







语言表示模型 BERT 详解
摘要:在自然语言处理(NLP)领域,BERT(Bidirectional Encoder Representations from Transformers)是近几年出现的、影响深远的创新模型之一。自 2018 年由谷歌团队发布以来,BERT 为众多 NLP 任务设定了新的基准。BERT旨在通过在所有层中对左右上下文进行联合条件反射,从未标记的文本中预训练深度双向表示。因此,预训练的BERT模型可以通过一个额外的输出层进行微调,从而为广泛的任务(如问答和语言推理)创建最先进的模型,而无需对特定于任务的架构进行大量修改。本文将详细介绍 BERT 的原理、结构、训练过程,以及它在各种 NLP 任务上的表现。
1. BERT 简介
技术背景:BERT的出现是基于深度学习在自然语言处理(NLP)领域的快速发展。在BERT之前,已经有许多预训练语言模型,如ELMo和GPT,它们展示了预训练模型在NLP任务中的强大性能。然而,这些模型通常基于单向的上下文信息,即只考虑文本中的前向或后向信息,这限制了它们对文本的全局理解。BERT旨在通过引入双向上下文信息来解决这一问题,从而更准确地表示文本中的语义信息。
BERT 是一种基于 Transformer 架构的双向语言表示模型。它通过对海量文本数据的预训练,学习得到丰富的上下文表示,然后在下游任务上进行微调,实现极高的性能。
1.1 BERT 与传统模型的对比:
BERT 被开发为一个深层双向模型,它能够从输入序列的最初层一直到输出层有效地捕捉到目标单词周围的全方位上下文信息。在传统的方法中,我们通常要么建立语言模型来预测句子中接下来的词(类似于 GPT 使用的单向右到左的模型),要么建立模型来从左到右预测。这种方法可能因为上下文信息的不完整而导致模型出错。
与传统的单向语言模型相比,BERT 的核心优势在于:
双向性:BERT通过使用Transformer的编码器结构,BERT 能够同时从文本的左右两个方向学习上下文信息,使模型能够更好地理解句子中的每个词的语义。
预训练与微调:通过预训练任务(如 Masked Language Model 和 Next Sentence Prediction),BERT 可以在多种下游任务上进行快速微调。
1.2 论文及开源资源
BERT 的原始论文是《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。
论文地址:
https://arxiv.org/abs/1810.04805
GitHub 项目地址:
GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
Google AI Blog :
Open Sourcing BERT:State-of-the-Art Pre-training for Natural Language Processing
地址:
https://link.zhihu.com/?target=https%3A//ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
2. BERT 结构详解
BERT 的结构基于 Transformer 编码器(Encoder)部分。完整的 BERT 模型包括一个词嵌入层、多层的 Transformer 编码器,以及用于特定任务的输出层。
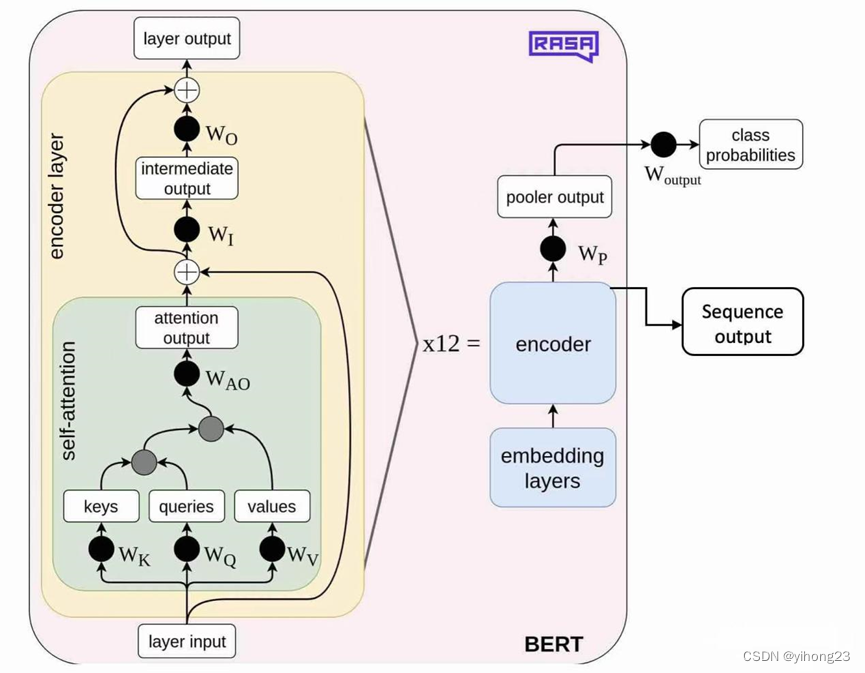
2.1 输入表示:

BERT 使用三种嵌入向量的组合作为输入表示:
1.Token Embedding(词嵌入):这部分是将输入文本中的每个词转换为固定大小的向量。通常,这是通过查找预先训练的嵌入表(embedding table)来实现的,其中每个词都与一个多维空间中的点相对应。
2.Segment Embedding(片段嵌入):BERT 能够处理多种任务,包括单句分类和句子对任务(如问答和自然语言推理)。为了区分句子对中的两个不同句子,BERT引入了段落嵌入。例如,在处理句子对时,第一个句子的每个词会附加一个"A"的段落嵌入,第二个句子的每个词会附加一个"B"的段落嵌入。
3.Position Embedding(位置嵌入):由于BERT基于的Transformer架构不是循环的,它本身不具备处理序列数据的能力。因此,为了让模型能理解词语在句子中的顺序,BERT加入了位置嵌入。位置嵌入是预先训练好的,可以编码每个位置的信息,并添加到词嵌入中,从而使模型能够理解文本的顺序信息。
将这三种嵌入相加,BERT就能为每个输入词生成一个综合表示,这个表示同时蕴含了词本身的含义、它在句子中的角色(例如,属于哪个句子)以及它在句子中的位置信息。这种综合表示是输入到BERT模型后续层(即多层Transformer编码器)的基础,用于进一步的特征提取和学习。
2.2 Transformer 编码器
BERT模型的中间层和transformer的encoder一样,都是由self-attention layer + ADD&BatchNorm layer + FFN 层组成的:
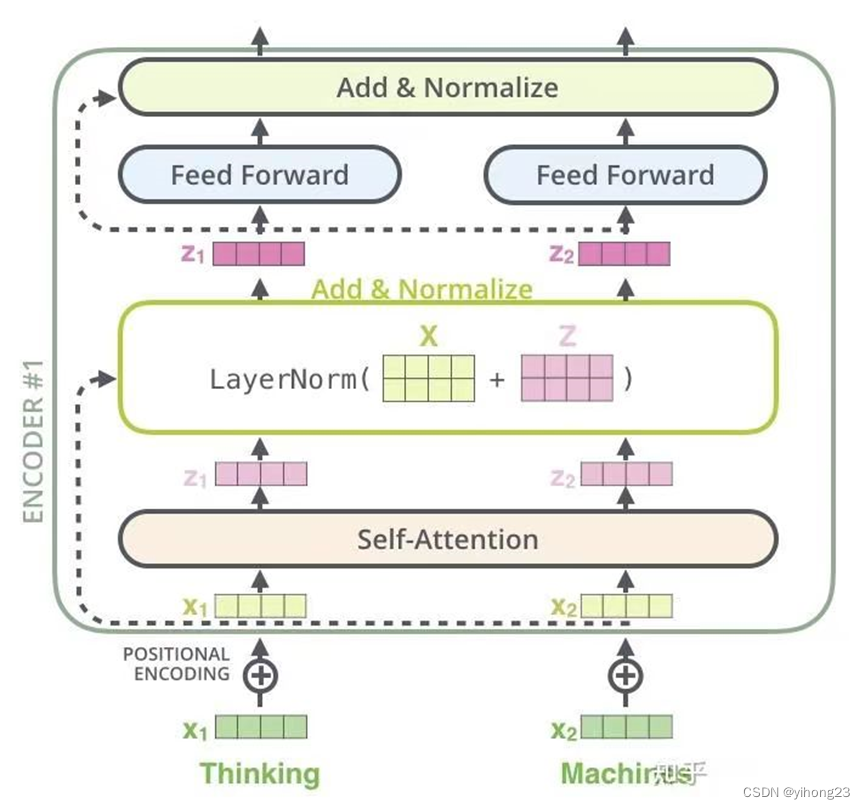
BERT 的核心部分是由多个堆叠的 Transformer 编码器组成。每个编码器包括:
1.多头自注意力机制(Multi-Head Self-Attention) 自注意力是 Transformer 的核心,使模型能够对输入序列中不同位置的数据进行权衡和处理,以捕捉词与词之间的关系,无论它们在文本中的距离有多远。自注意力机制可以并行处理所有位置的信息,这是其效率高的一个重要原因。
- 查询(Query)、键(Key)、值(Value):每个词通过线性层转换生成三组向量:查询向量、键向量和值向量。自注意力通过计算查询向量与所有键向量的点积来确定每个词对序列中其他词的影响程度(即注意力权重)。
- 注意力权重:这些权重通过 softmax 函数进行归一化,确保它们的总和为 1,表示概率分布。
- 输出:通过加权求和所有值向量(根据计算出的注意力权重)来产生每个位置的输出向量。
2.前馈神经网络(Feed-Forward Neural Network) 在每个自注意力层之后,有一个前馈神经网络,这是一个简单的全连接网络,对每个位置的输出向量独立地进行相同的操作。这种设计增强了模型的非线性能力,使模型能够更好地捕捉复杂的数据模式。
- 线性变换:首先,通过一个线性层扩展维度(例如,BERT base 使用的维度扩展到 3072),然后是一个激活函数(如 ReLU)。
- 第二个线性变换:然后再将扩展后的输出通过另一个线性层压缩回原始维度(例如,768维)。
3.层归一化和残差连接:每个子层(自注意力和前馈网络)的输出都通过一个残差连接,然后进行层归一化。残差连接帮助避免在深层网络中训练过程中出现的梯度消失问题,而层归一化则有助于稳定网络的学习过程。
2.3 输出层
在多数情况下,BERT 模型会根据具体的下游任务添加一个输出层。这个输出层的结构会根据任务的不同而不同。例如,在文本分类任务中,输出层可能是一个简单的 softmax 分类器,用于预测输入文本的类别。在问答任务中,输出层可能是一个生成起始和结束位置的 softmax 分类器。在命名实体识别等序列标注任务中,输出层通常采用条件随机场(CRF)等模型结构。这一层的目的是将 BERT 编码器的输出映射到特定任务的输出空间,并且根据任务的不同进行适当的损失计算和参数优化。
根据不同任务的需求,BERT 有不同的输出层设计:
1.分类任务:对于文本分类等任务,BERT 可以使用特殊的 [CLS] 标记的输出作为整个句子的表示,然后连接一个全连接层(通常是一个 softmax 层),以预测文本所属的类别。这种方法可以将整个句子的语义信息编码到 [CLS] 标记的向量中,并将其用于分类。
2.序列标注任务:对于词性标注、命名实体识别等序列标注任务,BERT 可以直接在每个词的输出上添加一个全连接层(通常是一个 softmax 层),以预测每个词的标签。在这种情况下,每个词的输出都可以被用来预测该词的标签,从而完成序列标注任务。
3.问答系统:对于问答任务,例如阅读理解中的抽取式问答(如 SQuAD 任务),BERT 可以采用一种特殊的输出层设计,结合起始位置和结束位置的预测。通常,BERT 在预测起始位置和结束位置时,会在每个位置上连接一个全连接层(通常是 softmax 层),以预测答案的起始和结束位置。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









