







6.1 归一化(Normalization)
把所有数据都转化成[0,1]或者[-1,1]之间的数,其目的是为了取消各维数据之间的数量级差别,避免因为输入输出数据数量级差别大而造成网络预测误差过大。
作用
- 方便后续数据处理。
- 运行时收敛速度更快。
- 统一量纲。统一评价标准,这算是应用层面的需求。
- 避免梯度消失。
- 保证输出数据中数值小的不被吞食。
类型
-
线性归一化,也称为 最小 - 最大规范化,离散标准化。
对原始数据的线性变换,将数据值映射到 [0,1] 之间。
-
零 - 均值 归一化,也称为 Z - score 标准化
经过处理的数据符合标准正态分布,即均值为0,标准差为1,这里的关键在于复合标准正态分布。
-
小数定标规范化
这种方法通过移动属性值的小数数位,将属性值映射到 [-1,1] 之间,移动的小数位数取决于属性值绝对值的最大值。
-
非线性归一化
这个方法包括 log,指数,正切。
适用范围:经常用在数据分析比较大的场景,有些数值很大,有些很小,将原始值进行映射。
6.2 目标
尽可能让原始数据变为独立同分布的数据
- 可以简化模型的训练,加快训练速度。
- 提升模型的预测能力,提高模型性能。
(ICS)Internal Covariate Shift——内部变量偏移
深度学习包含很多隐层的网络结构,在训练过程中,各层参数不停在变化,每一层的参数更新都会导致上层的输入数据在输出时分布规律发生了变化,并且这个差异会随着网络深度增大而增大。
可能会导致:
- 降低学习速度
- 梯度消失
6.3 Batch Normalization & Layer Normalization
BN 把每层神经网络任意神经元 越来越偏的输入值的分布强行拉回到均值为0方差为1的标准正态分布。这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。LN 也是同样的以不同的方式来达到相似的效果。
BN & LN 可以:
- 避免梯度消失
- 加快训练速度
Batch Normalization 是对 一批(一个 batch 内)样本的同一纬度 特征做归一化。
在 NLP 中相当于对 一个 batch 内的 所有句子同一位置的词 做归一化
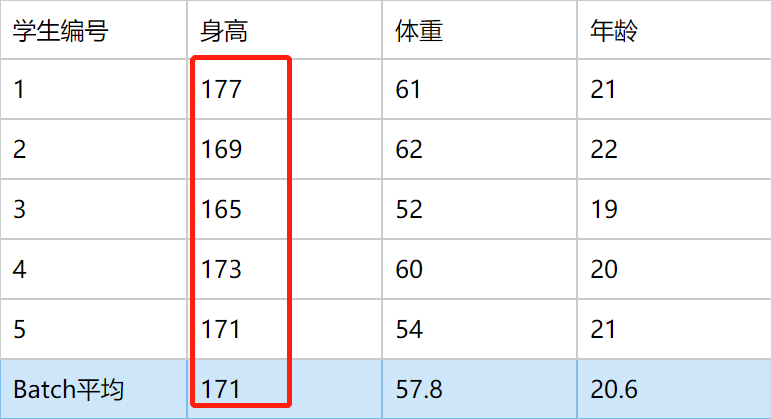
Layer Normalization 是对 单个样本的所有维度 特征做归一化。
在 NLP 中相当于对 一个 batch 内的 每个句子内所有位置的词 做归一化

6.4 BN 和 LN 的关系
- BN 和 LN 都可以比较好的抑制梯度消失和梯度爆炸的情况。
- BN不适合RNN、transformer等序列网络,不适合文本长度不定和 batch_size 较小的情况,适合于CV中的CNN等网络。
- LN适合用于NLP中的RNN、transformer等网络,因为sequence的长度可能是不一致的。
!!! 如果把一批文本组成一个batch,BN就是对 batch 中每句话的同一位置的词进行操作,BN针对每个位置进行缩放就不符合NLP的规律了。而 LN是对每一句 句子中的所有词 进行操作。















 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









