而并没有像预想的那般通顺。
因为 BERT 并不是想象中 Encoders 的简单堆叠,BERT 中出现了许多值得学习的新概念。
首先,BERT 继承了许多前辈的优秀理念,如 ELMo 的双向编码,CBOW 的 ”完形填空“,GPT 的 Trm 抽取等。
我想比较重要的应该有:
-
采用 Trm 的 Encoders 做特征抽取;
-
双向 Attention 编码综合上下文;
-
[CLS] ”大公无私“ 的集合了整句的语义特征;
-
MLM 使模型在复杂的条件下不得不更深刻的理解每一词的语义;
学习 BERT 时也学习了许多有意思的相关知识,如 feature-based & fine-tune,ar & ae,WordPieces... 平常单独学习概念时会好奇它们背景和作用,而在一个大模型理念中学习种种小细节往往能体会到它们的精妙: 人们不是凭空的想到这些精妙的细节,而往往经历了 出现问题 --》尝试改进 --》测试效果 --》完善模型 等一系列完整解决问题的思路和步骤 。
作为一个入门者,希望自己不仅学习到技术本身,也能学到发现问题、思考对策、尝试改进的创新思维。
学习 BERT 的 fine-tune 时惊讶的发现,在做过的 NLP-beginner 中,要解决类似任务需要单独设计一个模型,而在 BERT 中却只需要 fine-tune 即可,且 BERT 往往能更优秀的解决。果然,有时跳出固定思维和范式才能找到全面提升的办法。
当然,有得必有失,强大的 BERT 有众多的参数和复杂耗时的训练过程。一定程度上影响了大家对 BERT 之类模型的研究、测试、改进。难怪许多人感慨,money / GPU is all you need !
不过技术总是在不断进步的,相信用不了多久,更多好用且易用的模型会惊喜出现。
7.2 向前
BERT 在各种 NLP 子领域的 ”屠榜“ 式成功 和 学术上的高引用,让 BERT 的光芒在很长一段时间遮盖住了 GPT,许多人认为 BERT 的双向 Encoders 要比 GPT 的 单向 Decoders 更加有效。
但偏执的 OpenAI 坚定不移的推进 GPT 发展,近来效果炸裂的 ChatGPT 和 即将问世的 GPT-4 让人们看到了 OpenAI ”偏执“ 的回报。通往 AGI 的道路似乎愈加光明。
下一步,GPT!















 3159
3159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









