






大模型在游戏开发领域扮演了重要角色,从AI机器人生成到场景搭建覆盖各个领域。但在游戏场景理解、图像识别、内容描述方面很差。
为了解决这些难题,加拿大阿尔伯塔的研究人员专门开源了一款针对游戏领域的大模型VideoGameBunny(以下简称“VGB”)。
VGB可以作为视觉AI助理,能够理解游戏环境并提供实时反馈。例如,在探索型的3A游戏中,可以帮助玩家识别关键物品或进行问答,帮助玩家能够更快地掌握游戏技巧,从而增强游戏的互动性和沉浸感。
VGB也可以通过分析大量的游戏图像数据,够检测到图形渲染的错误、物理引擎的不一致性等,帮助开发人员快速识别和修复游戏中的bug和异常。
开源地址:https://huggingface.co/VideoGameBunny/VideoGameBunny-V1/tree/main

VGB是基于Bunny模型(高性能低消耗版本)基础之上开发而成,这个模型的设计方法类似于LLaVA,采用多层感知器网络作为投影层,将来自强预训练视觉模型的视觉嵌入转化为图像标记,供语言模型处理,可有效利用了预训练的视觉和语言模型使它们能够高效地协同处理数据。
Bunny模型支持最高1152×1152像素的图像分辨率,这在处理视频游戏图像时非常重要,因为游戏画面通常包含从UI图标到大型物体等不同尺寸的视觉元素。多尺度特征的提取有助于模型捕捉这些元素,从而提高对游戏内容的理解能力。
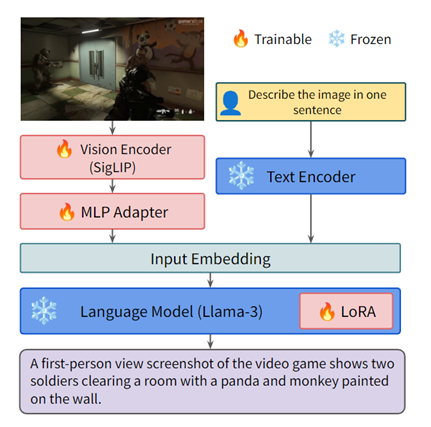
为了使VGB能够更好地理解和处理游戏的视觉内容,研究人员使用了Meta开源的LLama-3-8B作为语言模型,并结合了SigLIP视觉编码器以及S2包装器。这种多尺度特征提取方法能够捕捉游戏中不同尺度的视觉元素,从微小的用户界面图标到大型游戏对象,从而为模型提供了丰富的上下文信息。
此外,为了生成和游戏图像相匹配的指令数据,研究人员使用了多种先进的模型,包括Gemini-1.0-Pro-Vision、GPT-4V、GPT-4o等,以生成不同类型的指令。这些指令包括简短的标题、详细的标题、图像到JSON的描述以及基于图像的问答等,可以帮助模型更好地理解和响应玩家的查询和命令。
在模型训练方面,VGB使用了比较流行的LoRA参数高效微调方法,允许模型在保持预训练权重的同时,对特定任务进行微调,从而在不显著增加计算成本的情况下提高模型的性能。此外,研究团队还使用了PEFT库来指导模型的训练过程,进一步提升了训练的高效性和稳定性。
训练数据方面,研究人员收集了来自413款不同游戏的超过185,000多张图像以及将近39万个图像-指令对,涵盖了图像说明、问答对以及136,974张图像的JSON表示。

JSON格式的数据包含了16个元素,能够捕捉图像的多层次细节信息,包括整体概述、具体的人物描述、天气信息、用户界面和玩家库存的摘要、场景中的物体、照明和环境效果等。
为了创建图像到JSON的数据集,研究团队使用Gemini-1.5-Pro结合特定的指示,将给定的图像转换成一个具有层次结构细节和信息的JSON文件。
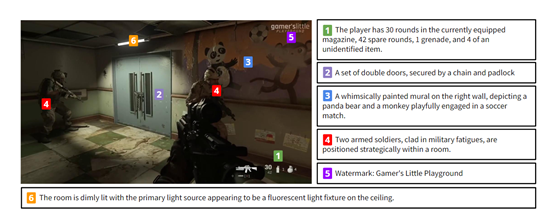
研究人员认为,全球游戏市场总额超过3000亿美元,在游戏开发、性能测试、提升游戏体验等方面对大模型有着巨大需求,VGB是可以辅助开发人员以及玩家达到这些目的。
本文素材来源VGB论文,如有侵权请联系删除


















 126
126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









