







工具:VS Code
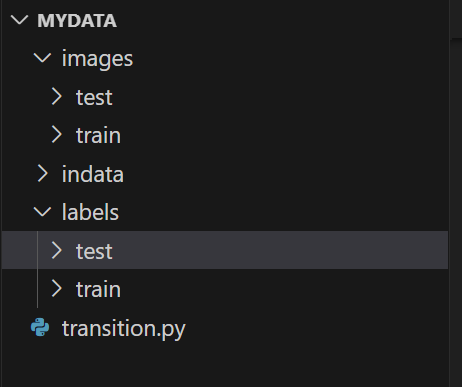
在使用YOLO算法时,数据集如果使用的是xml标注文件时,需要将xml格式转换为txt格式,首先需要新建五个文件夹,以及一个transition.py文件,文件夹之间的关系如下图:注意images文件夹里面的test和train文件夹提前放入使用的测试集和训练集图片,indata文件夹要放入所有要转化的xml文件
下面的代码是我根据其他博主的方法以及自身的情况尝试并且成功的一段代码,这段代码要放在transition.py文件里~
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir , getcwd
from os.path import join
import glob
classes = ["car"]#注意:这里要输入自己使用的数据集的类别classes,若有多个,中间用逗号分隔,查找classes的方法可以见我的另一篇博客https://blog.csdn.net/weixin_57425565/article/details/135949087?spm=1001.2014.3001.5501
def convert(size, box):
dw = 1.0/size[0]
dh = 1.0/size[1]
x = (box[0]+box[1])/2.0
y = (box[2]+box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_name):
in_file = open('./indata/'+image_name[:-3]+'xml') #这里输入自己原来的xml文件路径:我是放在了mydata文件夹下面的indata文件夹,用的是相对路径
out_file = open('./labels/train/'+image_name[:-3]+'txt', 'w') #这里是images文件夹下面的train文件夹中的图片对应的xml文件转换后的txt文件存放路径:我是放在了labels文件夹下面的train文件夹,要转换test文件夹对应的xml文件,这里要将train改成test
f = open('./indata/'+image_name[:-3]+'xml')
xml_text = f.read()
root = ET.fromstring(xml_text)
f.close()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if __name__ == '__main__':
for image_path in glob.glob("./images/train/*.bmp"): #这里写xml文件对应的图片的路径,这个是转化train文件夹使用的路径,要转换test文件夹对应的xml文件,这里要将train改成test,再次运行即可
image_name = image_path.split('\\')[-1]
convert_annotation(image_name)
需要修改的地方我都写在注释里面了,大家看注释里面的修改即可
因为我也是新手,所以写了尽可能详细的傻瓜教程,方便回顾~
参考博主:https://blog.csdn.net/yxl_prm/article/details/119895511














 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









